Indexierung erklärt
TrendMiner verwendet einen Caching-Mechanismus (als Indexierung bezeichnet), um eine schnelle, interaktive Visualisierung und Analyse Ihrer Zeitreihendaten zu ermöglichen. Die Indexierung wird in allen Algorithmen verwendet: Suche, Diagnose, Monitoring und Vorhersage.
Wenn ein Benutzer zum ersten Mal auf einen Tag in einer TrendMiner-Installation zugreift (in der Regel durch Hinzufügen des Tags zur Liste der aktiven Tags), durchläuft das Tag einen Prozess der Indexierung. Sobald ein Tag vollständig indexiert wurde, steht dieser Index allen Benutzern innerhalb der TrendMiner-Installation zur Verfügung (unter Berücksichtigung der Datenzugriffsberechtigungen).
TrendMiner sorgt dafür, dass der Index auf dem neuesten Stand bleibt, indem es in regelmäßigen Abständen Daten an den Index anhängt, ohne dass Sie etwas tun müssen. So können Sie schnell auf aktuelle Daten für Analysen zugreifen.
Es gibt zwei wichtige, konfigurierbare Parameter im Zusammenhang mit der Indexierung:
Indexauflösung: bestimmt, wie detailliert Ihre Analyse sein wird.
Indexhorizont: Legt das früheste Datum fest, ab dem der Index erstellt wird.
Standardmäßig ist die Indexauflösung auf 1 Minute eingestellt. Der Standard-Indexhorizont hängt davon ab, wann TrendMiner installiert wurde:
Installationen ab 2026.R1: 1. Januar des Jahres drei Jahre vor dem Installationsjahr (z. B. 1. Januar 2023 für Installationen im Jahr 2026)
Frühere Installationen: 1. Januar 2015 (oder 1. Januar 2010 für Installationen vor 2019.R2)
Beide Parameter können vom TrendMiner-Administrator in ConfigHub geändert werden.
Anmerkung
Als Administrator von TrendMiner können Sie auf die Seite zur Indexübersicht zugreifen, um einen Überblick über alle indexierten Tags und ihren aktuellen Zustand zu erhalten.
Wie die Indexierung funktioniert
Die folgenden Abbildungen veranschaulichen den Prozess der Indexierung für ein analoges Tag und zeigen, wie sich die Auflösungseinstellung auf den erstellten Index auswirkt.
Im ersten Bild werden die in der Datenbank gespeicherten Originaldaten für einen Zeitraum von 1 Minute visualisiert. Jeder blaue Punkt steht für einen Wert der in der Datenbank gespeicherten Zeitreihe (dieser kann je nach Speichereinstellungen der Datenbank bereits komprimiert sein).
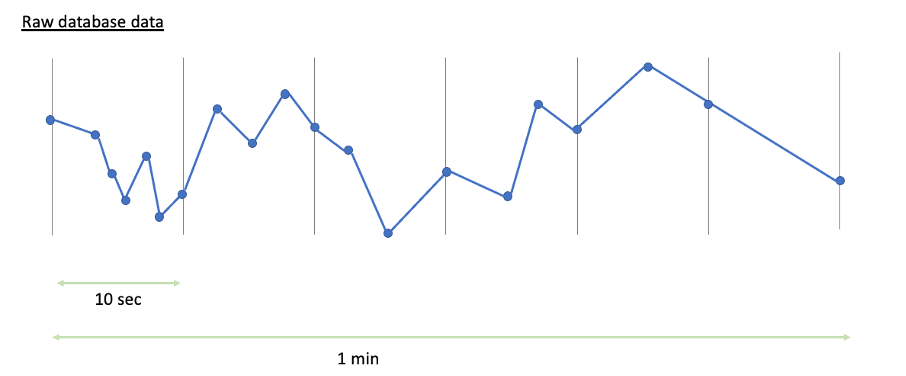
Die konfigurierte Indexauflösung legt fest, wie viele Datenpunkte TrendMiner von der Datenbank empfängt. Bei einer Auflösung von 10 Sekunden fordert TrendMiner Daten in Intervallen von 10 Sekunden an. Die Historian-Konnektoren von TrendMiner stellen sicher, dass Sie die wichtigsten Daten für diese Intervalle erhalten. Bei einem Aveva PI-Konnektor bedeutet dies, dass Sie potenziell 4 Datenpunkte pro Intervall erhalten (den Startwert, den Endwert, den Maximalwert und den Minimalwert innerhalb des Intervalls).
Die roten Punkte in den folgenden Abbildungen zeigen an, welche Daten letztendlich im Index von TrendMiner für eine Auflösung von 10 Sekunden (oben) und eine Auflösung von 1 Minute (unten) verfügbar wären.
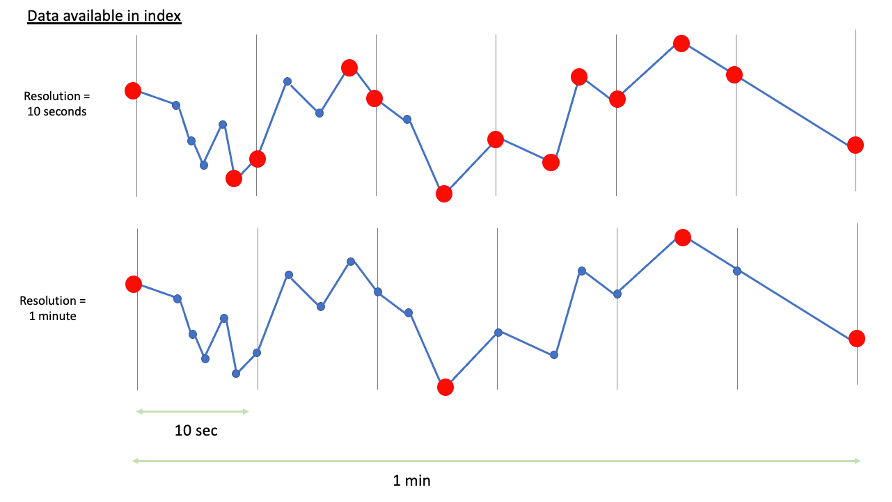
Sowohl die Leistung der zugrunde liegenden Datenbanken als auch die konfigurierte Indexauflösung beeinflussen die Geschwindigkeit der Indexierung. Eine höhere Indexauflösung bedeutet, dass die Datenbank mehr Datenpunkte überträgt, sodass der Prozess der Indexierung länger dauert. Die Festlegung einer Auflösung ist daher ein Kompromiss zwischen Datengranularität und Leistung.
Indexierungsrichtung und Priorität
Die erste Indexierung beginnt immer mit dem aktuellen Zeitpunkt und verläuft rückwärts bis zum konfigurierten Horizont (dies wird als rückwärtsgerichtete Indexierung bezeichnet). Wenn viele Tags gleichzeitig indexiert werden, haben die aktuellsten Daten immer Vorrang. Dadurch wird sichergestellt, dass Benutzer ihre Analyse sofort mit den aktuellen Daten beginnen können.
Als Benutzer können Sie den Prozess der Indexierung verfolgen, indem Sie den Zustand der Indexierung in den Tag-Details der Liste der aktiven Tags überprüfen oder indem Sie sich die Kontextleiste ansehen (die ausschließlich aus indexierten Daten erstellt wird).
Sobald Tags rückwärts indexiert sind, hält TrendMiner diese Indizes auf dem neuesten Stand (Vorwärtsindexierung), indem es in regelmäßigen Abständen Daten anhängt, ohne dass Sie eingreifen müssen.
Anmerkung
Als Administrator können Sie auf den Index-Manager zugreifen, um einen Überblick über alle indexierten Tags und deren aktuellen Zustand zu erhalten.
Der Index ermöglicht eine schnelle, interaktive Analyse Ihrer Daten und wird in allen Algorithmen verwendet.
Für Trenddiagramme (das Fokusdiagramm) werden Indexdaten verwendet, um eine schnelle Visualisierung langer Zeiträume zu ermöglichen – insbesondere dann, wenn der visualisierte Zeitraum mehr als das 300-fache der Indexauflösung beträgt (5 Stunden bei einer Indexauflösung von 1 Minute).
Für kürzere Zeiträume sind die Indexdaten möglicherweise zu ungenau, sodass die Daten direkt aus der Datenbank abgerufen werden, um eine möglichst genaue Darstellung zu gewährleisten. Die Daten werden auch direkt aus dem Historian abgerufen, wenn (noch) keine indexierten Daten verfügbar sind.
Die Suche wird ausschließlich auf indexierten Daten durchgeführt.
Die Mindestdauer eines Suchergebnisses hängt von der Indexauflösung und dem Suchalgorithmus ab:
Wertbasierte Suche, Digitale Stufensuche und Bereichssuche: Die Mindestdauer beträgt das Zweifache der Indexauflösung (2 Minuten bei einer Standardauflösung von 1 Minute). Bei kürzeren Zeiträumen kann TrendMiner die Suchkriterien nicht bewerten. Die Dauer der Suchergebnisse ist immer ein Vielfaches der Indexauflösung.
Ähnlichkeitssuche: Die Länge der Suchanfrage muss mindestens das Vierfache der Indexauflösung betragen. Zur Überprüfung der Ähnlichkeit werden nur indexierte Daten verwendet, was eine schnelle Analyse ermöglicht.
Für sehr kurze Zeiträume können die Ergebnisse der Ähnlichkeitssuche ungenau erscheinen. Der Suchalgorithmus findet Ergebnisse, bei denen die Indexdaten mit den Indexdaten des Abfragezeitraums übereinstimmen. Bei der Darstellung solcher kurzen Zeiträume ruft TrendMiner die Daten direkt aus dem Historian ab. Bei hochauflösenden Tags werden viel mehr Datenpunkte visualisiert als im Suchalgorithmus verwendet wurden, was die beobachteten Abweichungen erklären kann.
Die Fingerprint-Hülle wird ausschließlich aus den Diagrammdaten generiert, gemäß der im Abschnitt Diagrammerstellung erläuterten Logik. Die Fingerprint-Auswertung (in Monitore und dem Tool für Fingerprint-Abweichungen) verwendet die Indexdaten der zu analysierenden Tags.
Der Index aller berechneten Tags wird erstellt, indem Berechnungen auf dem Index der zugrunde liegenden Tags durchgeführt werden.
Bei der Darstellung dieser Tags für Zeiträume, die kleiner als das 300-fache der Indexauflösung sind, werden die Tags direkt aus der Datenbank abgefragt und die berechneten Tags werden „on the fly“ ausgewertet.
Die Diagnosealgorithmen verwenden Daten der Indexierung, um Korrelationen und Fingerprint-Abweichungen zu bewerten.
Ähnlich wie bei Ähnlichkeitssuchen kann die Kreuzkorrelationsanalyse hohe Korrelationswerte über sehr kurze Zeiträume (ungefähr gleich der Indexauflösung) liefern, obwohl die visualisierten Rohdaten keine oder nur eine geringe Korrelation aufweisen.
Monitore basieren auf Suchen und ermöglichen Ihnen, Ihre Suchen zu operationalisieren. Monitore verwenden daher dieselben Daten wie Suchvorgänge.
Um sicherzustellen, dass die Überwachungsergebnisse zeitnah empfangen werden, wird der Index der in den Monitoren verwendeten Tags (einschließlich der zugrunde liegenden Tags in Formeln) alle 2 Minuten aktualisiert.
Arbeiten mit Daten vor dem Indexhorizont
Wenn Sie mit Zeiträumen arbeiten, die vor dem konfigurierten Indexhorizont beginnen, zeigt TrendMiner Warnindikatoren an, um Sie darauf hinzuweisen, dass einige Funktionen möglicherweise betroffen sind.
Warum das wichtig ist
Indexdaten ermöglichen eine schnelle Visualisierung und sind für bestimmte Funktionen wie die Ähnlichkeitssuche erforderlich. Wenn der Beginn des von Ihnen ausgewählten Zeitraums vor dem Indexhorizont liegt:
TrendMiner muss Daten direkt aus dem Historian abrufen, anstatt den Index zu verwenden, was langsamer ist und zusätzliche Abfragen an den Historian verursacht, d. h. eine Beeinträchtigung der Leistung, die sich auf die Benutzererfahrung auswirkt.
Einige Funktionen, die Indexdaten erfordern, funktionieren nicht richtig oder gar nicht.
Sie sehen Warnsymbole (⚠️) neben den Datumsangaben in der gesamten Anwendung, wenn das Start- und/oder Enddatum vor dem Horizont liegt.
Auswirkung nach Funktion
Die folgende Tabelle zeigt, wie sich die Verwendung von Daten vor dem Horizont auf die einzelnen Funktionen auswirkt. Dies steht in direktem Zusammenhang mit dem obigen Abschnitt, in dem beschrieben wird, wie Indexdaten verwendet werden. TrendMiner verfügt über keine Indexdaten für Zeiträume vor dem Indexhorizont.
Funktion | Auswirkungen bei der Arbeit mit Daten vor dem Horizont |
|---|---|
Trend-Ansichten | Die Daten werden aus dem Historian statt aus dem Index abgerufen. Berechnete Tags beziehen die Daten für die beteiligten Variablen ebenfalls direkt aus der Quelle.1. Dies ist langsamer und hat einen hohen Einfluss auf die Leistung, aber das Diagramm wird korrekt angezeigt. |
Dashboards | Gleiche Auswirkung wie Trendansichten1 |
Suchen | Suchen können nur Ergebnisse für Zeiträume innerhalb des Indexbereichs liefern. |
Ähnlichkeitssuche mit einer Abfrage vor dem Indexhorizont | Funktioniert nicht. Die Ähnlichkeitssuche erfordert Indexdaten. Suchanfragen mit einem Abfragezeitraum vor dem Horizont liefern keine Ergebnisse, und zugehörige Monitore sind systemseitig deaktiviert. Gleiches gilt für Monitore, die einen Fingerprint verwenden und die Ähnlichkeitssuche als Auslöser nutzen. |
Fingerprints | Bestehende Fingerprints – basierend auf Daten vor dem Horizont – funktionieren weiterhin mit ihrer zwischengespeicherten Hülle. Wenn Sie jedoch einen solchen Fingerprint aktualisieren, wird die Hülle anhand der neu erfassten Daten, die direkt aus dem Historian 1 abgerufen werden, neu berechnet – die Form kann sich erheblich ändern. |
Vorhersage-Tags | Bestehende Vorhersage-Tags sind im Wesentlichen gespeicherte Formeln und funktionieren daher weiterhin. Die Analyse selbst erfordert Indexdaten und kann daher nicht mehr ausgeführt oder ausgewertet werden. |
1 Dies ist das Standardverhalten für die meisten Datenquellen. Einige interne und externe Quellen weichen jedoch davon ab. Benutzerdefinierte Berechnungen und Machine Learning Tags (bei denen es sich um interne TrendMiner-Tags handelt) verwenden nur Indexdaten und berechnen niemals Werte spontan. Bei gängigen externen Datenquellen bezieht TrendMiner die Daten in der Regel direkt aus der Datenquelle, wenn keine indizierten Daten vorhanden sind. Bei Datenquellen, die benutzerdefinierte Abfragen erfordern, kann das direkte Abrufen aus der Datenquelle deaktiviert werden.
Behebung von Problemen mit betroffenen Items
Betroffene Items können durch eine erneute Verlängerung des Horizonts korrigiert werden. Alle betroffenen Items werden/können korrigiert werden, sobald die Indexdaten wieder verfügbar sind. Alternativ sollte jedes Item neu bewertet werden, um zu prüfen, ob mit den Daten nach dem neuen Horizont das gleiche Ergebnis erzielt werden kann.
Wenden Sie sich an Ihren Administrator, um ein betroffenes Item zu beheben, indem Sie den Indexhorizont verschieben.
Für Administratoren
Bevor Sie den Indexhorizont in ConfigHub reduzieren, können Sie einen Excel-Export erstellen, in dem alle betroffenen Ähnlichkeitssuchen und auf Ähnlichkeitssuchen basierenden Monitors aufgelistet sind. So können Sie die Auswirkungen einschätzen und mit den betroffenen Benutzern kommunizieren, bevor Sie die Änderung vornehmen.
Nachdem der Horizont reduziert und die Indexdaten gelöscht wurden, erhalten Sie eine Benachrichtigung, die bestätigt, dass die Löschung abgeschlossen ist.
Weitere Informationen zum Ändern des Indexhorizonts finden Sie in der Dokumentation zu den ConfigHub-Dateneinstellungen.