Generador de Tags: Calculs personnalisés
Nota
Esta funcionalidad está disponible a partir de la versión 2024.R1.1 de TrendMiner y requiere una licencia de usuario experto.
La opción de cálculo personalizado en el generador de tags le permite crear nuevos tags de TrendMiner basados en un script Python desarrollado a medida. Esto le permite ir más allá de las capacidades estándar de manipulación de tags de TrendMiner y abrir casos de uso adicionales. Una vez creados, estos tags pueden visualizarse y analizarse como cualquier otro tag en TrendMiner. Los cálculos personalizados se encuentran en el menú del generador de tags. La función de cálculos personalizados está marcada como función LAB, lo que significa que la función permanece en desarrollo activo y podría cambiar en versiones más recientes.
Aviso
Esta función sólo está disponible si tiene derechos de gestión de acceso a los Calculs personnalisés
Esta primera parte del artículo describe el flujo de configuración de un tag de cálculos personalizados y los requisitos de los scripts proporcionados. El artículo también describe los datos que se utilizarán para trazar los datos y las limitaciones específicas de los cálculos personalizados.
El flujo de trabajo general del Generador de Tags se aplica a los cálculos personalizados. Puede encontrar una visión general de estos flujos de trabajo aquí. Los paneles de configuración de los tags de cálculos personalizados se configuran de forma diferente para permitir ciclos de iteración sencillos durante el desarrollo del script. Esto se consigue proporcionando un editor de código dedicado y un modo de vista previa.
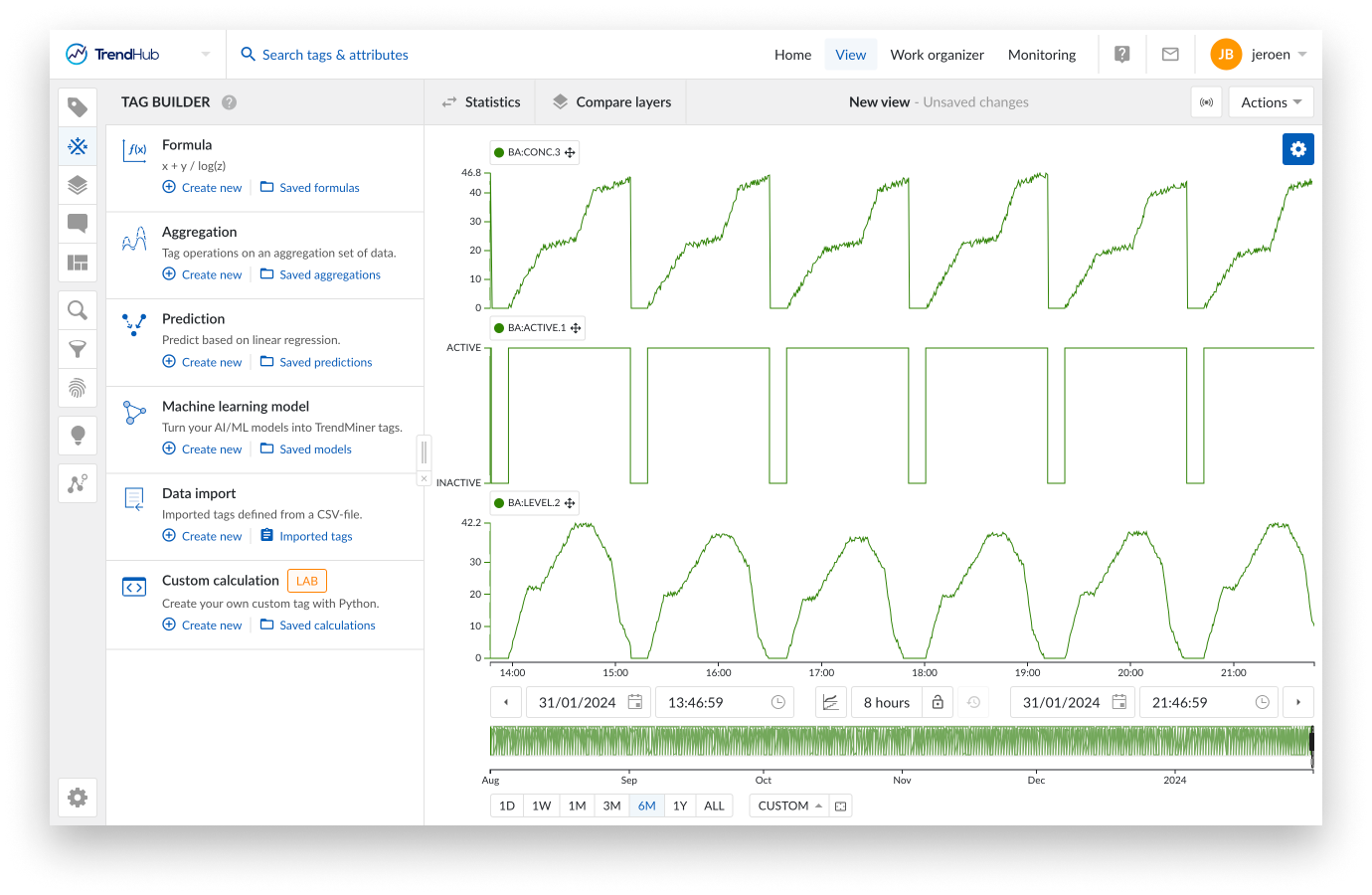
Panel de desarrollo de scripts
Al entrar en el menú de cálculo personalizado, el gráfico de enfoque se sustituye completamente por el panel de desarrollo de scripts, que consta de 2 pestañas:
Código
Vista previa
Su script de python personalizado puede copiarse o crearse desde cero en el editor en la pestaña de código. El resaltado de sintaxis de Python está habilitado de base para aumentar la legibilidad. Consulte la siguiente sección para saber cómo debe configurarse un script para obtener un tag de TrendMiner utilizable. El botón de ejecución de la parte derecha puede utilizarse para ejecutar el script actual y abrirá automáticamente la pestaña de vista previa. Aunque puede ejecutarse cualquier script sin salida gráfica, el objetivo principal de esta función es crear un nuevo tag, por lo que debe proporcionarse el conjunto de marcas de tiempo y valores . Si se proporcionan, la pestaña de vista previa mostrará un gráfico del comportamiento del script del tag basado en la hora de inicio y fin aplicada en los ajustes de vista previa.
Puede alternar entre el código y la pestaña de vista previa. El script sólo se ejecutará al hacer clic en ejecutar. En la pestaña de vista previa se muestra una marca de tiempo para indicar cuándo se ejecutó el script por última vez.
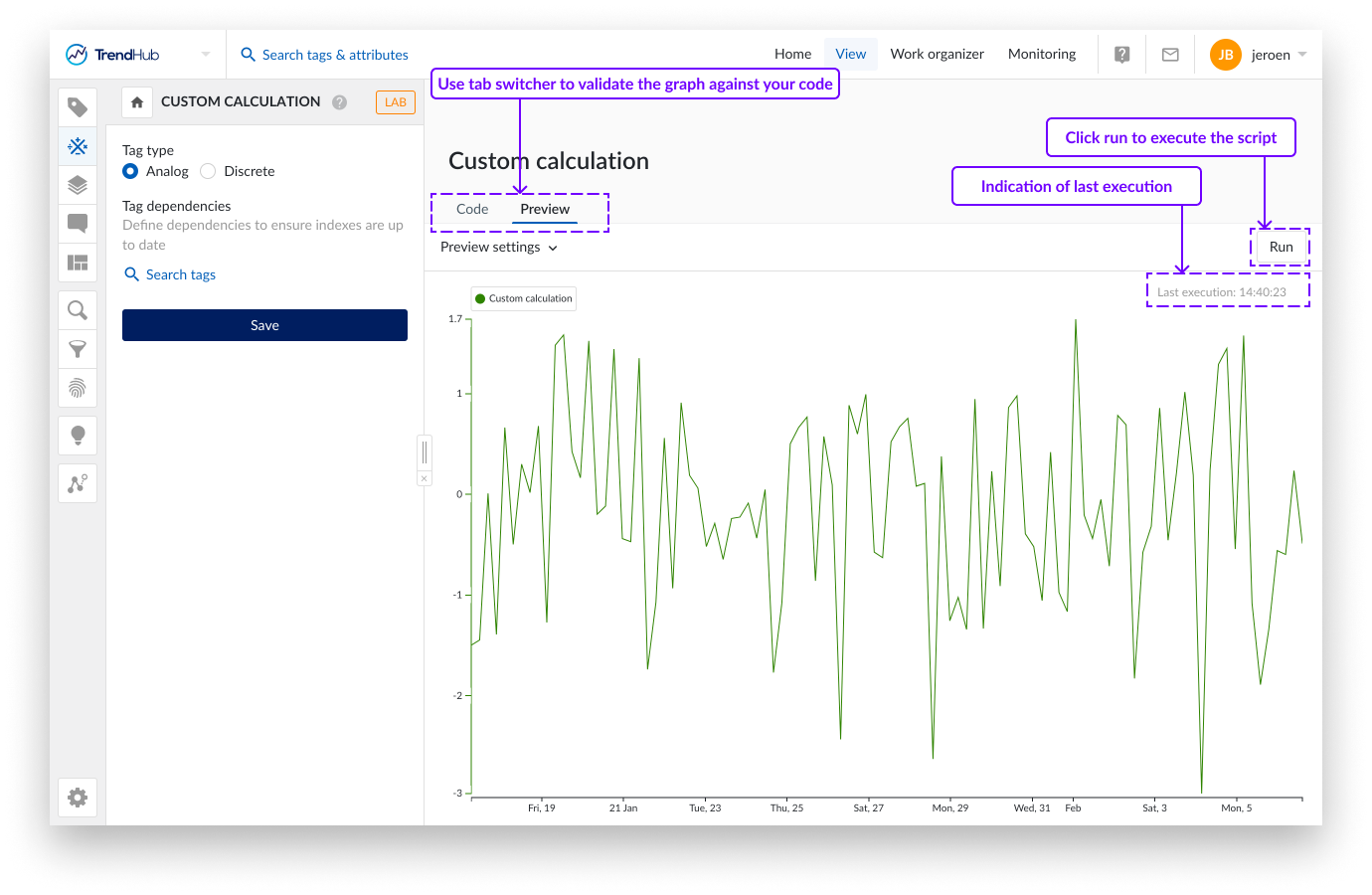
Por defecto, la configuración de la vista previa abarca las últimas 8 horas. Las fechas de inicio y fin pueden modificarse para comprobar un periodo de interés personalizado. Sin embargo, el lapso de tiempo total del modo de vista previa está limitado a 1 mes.
Se pueden añadir declaraciones de impresión al script para ayudar durante el desarrollo. Estas declaraciones de impresión, así como los errores se mostrarán debajo del gráfico en caso de que sean aplicables. Si no hay errores y no se utilizan declaraciones de impresión, estos cuadros de texto se omitirán.
Aviso
La configuración de la vista previa y la indicación de la última ejecución se proporcionan en su zona horaria local. Estos tiempos se convierten a UTC, que se utilizará en el script y se mostrará en las declaraciones de impresión.
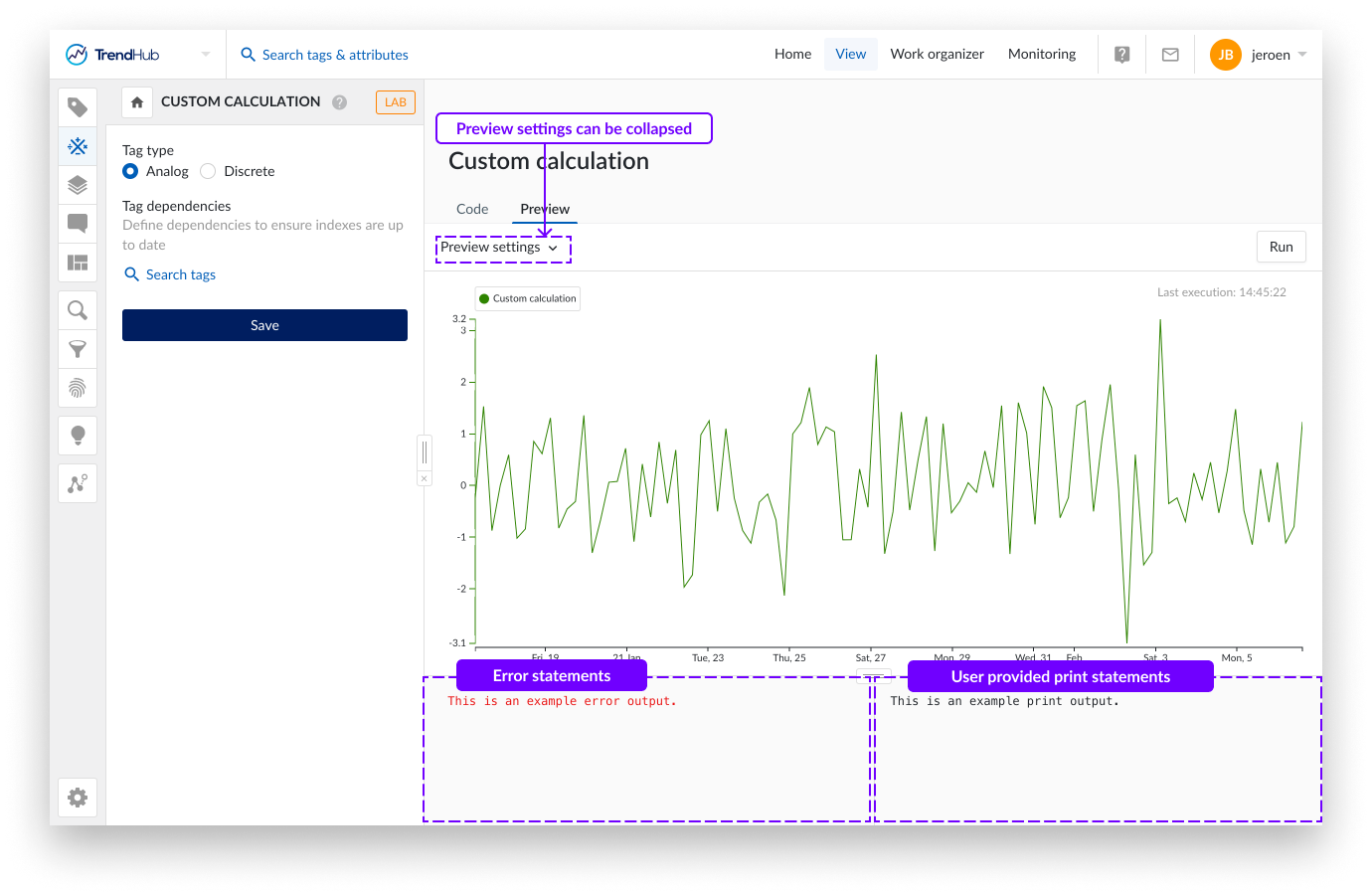
Configuración de tags
Aunque el comportamiento principal del cálculo personalizado estará influido por el propio script, hay 2 configuraciones que deben especificarse en el menú de la izquierda.
Tipo de tag
El tipo de tag determina cómo se interpolarán los datos proporcionados por el tag. Los datos se interpolarán linealmente (Tag analógico), o de forma escalonada (Tag discreto). Actualmente no es posible guardar el tag como String o Digital.
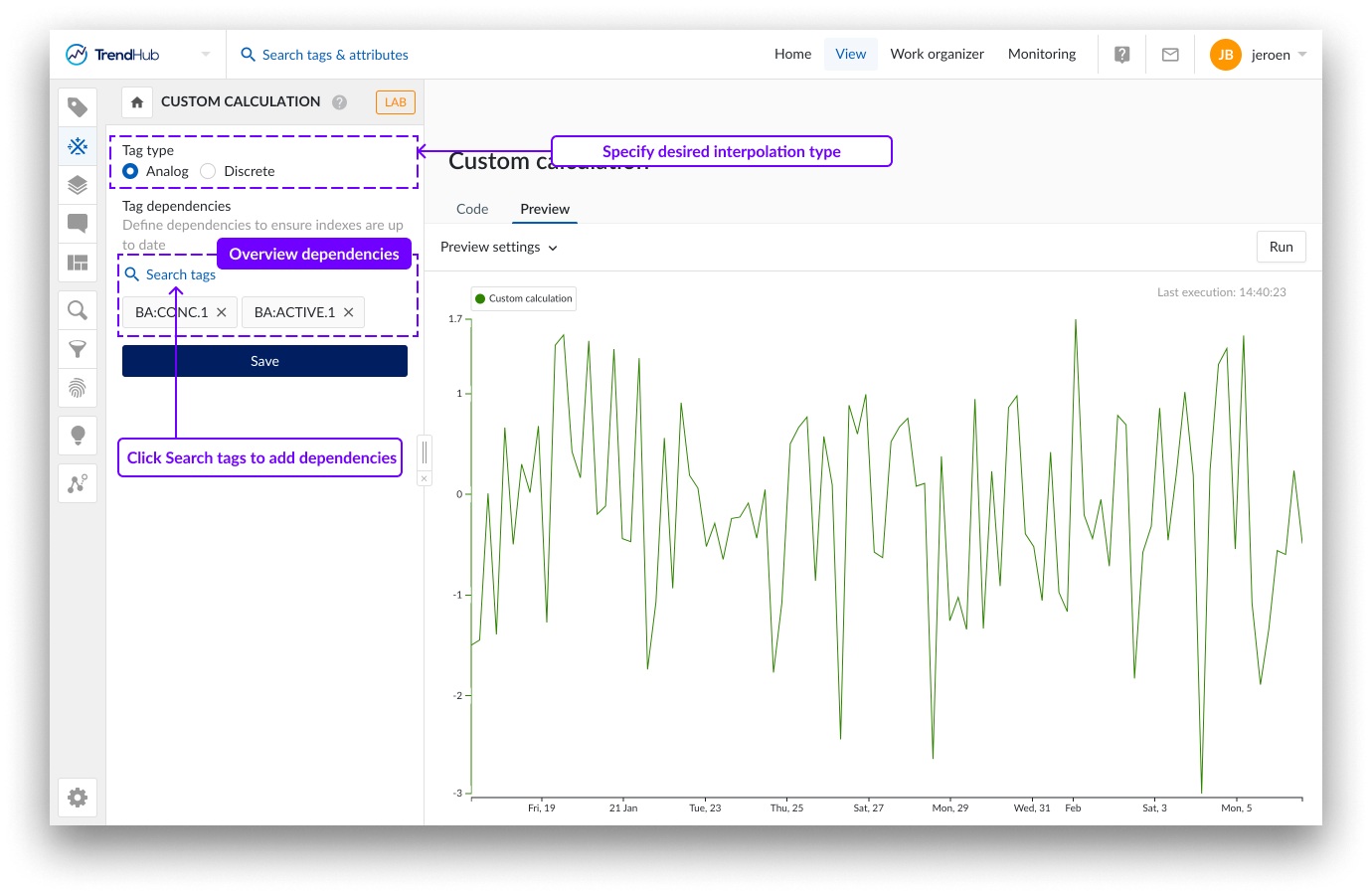
Dependencias de los tags
En la sección de dependencias de tags, debe seleccionar todos los tags a los que se accede en su script. Esto es diferente en comparación con todos los demás tipos de Generador de Tags, donde las dependencias de variables mapeadas se detectan automáticamente como parte del flujo de creación de un tag. Con los cálculos personalizados, TrendMiner no puede deducir qué tags se están utilizando. Esta información es crucial en caso de que se utilice un cálculo personalizado dentro de un Monitor. En ese caso, TrendMiner necesita asegurarse de que el índice del cálculo personalizado, así como todas las dependencias, están actualizados. El número máximo de dependencias para el cálculo personalizado está fijado en 50.
Aviso
En caso de que no se proporcionen dependencias de tags, los resultados del monitor se retrasarán, o potencialmente no se activarán si los índices de los tags utilizados no existen.
Requisitos
El script de Python debe cumplir un par de requisitos para garantizar que la previsualización (y la indexación) de un cálculo personalizado funcionen correctamente.
Script mínimo viable
Al crear un nuevo cálculo personalizado, se proporcionará un script marcador de posición en el editor. Se trata de un ejemplo ficticio que contiene todos los elementos necesarios para crear y guardar correctamente un tag de cálculo personalizado. Siéntase libre de experimentar con este script para comprender cómo funciona la creación de series temporales.
import numpy as np
import pandas as pd
import os
# Parameter configuration
output_file = os.environ["OUTPUT_FILE"] # Where to write output table
start = os.environ["START_TIMESTAMP"] # Start datetime of range to compute values in
end = os.environ["END_TIMESTAMP"] # End datetime of range to compute values in
# Code to compute table
num_points = 100
pd.DataFrame(
{
"ts": pd.date_range(start, end, num_points),
"value": np.random.randn(num_points)
}
).to_csv(output_file, index=False) Basándonos en este ejemplo ficticio, los siguientes elementos son obligatorios:
Acceso al archivo de salida.
Acceso a la hora de inicio del periodo para el que se realizará el cálculo (tanto en la vista previa como durante la indexación).
Acceso a la hora final del periodo para el que se realizará el cálculo (tanto en la vista previa como durante la indexación).
Almacenamiento de datos de series temporales en el archivo de salida, que se guarda como archivo CSV:
el archivo debe contener 2 columnas
marcas de tiempo
valores
Además de estos elementos, la salida generada también debe cumplir los siguientes requisitos. Si no es así, tanto la previsualización como la indexación del tag fallarán.
Los datos de salida tienen que estar comprendidos dentro de los intervalos de tiempo especificados (hora de inicio y hora final proporcionadas).
No se permiten puntos duplicados, es decir, con la misma marca de tiempo.
Se permite un máximo de 6 puntos de datos por intervalo de índice.
El guión debe poder completarse en 2 minutos durante un periodo de 1 mes.
Cada script dispone de 512 MB de RAM. El script debería poder completarse dentro de este límite.
Aviso
Antes de guardar el Tag, se aconseja probar la vista previa en 1 mes de datos, ya que la indexación hacia atrás se ejecutará por mes. Esto proporciona un nivel de certeza de que la indexación funcionará correctamente.
Aparecerán mensajes de error claros al ejecutar el script si no se cumplen los requisitos.
Ampliación del script mínimo viable
Para llevar a cabo su caso de uso, puede ampliar el script mínimo viable en función de sus necesidades. Dispone de un conjunto predeterminado de paquetes de Python. No se pueden instalar paquetes adicionales.
Paquetes disponibles
numpy
pandas
polars
pyarrow
python-dateutil
pytz
requests
scipy
Además, SDK de TrendMiner está disponible, lo que le permite extraer fácilmente datos de TrendMiner, como datos de índice de etiquetas.
Para obtener una descripción general actualizada de los paquetes disponibles y su versión, puede incluir el siguiente fragmento de código en su script:
import importlib.metadata
installed_packages = importlib.metadata.distributions()
for package in installed_packages:
print(package.metadata["Name"], package.version)Aviso
No dude en comunicarse con su gerente de éxito del cliente o ingeniero de análisis de datos de TrendMiner para que lo ayude a crear cálculos más avanzados, o consulte la TrendMiner GitHub para acceder a códigos de muestra para diversos casos de uso.
Indexación de tags de cálculos personalizados
Para configurar correctamente un script de cálculo personalizado, es importante comprender cómo se indexarán estos tags. Para saber más sobre la indexación en sí, consulte este artículo.
En cuanto se guarde el tag de cálculo personalizado, el tag comenzará la indexación. Inicialmente, el proceso de indexación hará un backfill histórico (es decir, indexación hacia atrás). Esto se hace ejecutando el script por mes. Los parámetros START_TIMESTAMP y END_TIMESTAMP de su script serán siempre la hora de inicio y fin de un mes durante este proceso. Los tags indexados se mantendrán actualizados automáticamente (es decir, indexación hacia adelante). Por defecto, se realiza una comprobación de nuevos datos cada hora. En caso de que su Tag esté siendo utilizado en un Monitor, esto se hará cada 2 minutos. En este caso, START_TIMESTAMP y END_TIMESTAMP serán la marca de tiempo del último punto de índice almacenado y el momento actual, respectivamente. Aunque TrendMiner comprobará si hay datos nuevos cada hora (o cada 2 minutos), el periodo real en el que se ejecutan los scripts puede ser más largo, dependiendo de dónde se almacenó el último punto de datos.
Modo de vista previa
El modo de vista previa mostrará todos los puntos de datos devueltos por los scripts, teniendo en cuenta las restricciones mencionadas anteriormente. Sin embargo, en cuanto se devuelvan más de 10.000 puntos de datos, el número de puntos de datos se reducirá.
Vista principal
Aviso
El gráfico del modo de vista previa y el gráfico de enfoque basado en el cálculo personalizado guardado pueden tener un aspecto ligeramente distinto al visualizar 1 mes de datos, ya que se aplica un algoritmo de muestreo diferente.
También en el caso de las ventanas pequeñas, el gráfico de enfoque se representará en función de los datos indexados almacenados (un máximo de 6 puntos de datos por intervalo de indexación).
Aviso
También en el caso de las ventanas pequeñas, el gráfico de enfoque se representará en función de los datos indexados almacenados (un máximo de 6 puntos de datos por intervalo de indexación).
Las limitaciones generales mencionadas en el documento general del Generador de Tags son aplicables a los cálculos personalizados. Las limitaciones específicas de los cálculos personalizados incluyen:
El número de cálculos personalizados guardados está limitado a 120 por instancia de TrendMiner.
Durante la indexación, todos los scripts se ejecutarán en secuencia. Si se utilizan varios tags de cálculo personalizados en un Monitor y los scripts tienen un tiempo de ejecución largo, se espera un retraso adicional en los resultados del Monitor.