Machine Learning Hub y Notebooks
¿Qué es Machine Learning Hub?
La visión de TrendMiner de democratizar el análisis de datos va más allá de dotar a los expertos en la materia de herramientas de autoservicio para incluir también una colaboración más estrecha entre los distintos expertos a la hora de resolver problemas. Algunos de los problemas más complejos requieren la introducción de científicos de datos que aporten técnicas especializadas que permitan a las empresas exprimir los conocimientos más profundos de los datos disponibles. Piense en las estadísticas avanzadas y los modelos de aprendizaje automático o machine learning.
Con MLHub, los científicos de datos pueden acceder a los datos de TrendMiner (tanto en bruto como preprocesados y contextualizados en las vistas de TrendMiner) y validar hipótesis o crear/entrenar/desplegar modelos de machine learning en el nuevo entorno de Notebook, que otros usuarios pueden aplicar mediante tags de modelos de machine learning y visualizar en DashHub.
Cómo utilizar MLHub
Importante
Sólo se puede acceder a MLHub una vez configurada la gestión de accesos, para lo que es necesaria una licencia aparte. Para más detalles sobre la gestión de acceso, lea aquí. Póngase en contacto con nosotros en TrendMiner si necesita más información sobre las licencias.
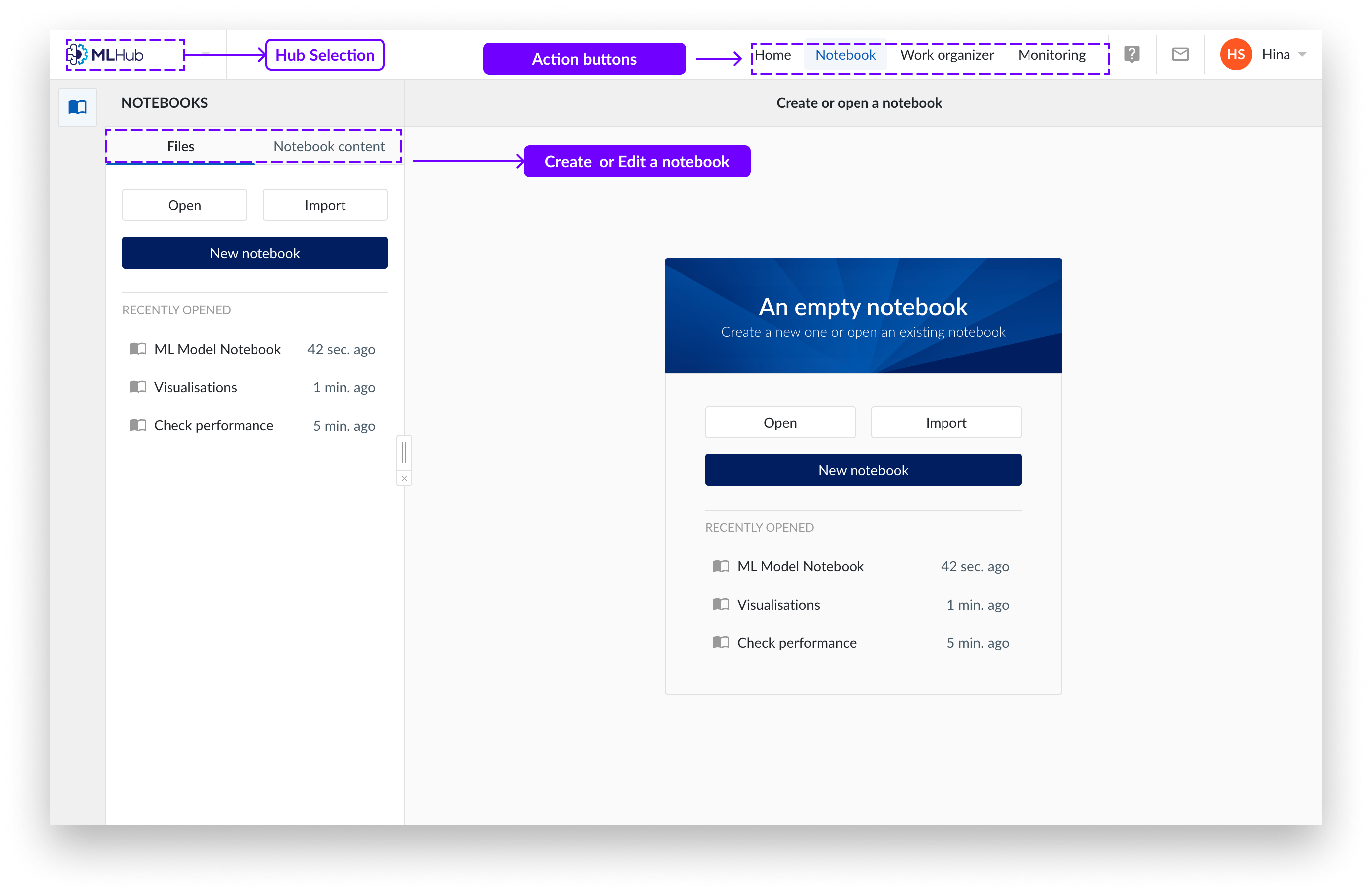
En la esquina superior izquierda del entorno de TrendMiner encontrará el botón de selección de Hub. Aquí puede seleccionar hacia qué interfaz desea navegar.
Pulse el botón "MLHub". Para cerrar la pantalla de inicio y acceder a la vista de Notebook, haga clic en Notebook en la barra superior.
La barra superior le permite volver a Inicio, Notebooks, Organizador del trabajo y Monitoreo.
La funcionalidad Notebook de TrendMiner es una plataforma que permite a los usuarios crear y trabajar con herramientas avanzadas más allá de las sólidas capacidades incorporadas, dentro del entorno de TrendMiner.
Con los Notebooks integrados, podrá:
Cargar los datos de una vista de TrendHub que se haya preparado utilizando las funcionalidades típicas incorporadas de TrendMiner (seleccione un conjunto de tags interesantes, seleccione los marcos temporales de interés, por ejemplo, mediante búsquedas, ...).
Visualice y analice sus datos de formas diferentes que no son posibles con TrendMiner.
Lleve a cabo la automatización de los análisis mediante secuencias de comandos (por ejemplo, repita el análisis en una amplia gama de equipos).
Cree tags (predictivos) utilizando modelos personalizados (por ejemplo, redes neuronales o agrupación) compatibles con las bibliotecas típicas de Notebook.
Puede hacer uso de las opciones de visualización más avanzadas que vienen incorporadas con el Notebook. El Notebook integrado viene con su propia Ventana de Notebook, de modo que también puede integrar su trabajo en un panel de DashHub y ponerlo a disposición de toda su organización.
Nota
Intérprete - El intérprete por defecto de los Notebooks es Python.
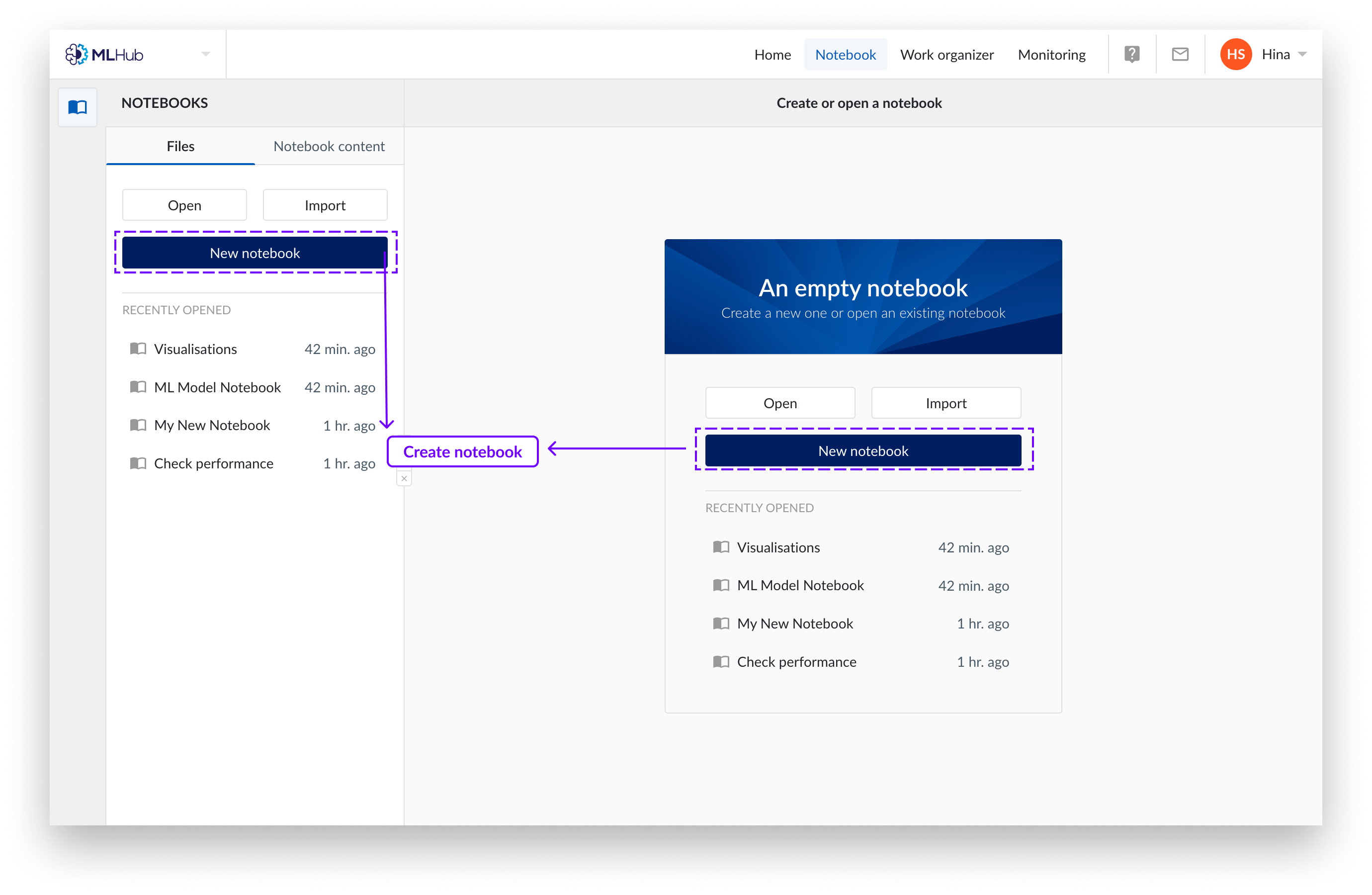
En la pestaña Notebook de MLHub, puede crear un nuevo notebook, cargar o importar uno existente. Un Notebook nuevo siempre estará vacío.
Entre en la pestaña Notebook de MLHub.
Haga clic en «Nuevo Notebook».
Rellene los campos abiertos y seleccione una carpeta del Organizador de trabajo para guardar su nuevo notebook.
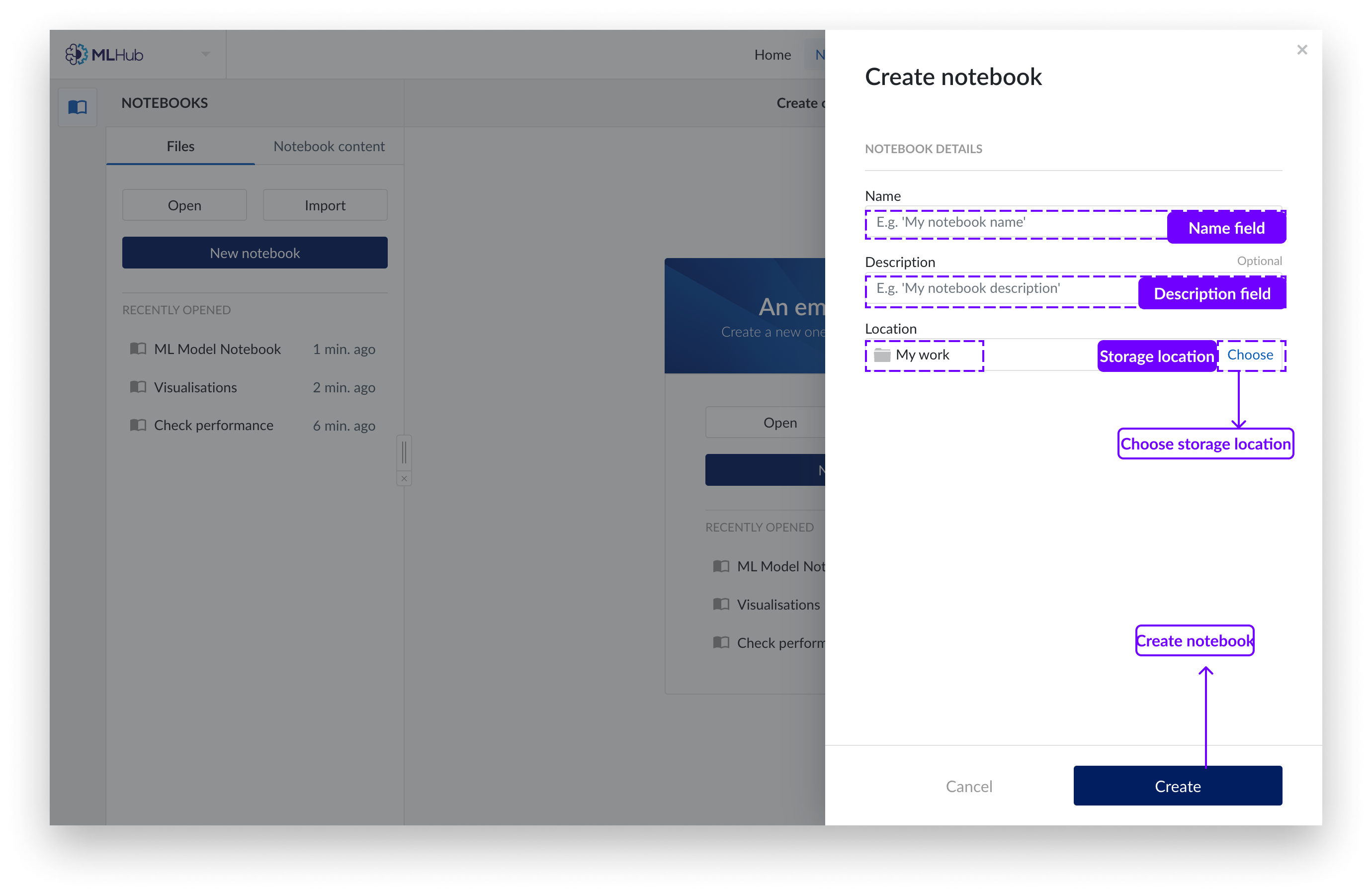
Pulse el botón "Crear".
Ahora estará en el contenido del Notebook con fragmentos de código predeterminados, en el panel lateral. Estos fragmentos de código se pueden usar en los notebooks. Lea "fragmentos de código" más abajo para más información.
Elija la configuración del kernel que desea lanzar. Ofrecemos kernels que incluyen paquetes de visualización preinstalados. Le recomendamos que lance el kernel «Python 3.11 en Kubernetes».
Confirme su selección pulsando «Seleccionar».
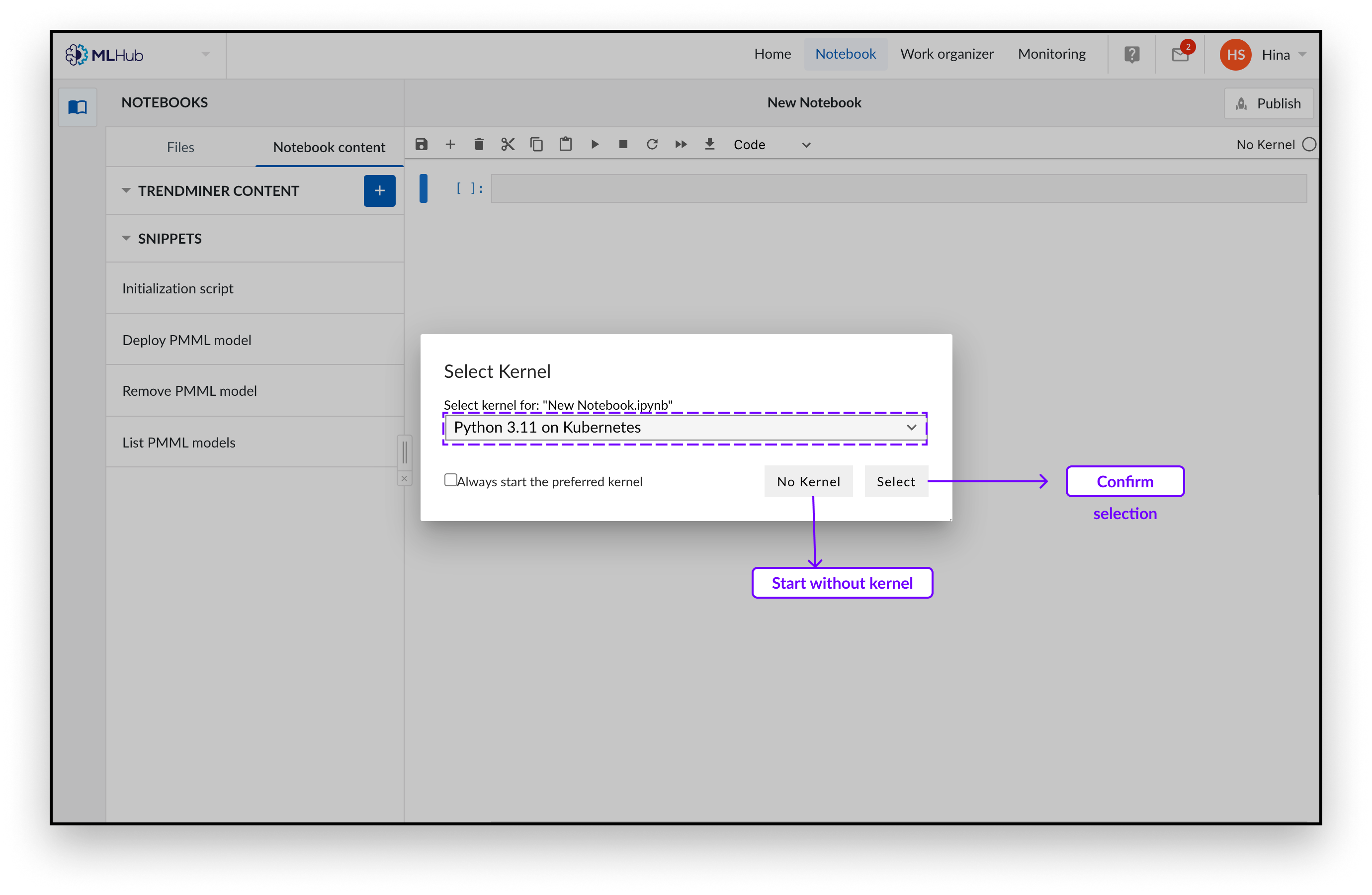
Se abrirá un nuevo Notebook en el que podrá escribir su código python. Puede introducir nuestro código inicial que carga algunos paquetes altamente recomendados, ya que lo necesitará para leer el contenido de TrendMiner. Puede añadir este código haciendo clic en el botón de fragmento "script de inicialización" del menú de fragmentos de la izquierda.
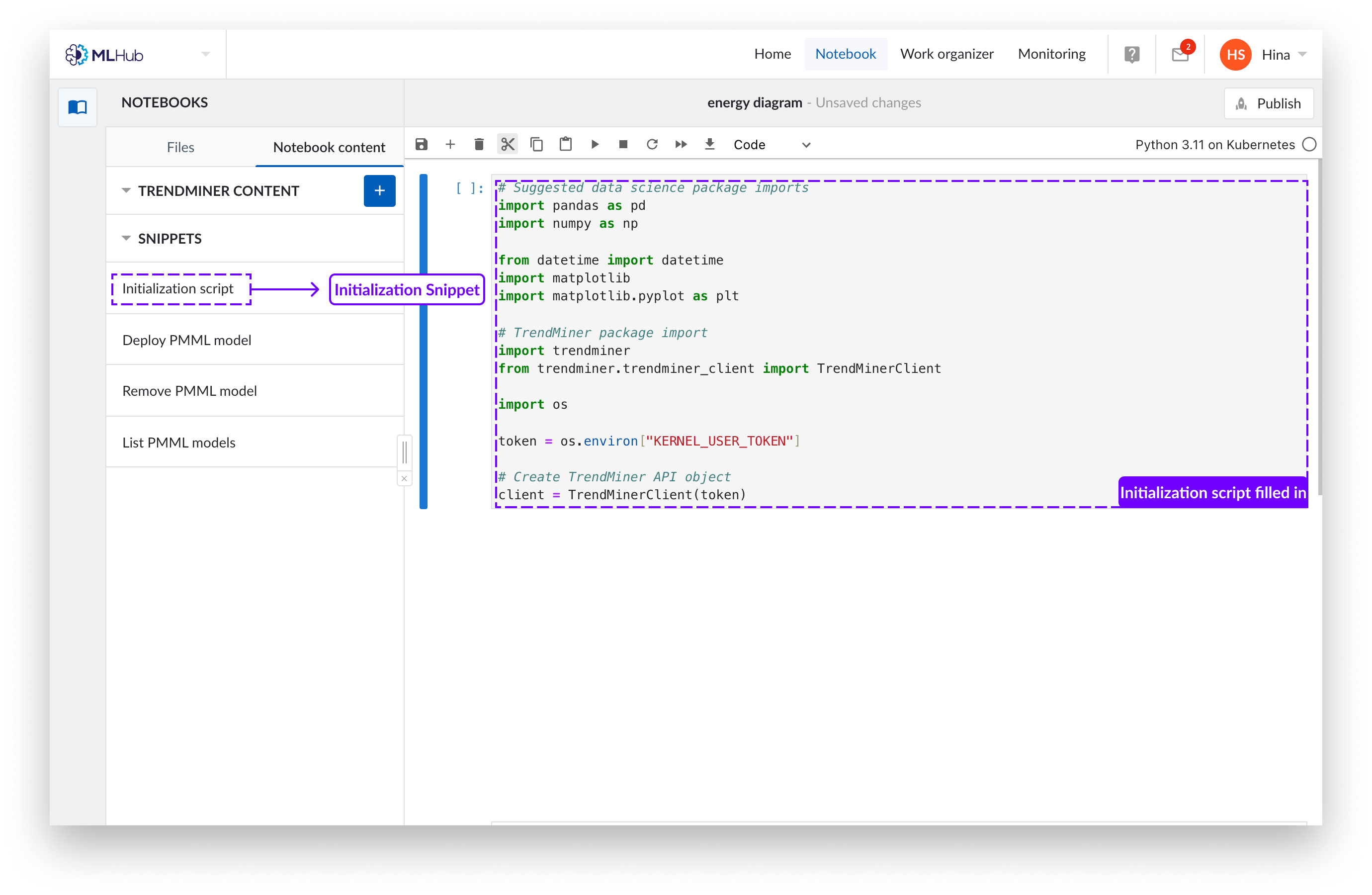
Abrir un Notebook
Haga clic en la pestaña «Archivos» de MLHub.
Haga clic en «Abrir».
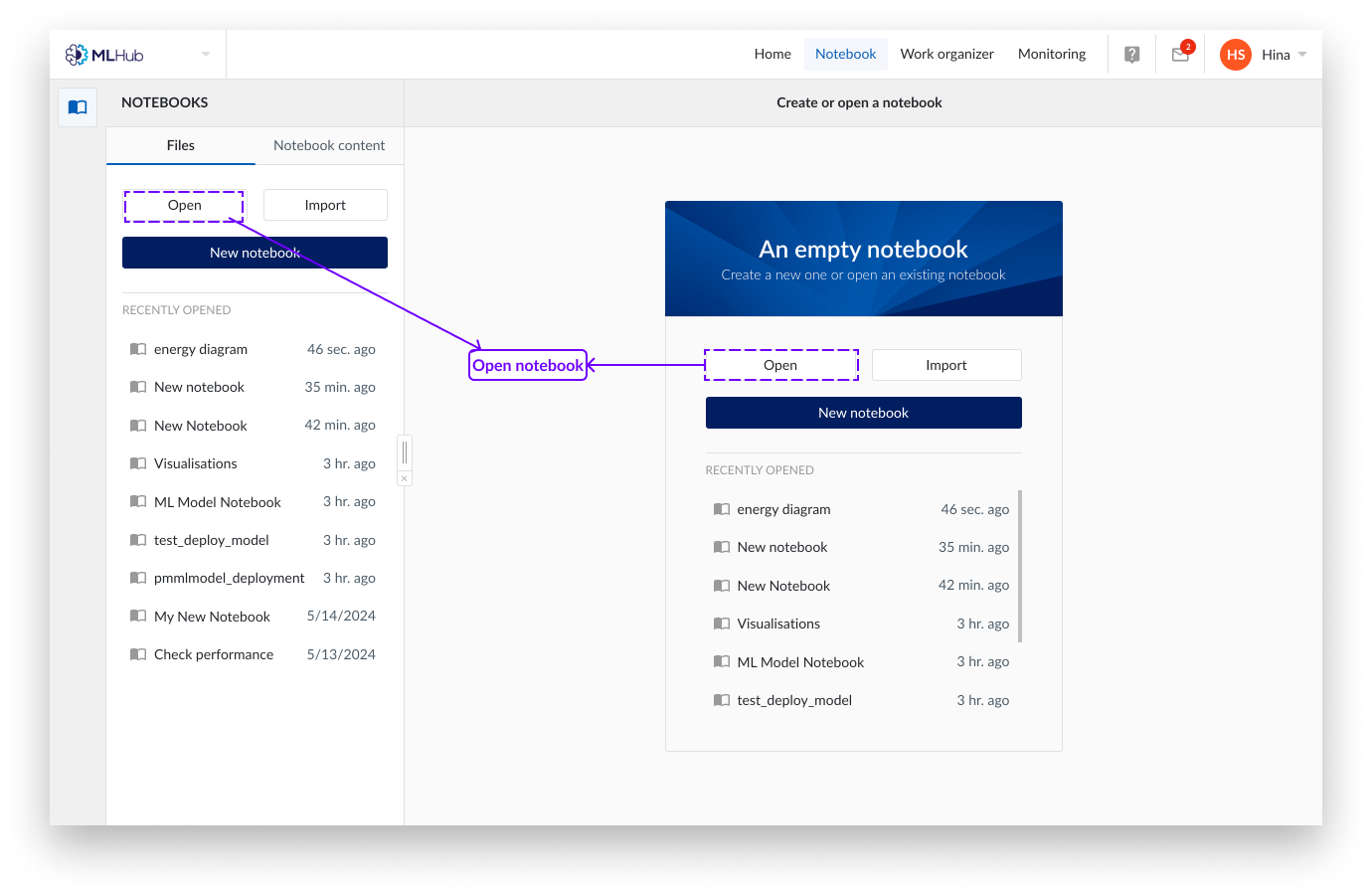
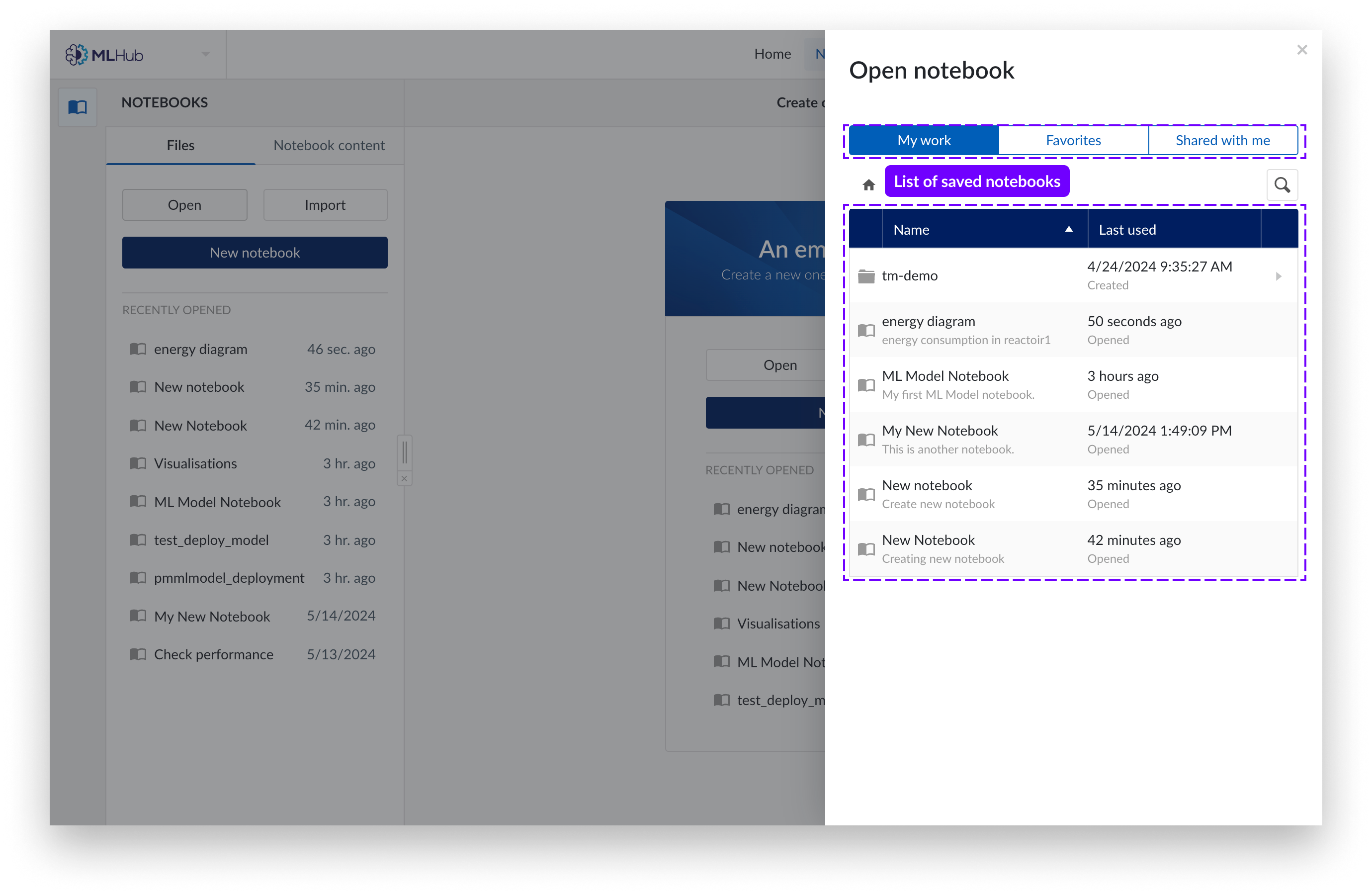
Ahora puede ver sus Notebooks en «Mi trabajo» o «Favoritos» . Haga clic en el Notebook que desee abrir.
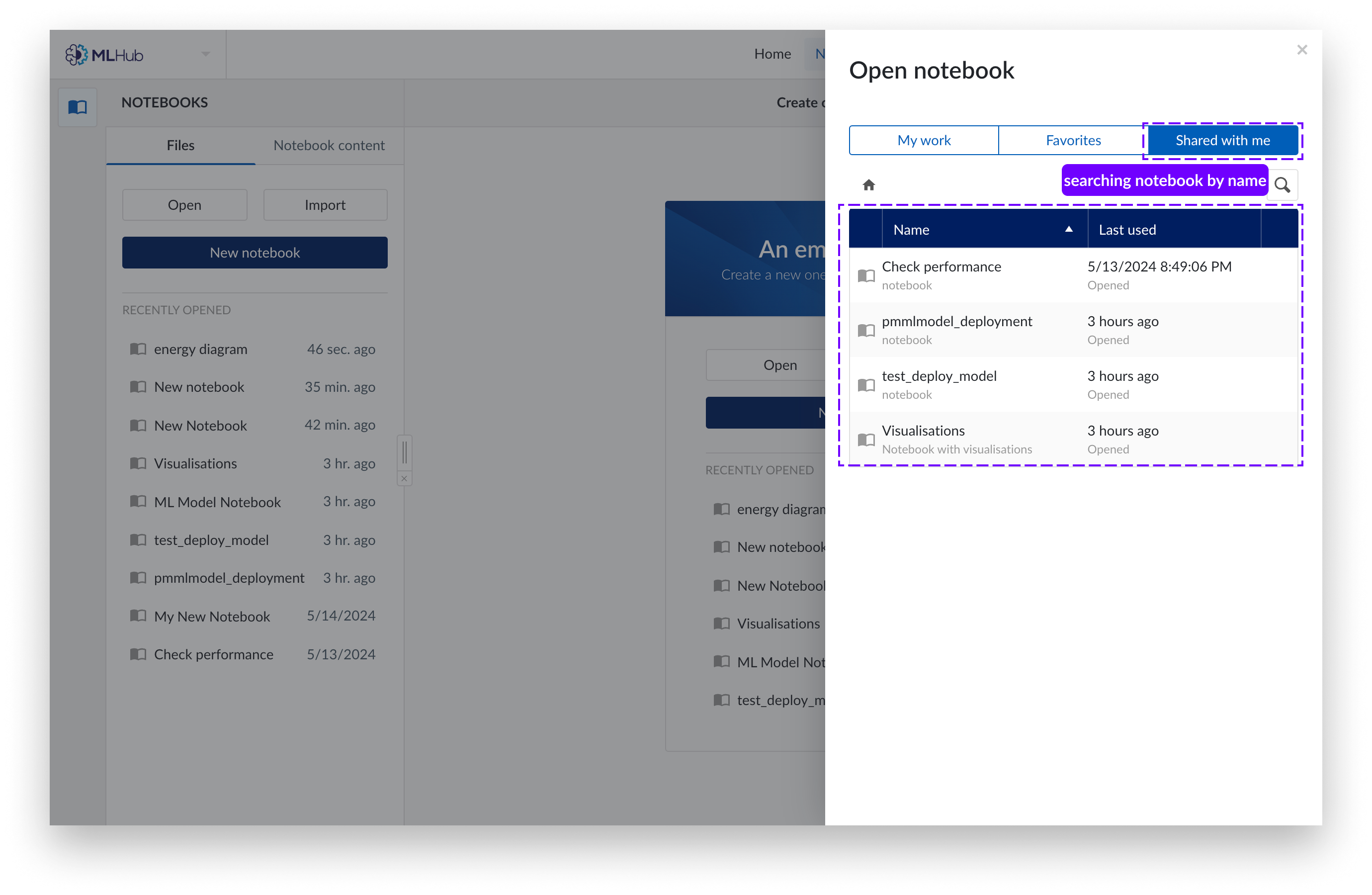
También puede acceder a los Notebooks compartidos con usted por otros usuarios en «Compartidos conmigo» .
Entre en la pestaña Notebook de MLHub.
Pulse el botón "Importar".
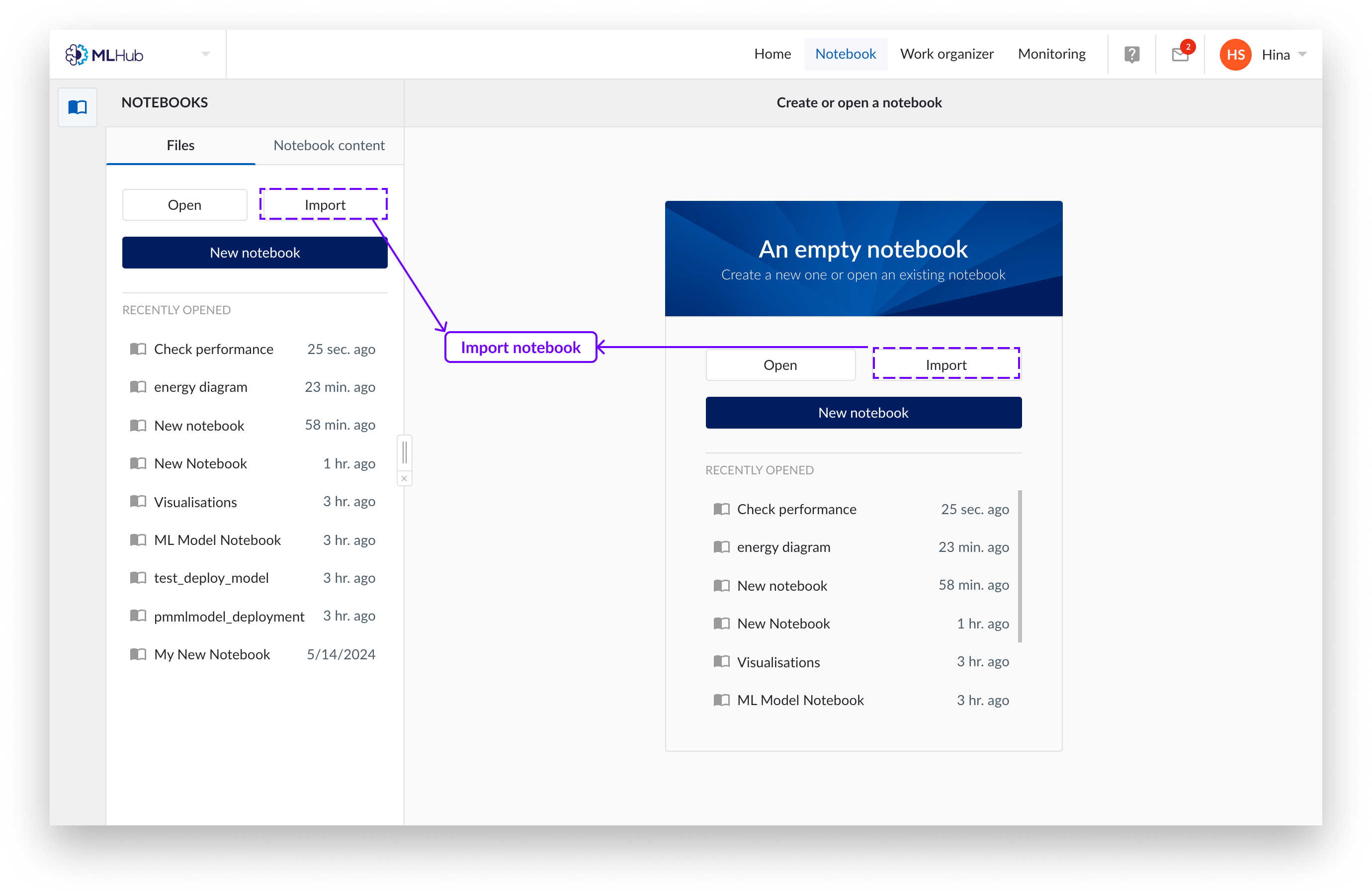
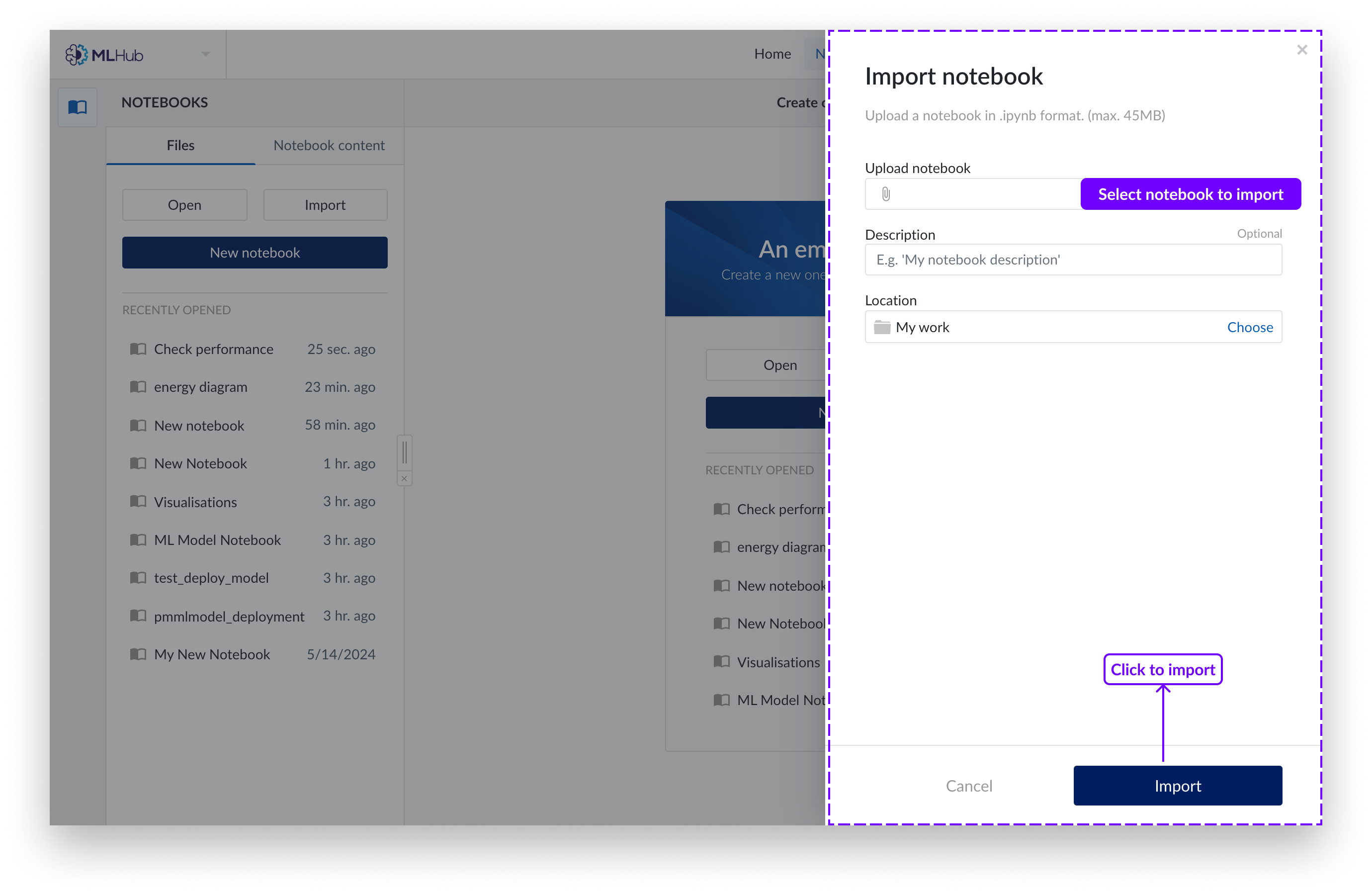
Aparecerá un panel a la derecha de la pantalla. Elija cargar un notebook con su sistema local de explorador de archivos o elija utilizar el organizador de trabajo. Sólo se admiten notebooks Jupyter (extensión de archivo .ipynb).
Seleccione "importar".
Nota
A partir de la versión 2022.R2, sólo "Vistas de TrendHub" y "Vistas de ContextHub" están disponibles como contenido de TrendMiner. En versiones posteriores se introducirán más contenidos.
Puede cargar vistas de TrendHub o ContextHub, por ejemplo, de periodos de funcionamiento bueno y/o anormal y, a continuación, compararlas mediante análisis avanzados, añadirlas a su lista de CONTENIDOS DE TRENDMINER.
Pulse el botón azul "+". Aparecerá un panel lateral por la derecha.
Seleccione el elemento o elementos de vista guardados que desea añadir como conjunto de datos.
Pulse "Cargar".
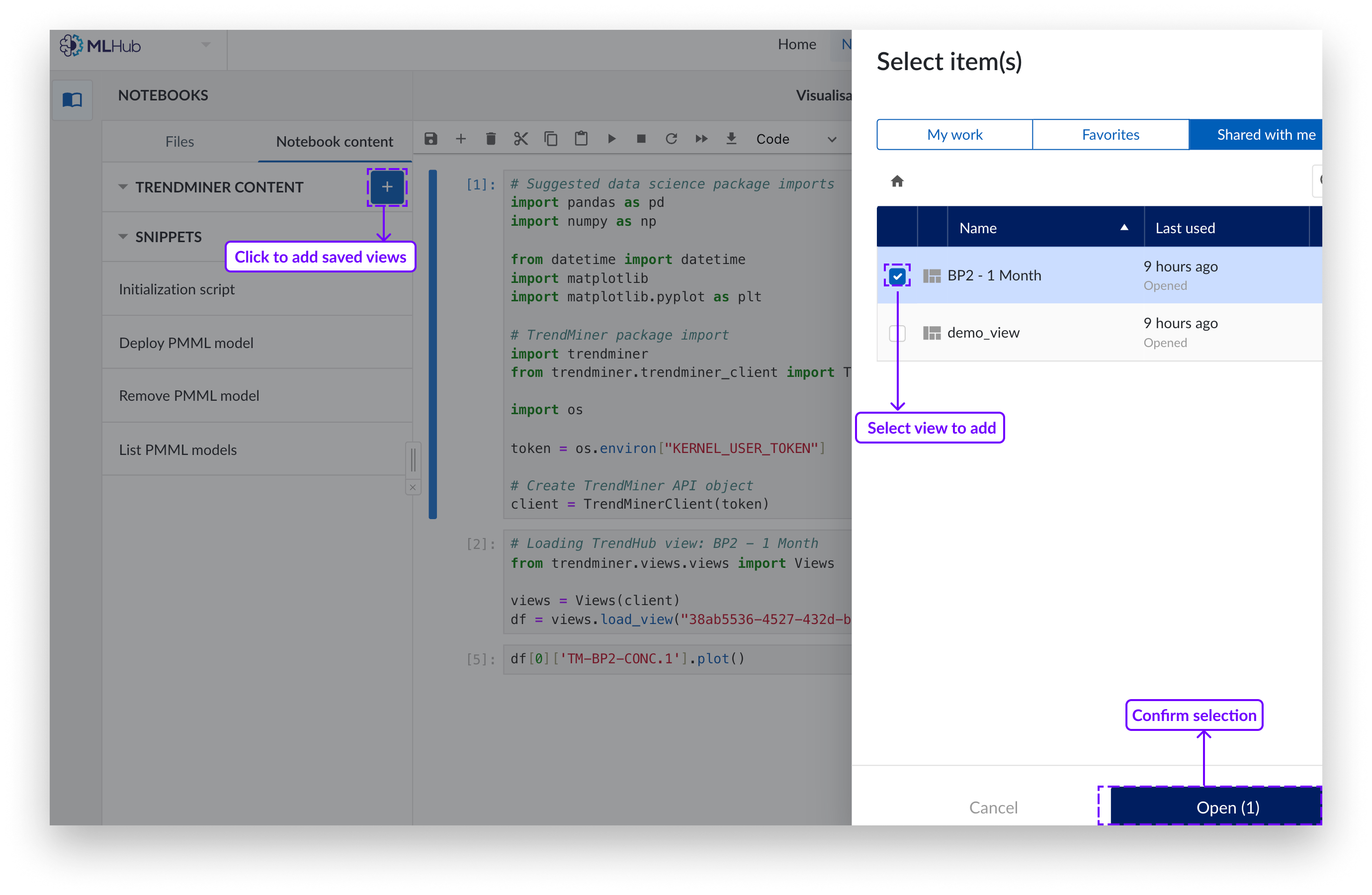
Los elementos de la lista del menú de contenidos pueden abrirse o borrarse. Para borrar pulse la "x" en el menú situado a la derecha del elemento a borrar.
Haga clic en el nuevo contenido para abrirlo. Esto añadirá el código Python correspondiente en una nueva celda al final del Notebook.
Puede obtener más información ejecutando el siguiente comando en el notebook:
help(trendminer.dataframes.data_frames)
load_view( ): Carga los datos de las series temporales de una vista TrendHub guardada en una lista de Pandas DataFrames.
Se devuelve un DataFrame por capa en la vista.
Cada DataFrame puede tener un conjunto diferente de Tags disponibles.
Los parámetros opcionales [layer_ids] le permiten cargar únicamente una lista especificada de capas (identificadas por los ids de capa, proporcionados por la función view_info).
view_info( ): Recopila información sobre una vista basándose en su ID. Esta información puede utilizarse para obtener datos de una vista: enumera todas las capas incluidas en la vista. Al obtener datos de la vista, puede seleccionar las capas que se incluirán en los datos.
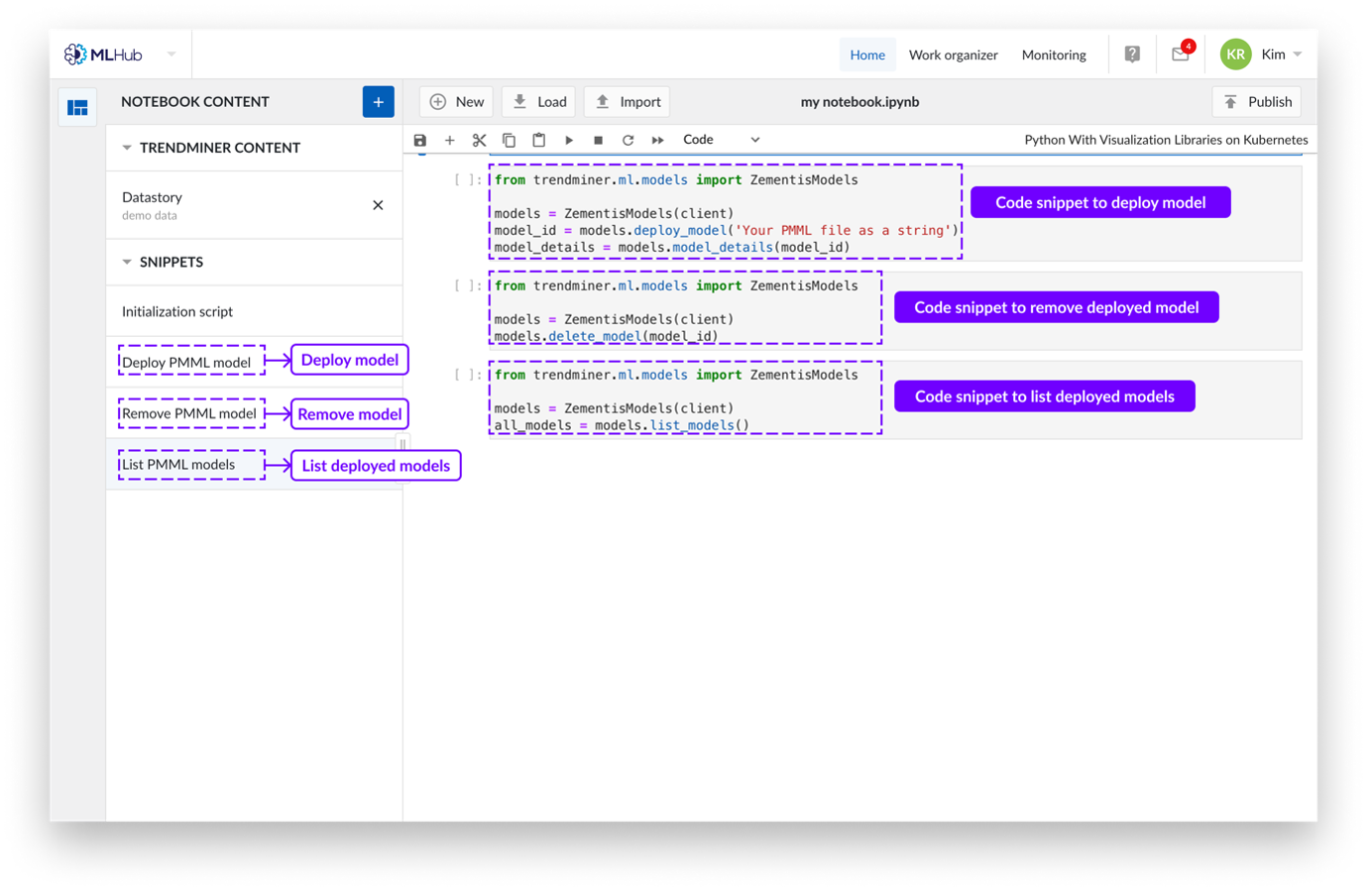
Fragmentos de Código
Actualmente los fragmentos son aplicables en kernels de python para desplegar modelos de machine learning.
Si tiene una celda de salida de Notebook con un resultado interesante o una visualización que desea compartir, puede publicarla en un objeto de pipeline de Notebook.
Pasos:
Pulse el botón "Publicar" en la esquina superior derecha.
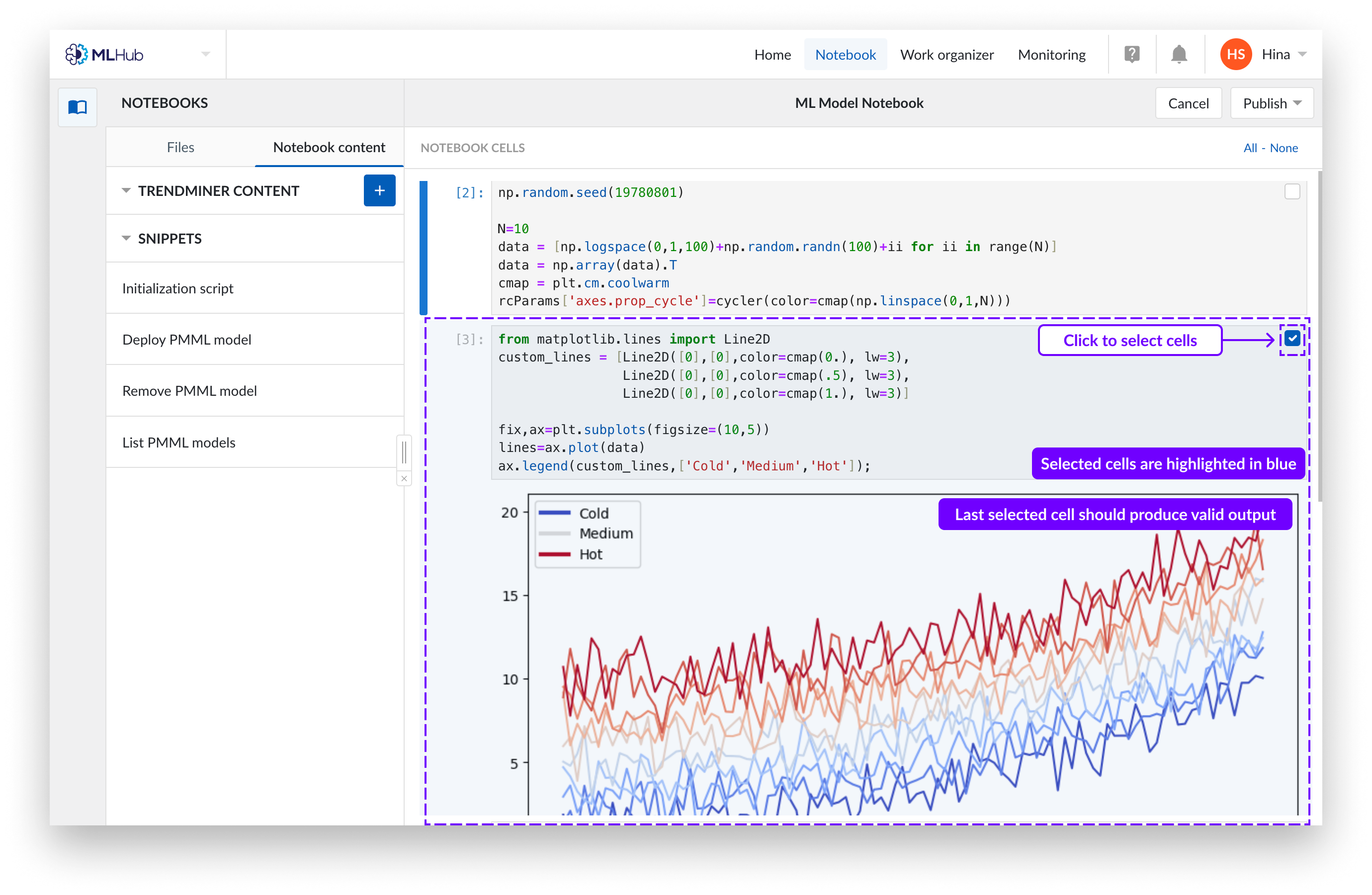
Seleccione TODAS las celdas que sean relevantes para la salida que desea publicar, incluidas las sentencias "import" y las declaraciones de variables. Asegúrese de que la última celda seleccionada produce una salida válida. Puede seleccionar una celda haciendo clic en cualquier lugar de la misma, o utilizar las casillas de verificación de las esquinas superiores derechas.
Puede publicar un Notebook en un nuevo pipeline o sobrescribir un pipeline existente.
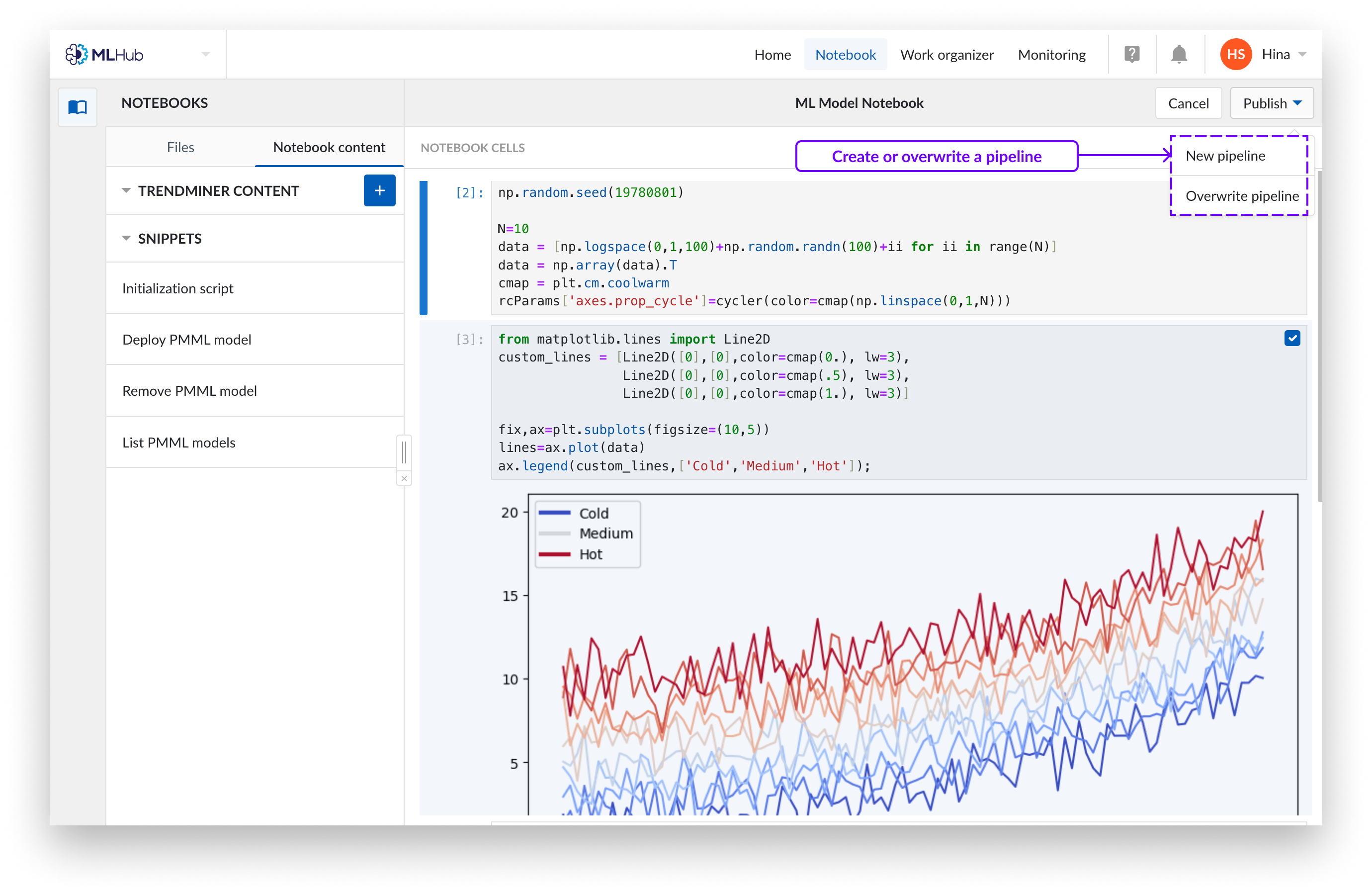
Para publicar Notebook en un nuevo pipeline, rellene el nombre y especifique la ubicación de almacenamiento en el Organizador de trabajo. Haga clic en "Publicar" para confirmar la selección. Esto creará un objeto "pipeline", que es un mini cuaderno que contiene sólo las celdas seleccionadas. Las pipelines no tienen ninguna relación con sus cuadernos originales, son una entidad independiente.
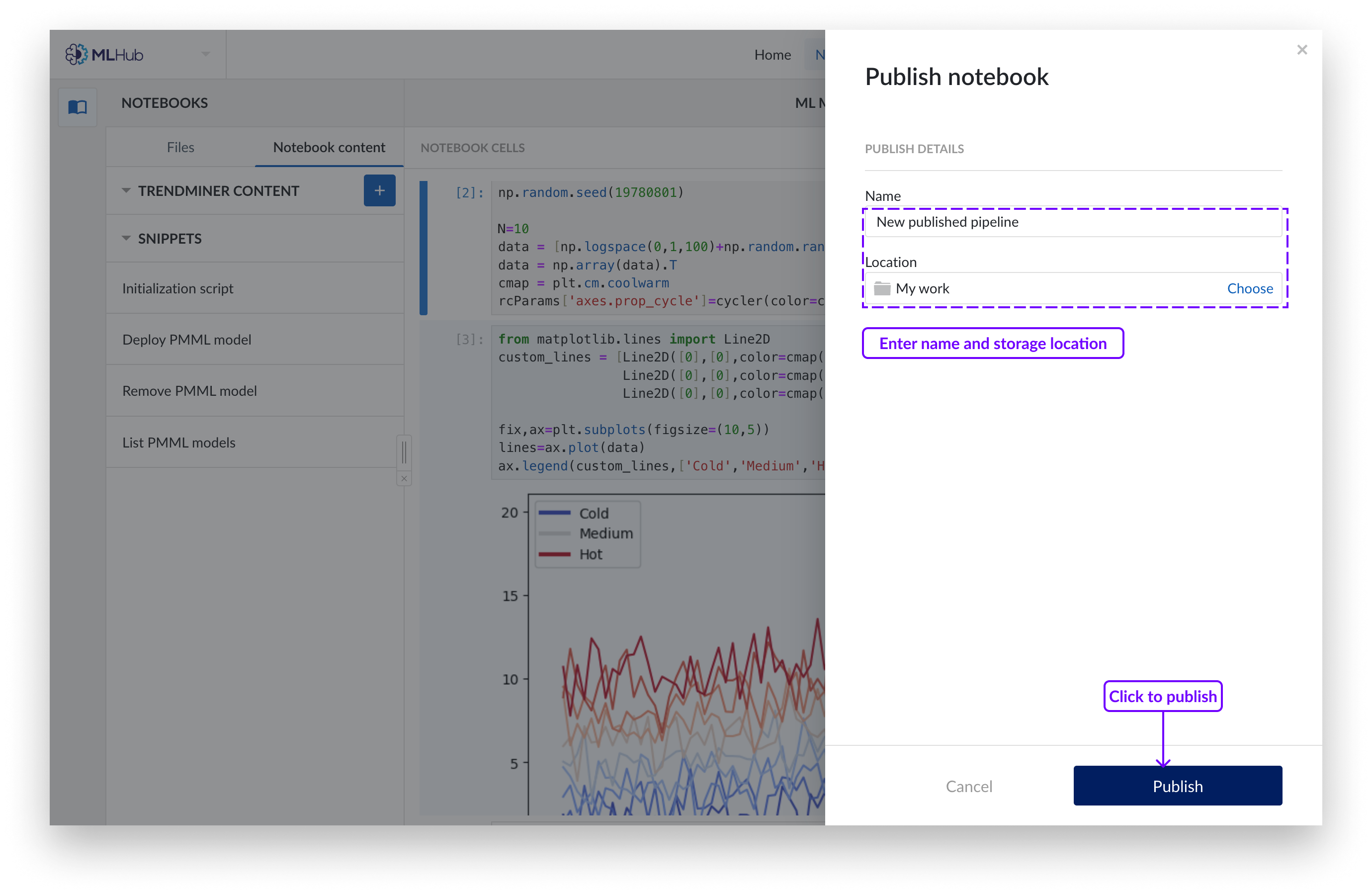
Nota
Si actualiza un Notebook, tendrá que crear también un nuevo objeto pipeline.
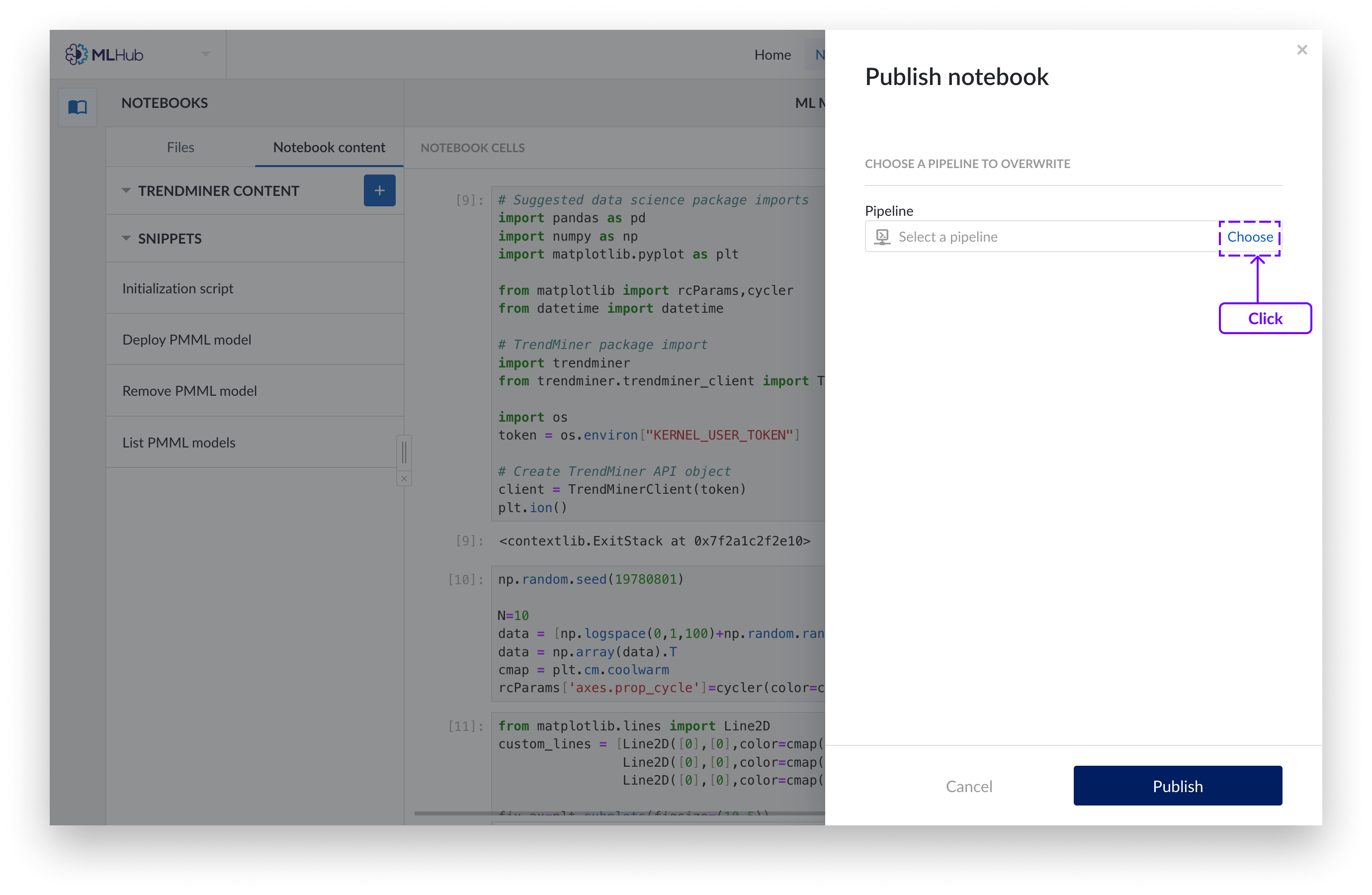
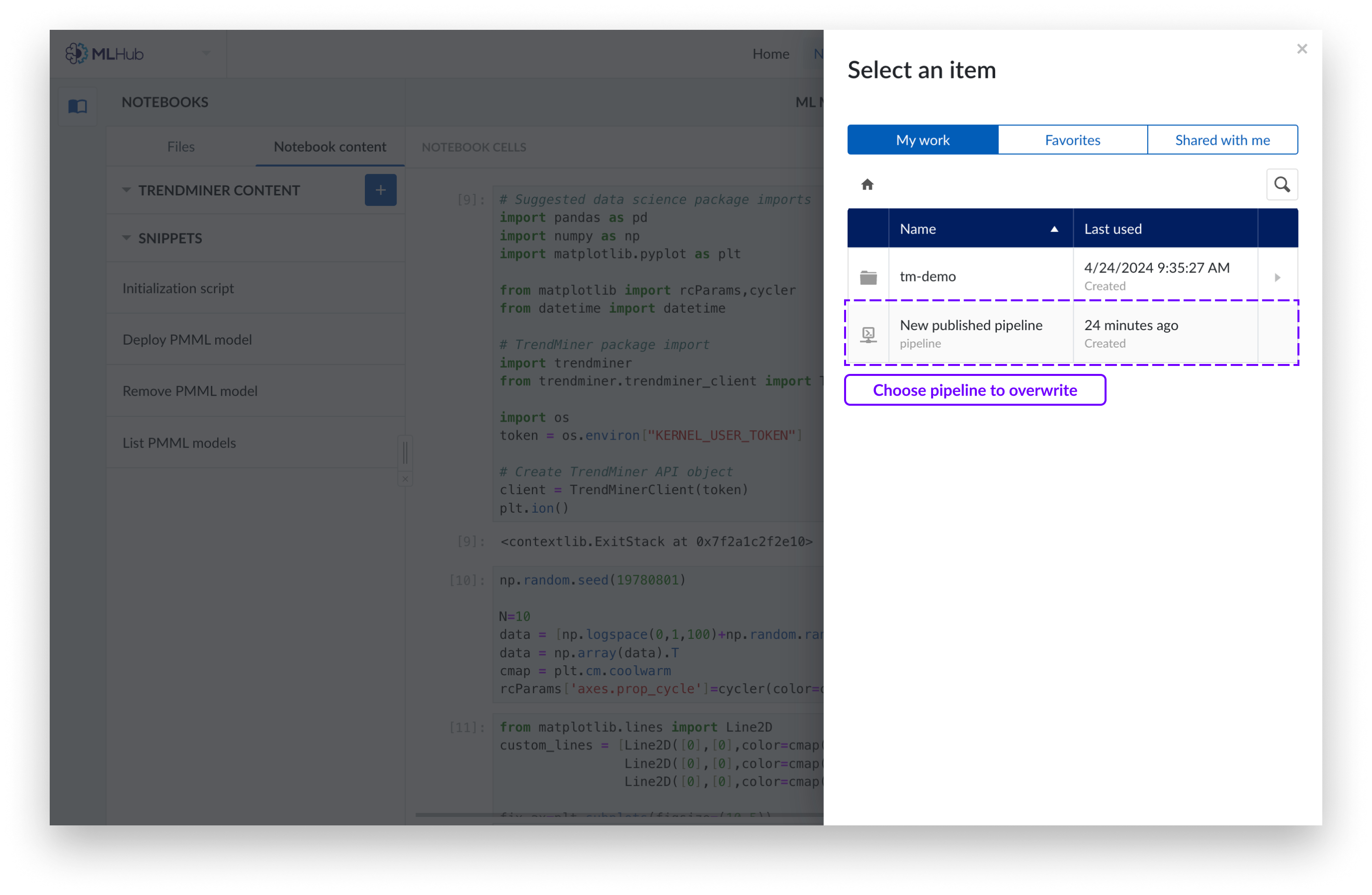
Si desea sobrescribir un pipeline existente, añada una descripción opcional y elija el pipeline del Organizador de trabajo que desea sobrescribir. Haga clic en «Publicar».
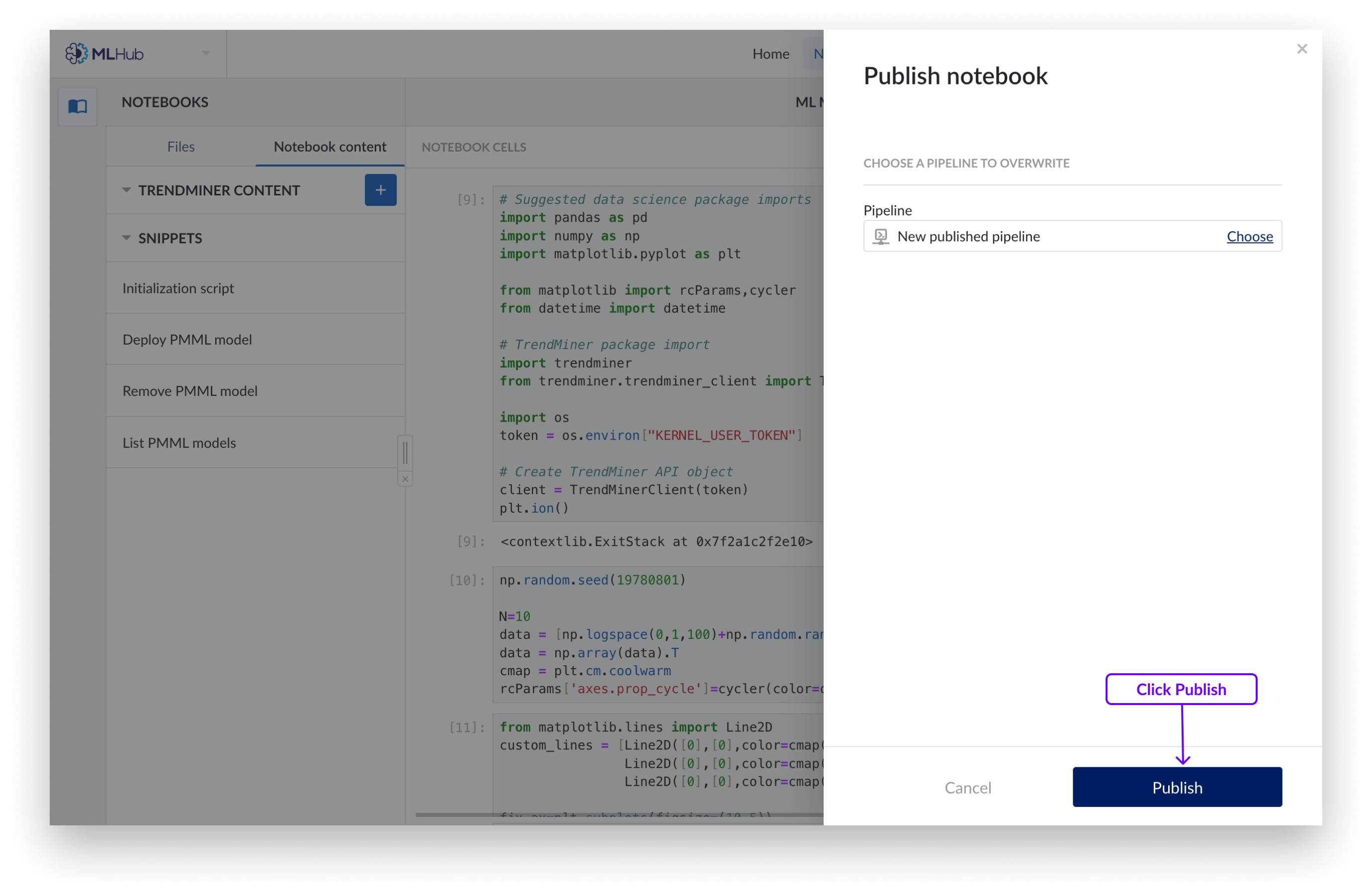
Ahora tendrá un objeto pipeline que contiene el código de las celdas que ha seleccionado.
DashHub permite mostrar cualquier salida de un Párrafo de Notebook en una Ventana de Dashboard de Notebook.
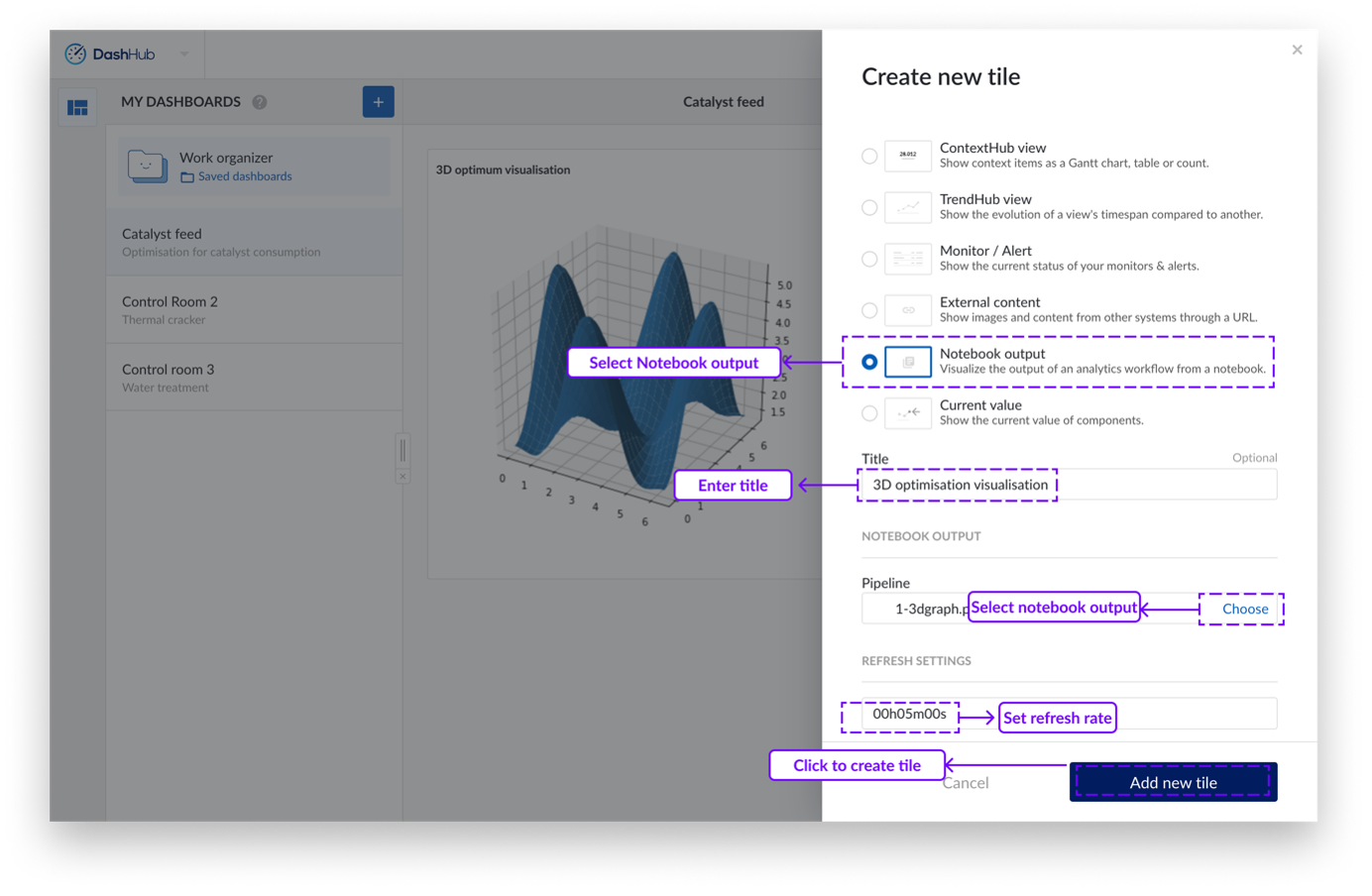
Creación de una Ventana de Notebook
Vaya a DashHub y cree un nuevo Dashboard o abra un Dashboard creado anteriormente.
Haga clic en el botón "Acciones". Aparecerá un menú desplegable.
Haga clic en "Añadir nueva Ventana". Aparecerá un panel lateral por la derecha.
Haga clic en la opción "Salida de Notebook".
Proporcione un título para la ventana en el Dashboard.
Seleccione el objeto de pipeline del Organizador de trabajo.
Ajuste la tasa de refresco si es necesario.
Haga clic en "Añadir nueva Ventana".
Nota
Cuando se comparte una Ventana DashHub, también deben compartirse las vistas subyacentes y los objetos de pipeline del notebook.
Al compartir un Notebook se creará un enlace simbólico al notebook original. Esto significa que el creador sigue siendo el propietario de los datos maestros del notebook. Los cambios realizados en las celdas se guardan según el principio FIFO y sólo se actualizarán al refrescar la pantalla.
Los objetos de salida de los pipeline publicados ya no están vinculados a los notebooks originales. Una vez publicados, los cambios en el notebook no repercutirán automáticamente en el objeto pipeline del notebook existente. Esto permite a los usuarios ajustar con precisión las salidas de las celdas de los notebooks, sin afectar a otros usuarios/visualizadores.
Los Notebooks y las visualizaciones de los resultados de los Notebooks se ejecutan en función de sus permisos y privilegios. Eso significa que algunas fuentes de datos pueden estar bloqueadas, y que sólo podrá procesar datos en función de su función.