Machine Learning Hub et Notebooks
Qu'est-ce que le Machine Learning Hub ?
La vision de TrendMiner pour démocratiser l'analyse va au-delà de la simple mise à disposition d'outils en libre-service pour les experts du domaine, et inclut également une collaboration plus étroite entre une variété d'experts pour résoudre les problèmes. Certains des problèmes les plus complexes nécessitent la participation de Data Scientists qui apportent des techniques spécialisées permettant aux entreprises d'extraire des données disponibles les informations les plus approfondies. Pensez statistiques avancées et modèles d'apprentissage automatique.
Avec MLHub, les Data Scientists peuvent accéder aux données TrendMiner (aussi bien les données brutes que les données prétraitées et contextualisées dans les vues TrendMiner) et valider des hypothèses ou créer/entraîner/déployer des modèles d'apprentissage automatique dans le nouvel environnement Notebook, que d'autres utilisateurs peuvent appliquer grâce aux tags Machine Learning et visualiser dans DashHub.
Comment utiliser la vue du Notebook de MLHub ?
Important
L'accès à MLHub n'est possible qu'après la mise en place de la gestion des accès, pour laquelle une licence distincte est nécessaire. Pour plus de détails concernant la gestion des accès, lisez ici. Contactez nous chez TrendMiner si vous avez besoin de plus d'informations concernant les licences.
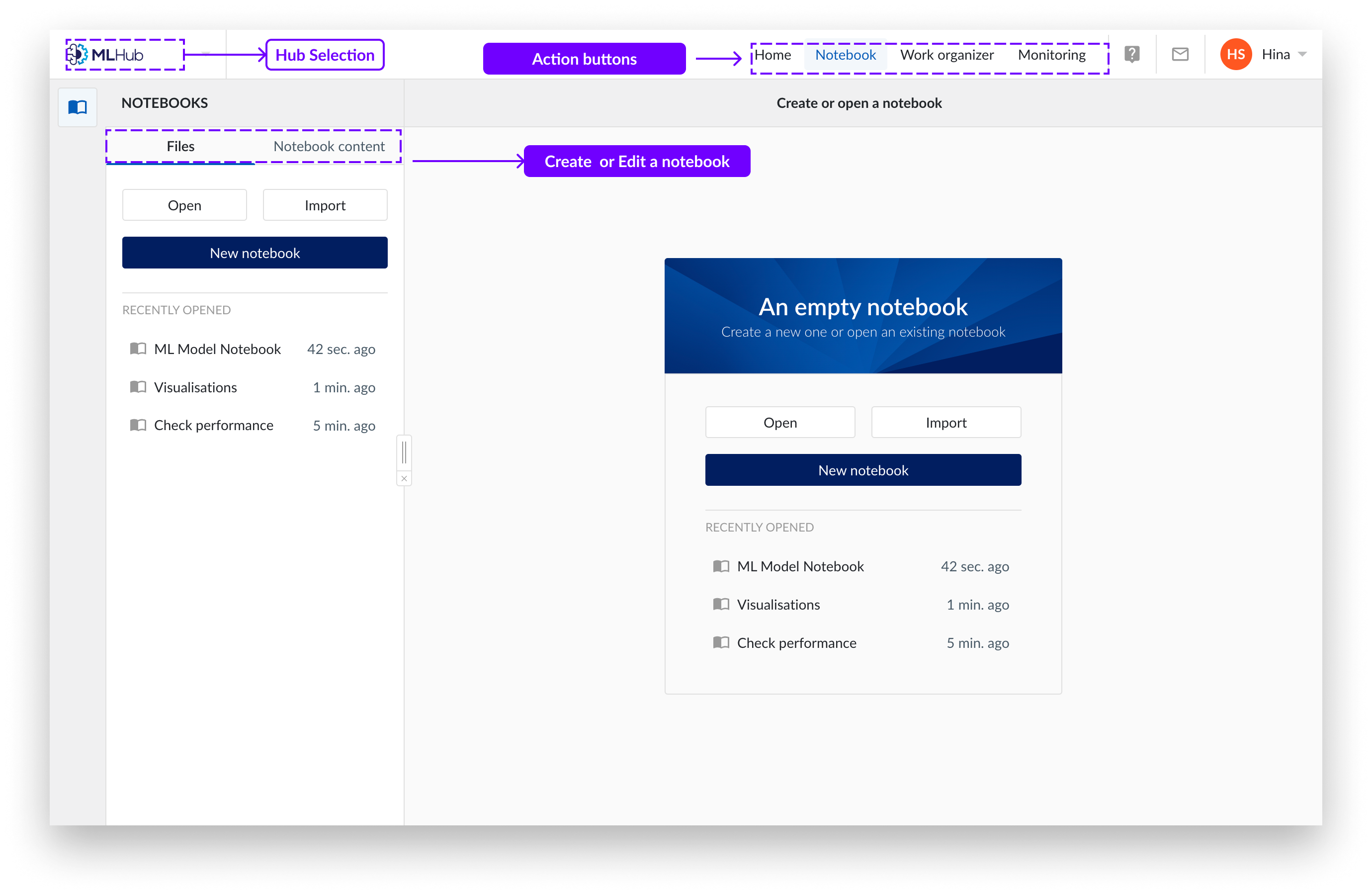
Dans le coin supérieur gauche de l'environnement TrendMiner, vous trouverez le bouton de sélection du hub. Ici, vous pouvez sélectionner le hub vers lequel vous souhaitez naviguer.
Cliquez sur le bouton "MLHub". Pour fermer l'écran d'accueil et accéder à la vue Notebook, cliquez sur Notebook dans la barre supérieure.
La barre supérieure vous permet de revenir à l'accueil, aux Notebooks, à l'Organiseur de travail et au Monitoring.
La fonctionnalité Notebook de TrendMiner est une plateforme qui permet aux utilisateurs de créer et de travailler avec des outils avancés au-delà des solides capacités intégrées, au sein de l'environnement TrendMiner.
Avec les Notebooks intégrés, vous pourrez :
Charger des données à partir d'une vue TrendHub, préparée à l'aide des capacités intégrées typiques de TrendMiner (sélectionner un ensemble de tags intéressants, sélectionner les périodes d'intérêt, par exemple via des recherches, …)
Visualiser et analyser vos données de différentes manières, qui ne sont pas possibles dans TrendMiner.
Effectuer l'automatisation des analyses via des scripts (par exemple, répéter l'analyse sur une large gamme d'installations).
Créer des tags (prédictifs) à l'aide de modèles personnalisés (par exemple, des réseaux neuronaux ou des clusters) pris en charge par les bibliothèques typiques de Notebook.
Vous pouvez utiliser des options de visualisation plus avancées qui sont intégrées au Notebook. Le Notebook est livré avec sa propre Vignette de Notebook, de sorte que vous pouvez également intégrer votre travail dans un tableau de bord DashHub et le mettre à la disposition de toute votre organisation.
Note
Interpréteur - L'interpréteur par défaut des Notebooks est Python.
Dans l'onglet Notebook de MLHub, vous pouvez soit créer un nouveau notebook, soit charger ou importer une note existante. Un nouveau Notebook sera toujours vide.
Entrez dans l'onglet Notebook de MLHub.
Cliquez sur « Nouveau Notebook ».
Remplissez les champs vides et sélectionnez un dossier pour stocker votre nouveau Notebook.
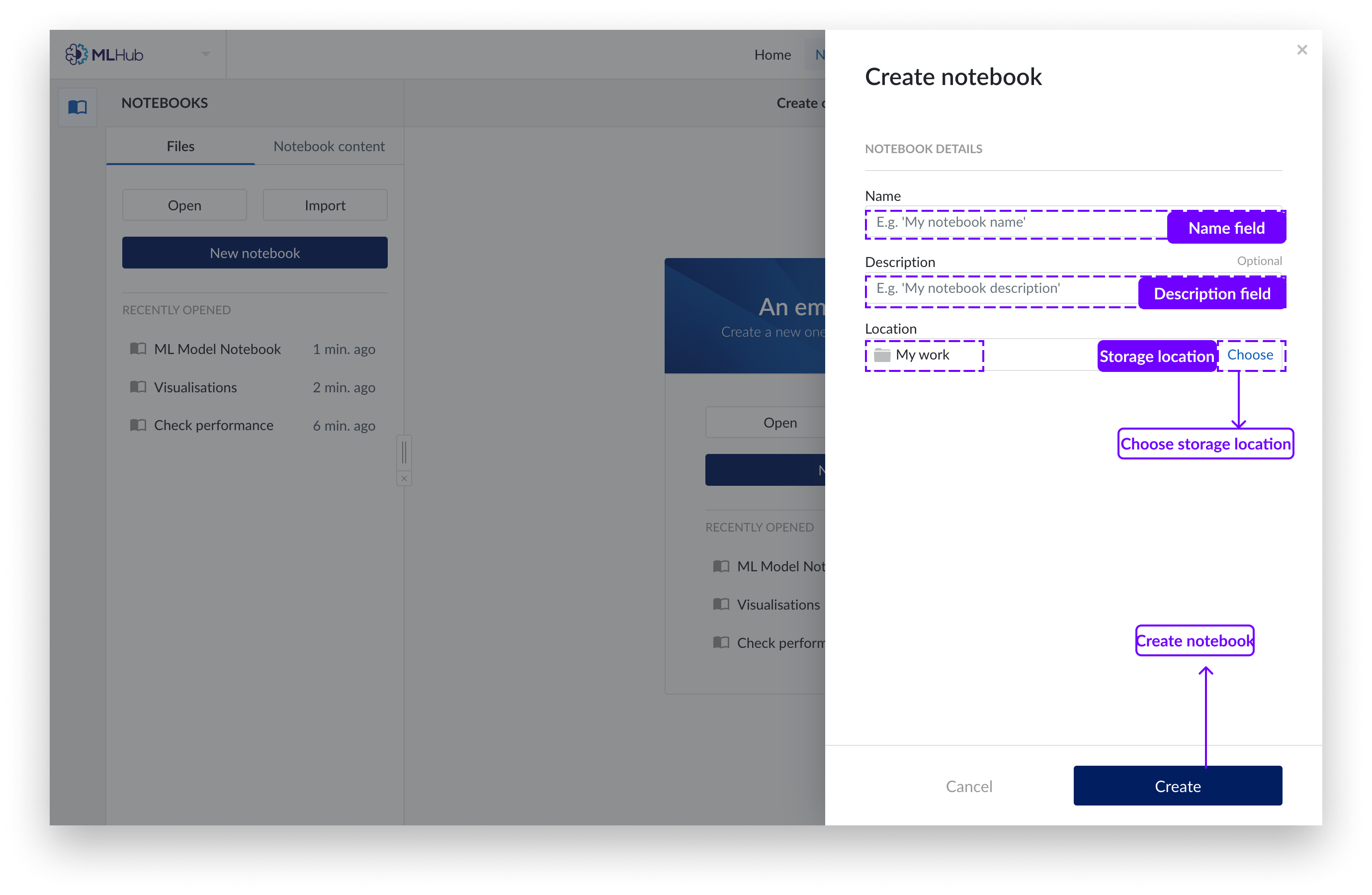
Cliquez sur le bouton "Créer".
Vous allez maintenant entrer en mode « Contenu du Notebook » avec des snippets dans le panneau latéral gauche. Il s'agit de blocs de code prédéfinis à utiliser dans vos notebooks. Voir « code snippets » ci-dessous pour plus de détails.
Choisissez la configuration du kernel que vous souhaitez lancer. Nous proposons des kernels incluant des packages de visualisation préinstallés. Nous vous recommandons de procéder au lancement avec le kernel « Python 3.11 on Kubernetes ».
Confirmez votre sélection en cliquant sur « Select ».
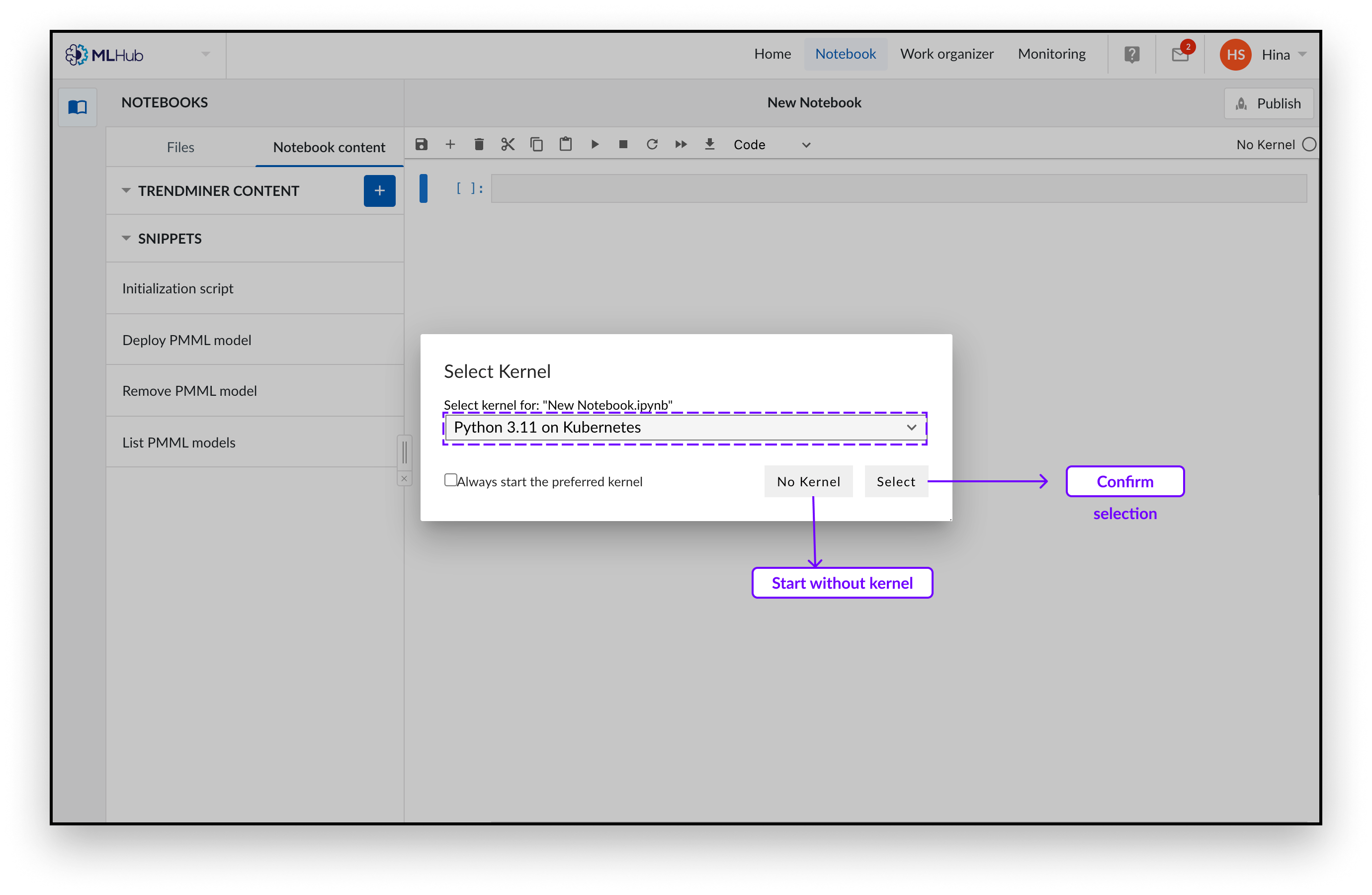
Un nouveau Notebook s'ouvre sur lequel vous pouvez écrire votre code python. Vous voudrez peut-être introduire notre code d’initialisation qui charge les paquets hautement recommandés, car vous en aurez besoin pour lire le contenu de TrendMiner. Vous pouvez ajouter ce code en cliquant sur le bouton "Initialization script" dans le menu à gauche.
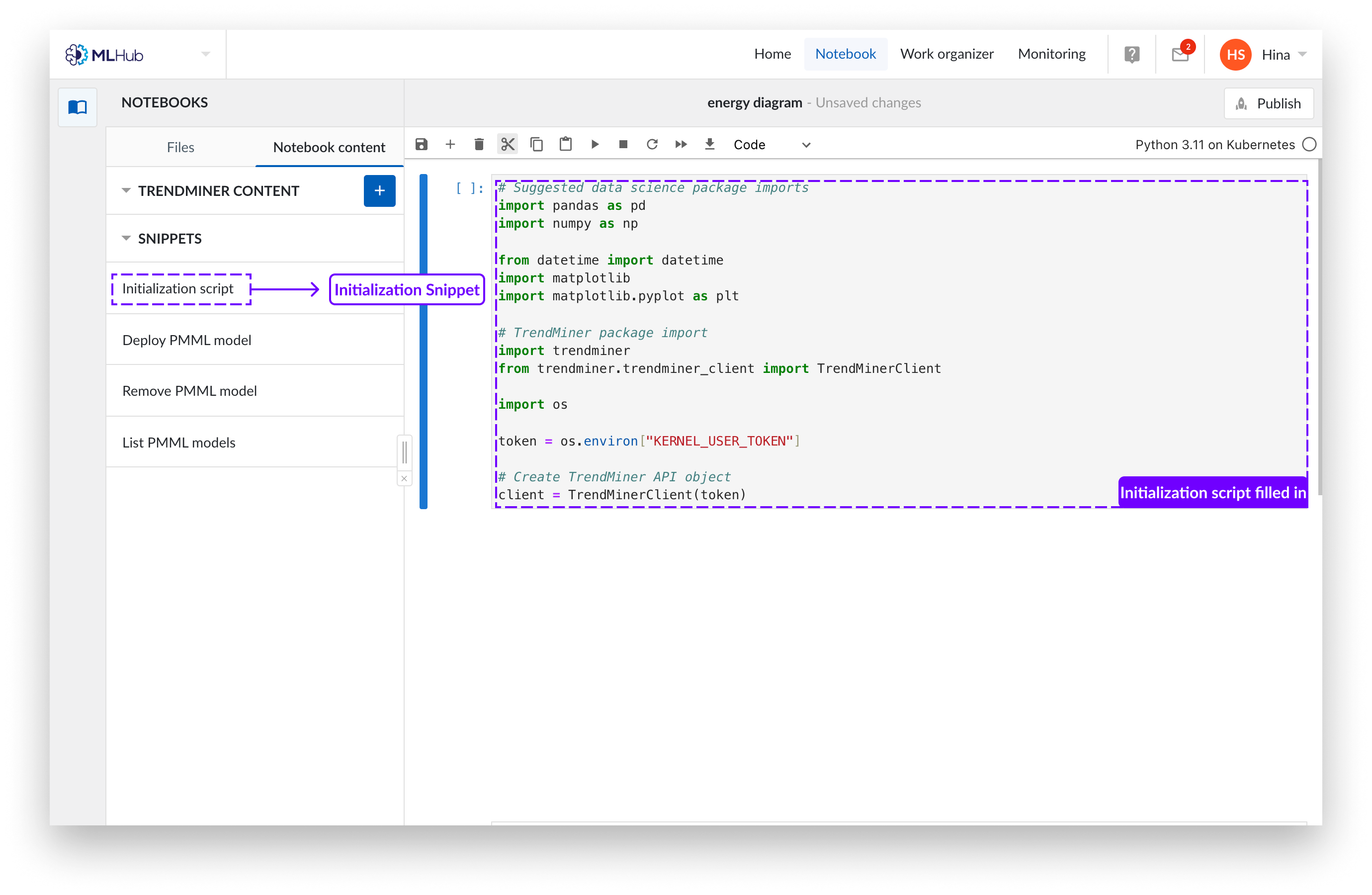
Ouverture d'un Notebook
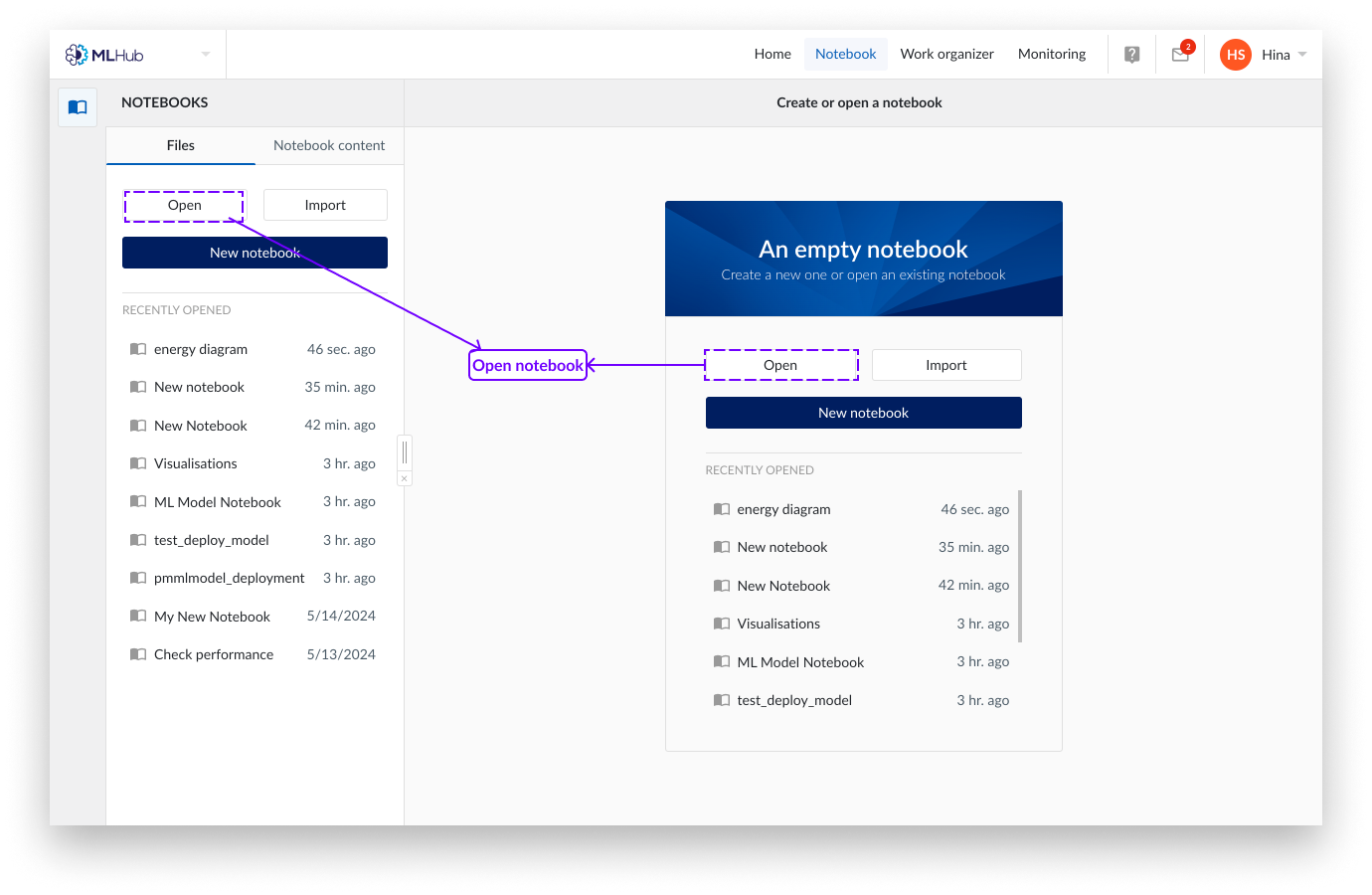
Cliquez sur l'onglet « Files » de MLHub.
Cliquez sur « Ouvrir ».
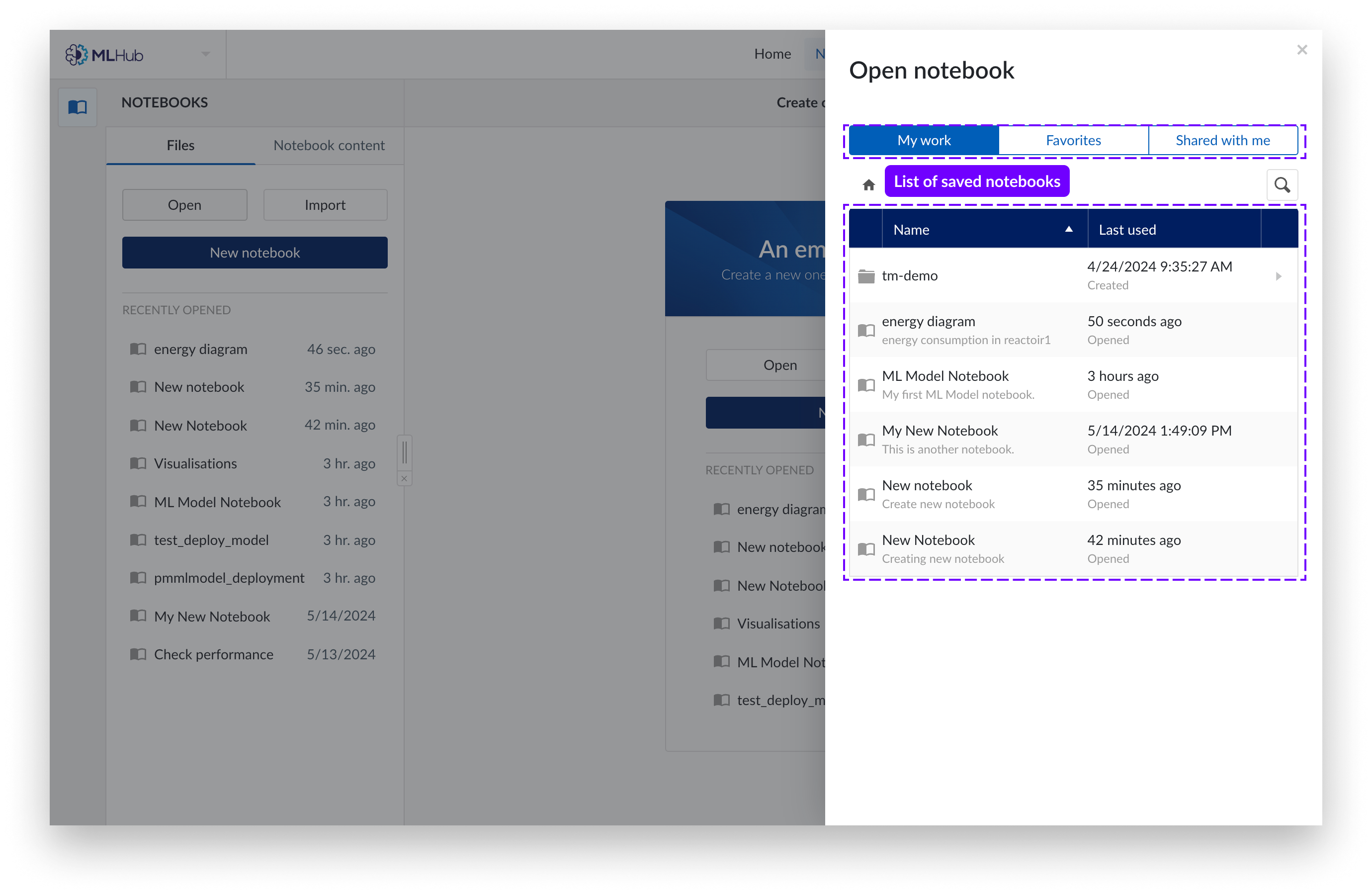
Vous pouvez maintenant voir vos Notebooks dans « Mon travail » ou « Favoris » . Cliquez sur le Notebook que vous souhaitez ouvrir.
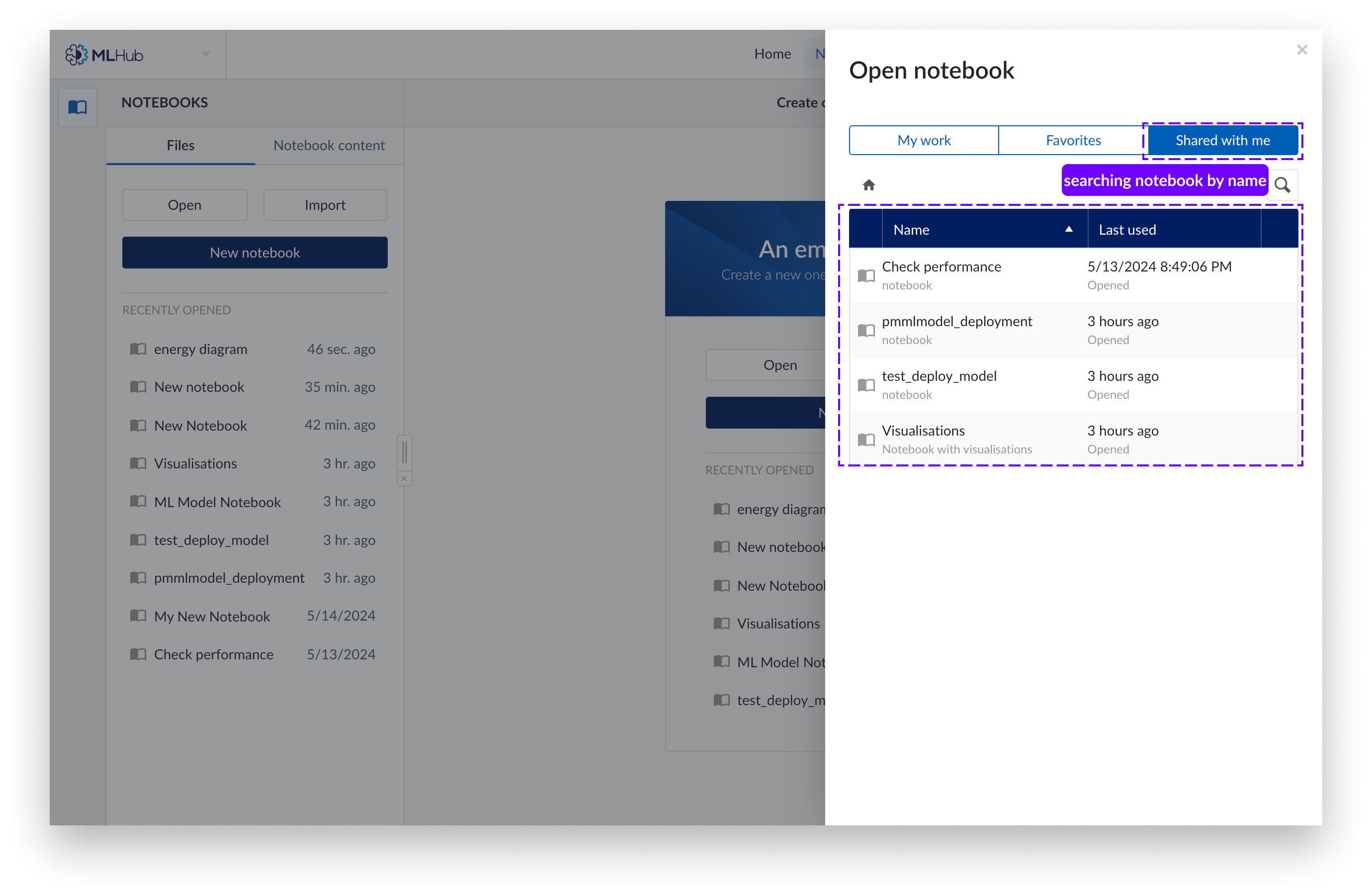
Vous pouvez également accéder aux Notebooks partagés avec vous par d'autres utilisateurs dans « Partagés avec moi » .
Cliquez sur l'onglet « Files » de MLHub.
Cliquez sur le bouton "Importer".
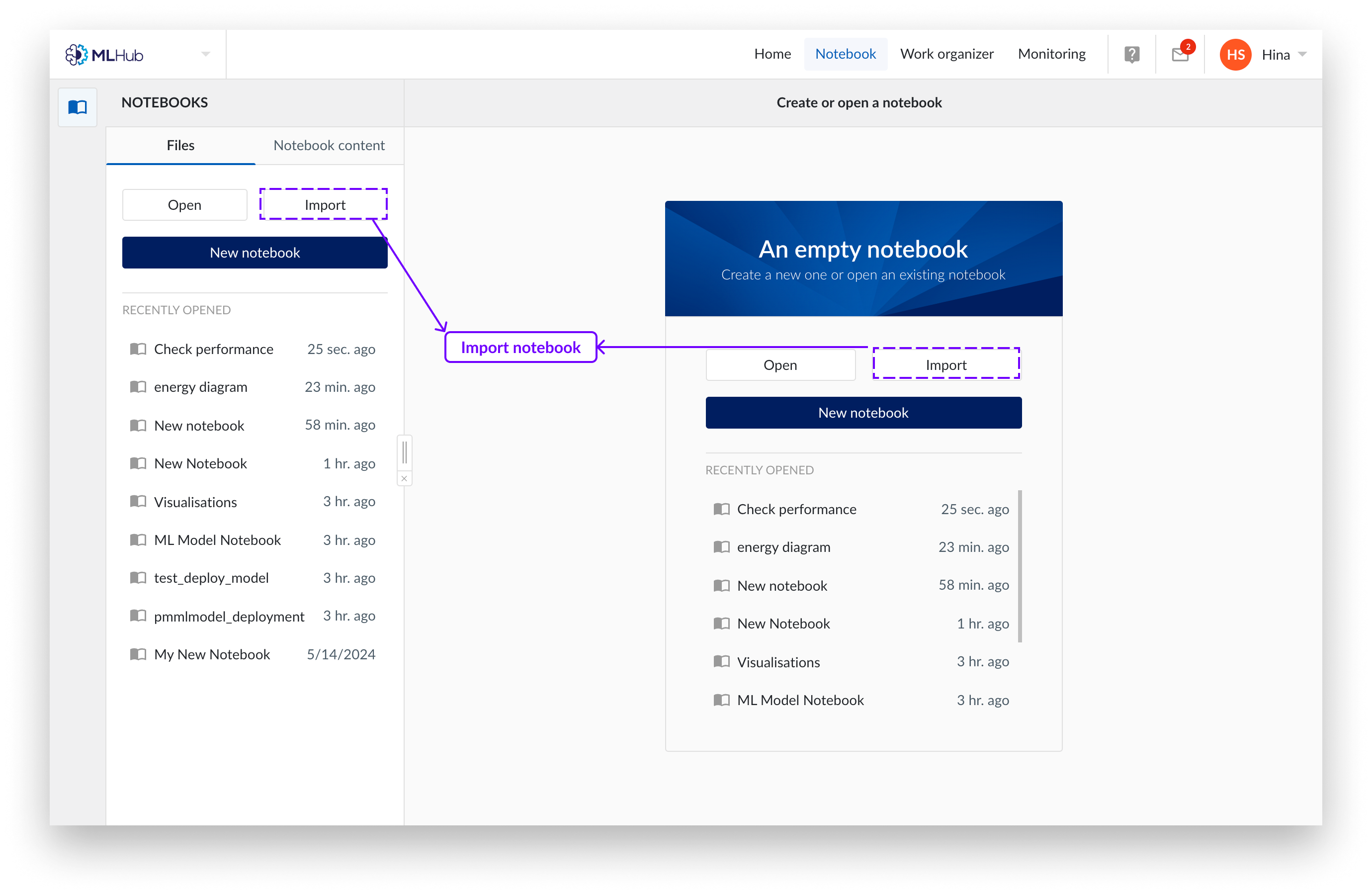
Un panneau apparaît à droite de l'écran. Choisissez de télécharger un Notebook avec votre système de navigateur de fichiers local ou choisissez d'utiliser l'Organiseur de travail. Seuls les Notebooks Jupyter (extension de fichier .ipynb) sont pris en charge.
Sélectionnez "importer".
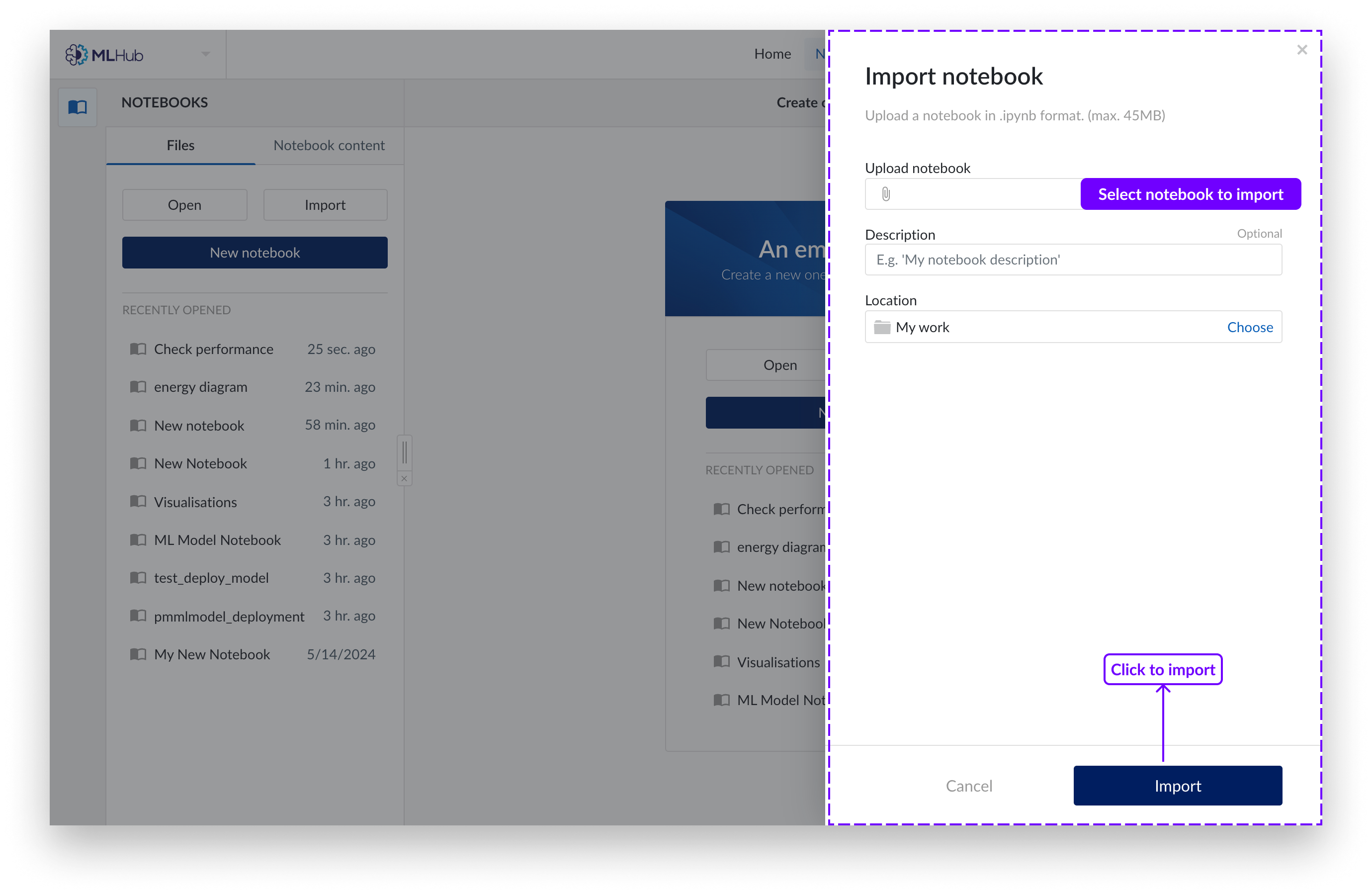
Note
À partir de la version 2022.R2, seules les "Vues TrendHub" et les "Vues ContextHub" sont disponibles comme contenu TrendMiner. D'autres contenus seront introduits dans les versions ultérieures.
Vous pouvez charger des vues TrendHub ou ContextHub, par exemple des périodes de bon fonctionnement et/ou de fonctionnement anormal. Puis les comparer à l'aide d'analyses avancées en les ajoutant à votre liste de CONTENUS TRENDMINER.
Cliquez sur le bouton bleu "+". Un panneau latéral apparaîtra sur la droite.
Sélectionnez la (les) vue(s) enregistrée(s) que vous souhaitez ajouter en tant qu'ensemble de données.
Cliquez sur "Charger".
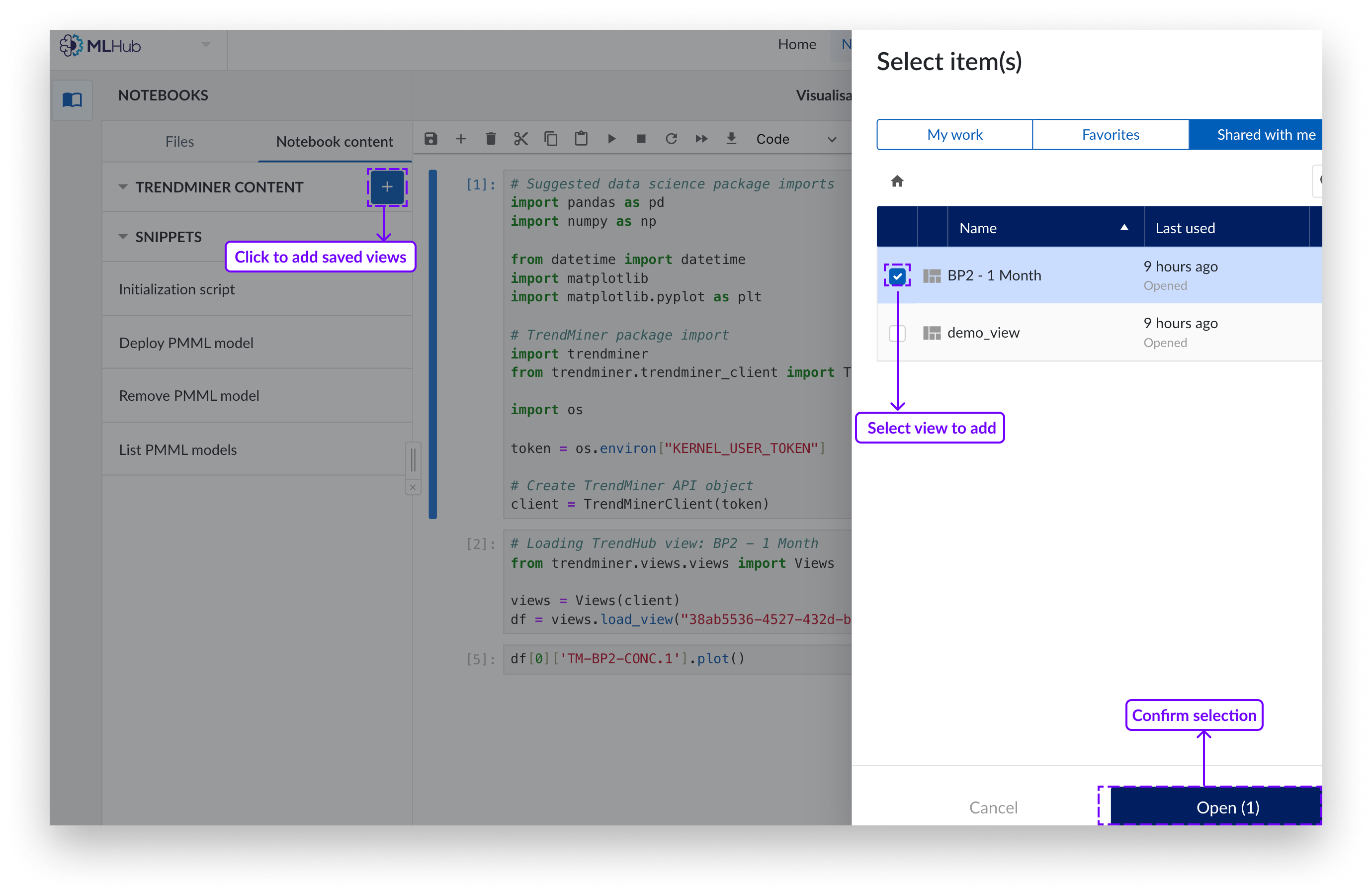
Les éléments de la liste du menu de contenu peuvent être ouverts ou supprimés. Pour supprimer, cliquez sur le "x" à droite de l’élément à supprimer.
Cliquez sur le nouveau contenu pour l'ouvrir. Cela ajoutera le code python correspondant dans une nouvelle cellule à la fin du Notebook.
Vous pouvez obtenir plus d'informations en exécutant la commande suivante dans le Notebook:
help(trendminer.dataframes.data_frames)
load_view( ) : Charge les données de séries temporelles d'une vue TrendHub enregistrée dans une liste de DataFrames Pandas.
Un DataFrame est renvoyé par calque dans la vue.
Chaque DataFrame peut avoir un ensemble différent de tags disponibles.
Les paramètres facultatifs [layer_ids] vous permettent de ne charger qu'une liste spécifique de calques (identifiées par les identifiants de calque, tels que fournis par la fonction view_info).
view_info( ) : Collecte les informations sur une vue en fonction de son ID. Cette info peut être utilisée pour récupérer les données d'une vue : elle liste tous les calques qui sont inclus dans la vue. Lorsque vous récupérez des données à partir de la vue, vous pouvez sélectionner les calques à inclure dans les données.
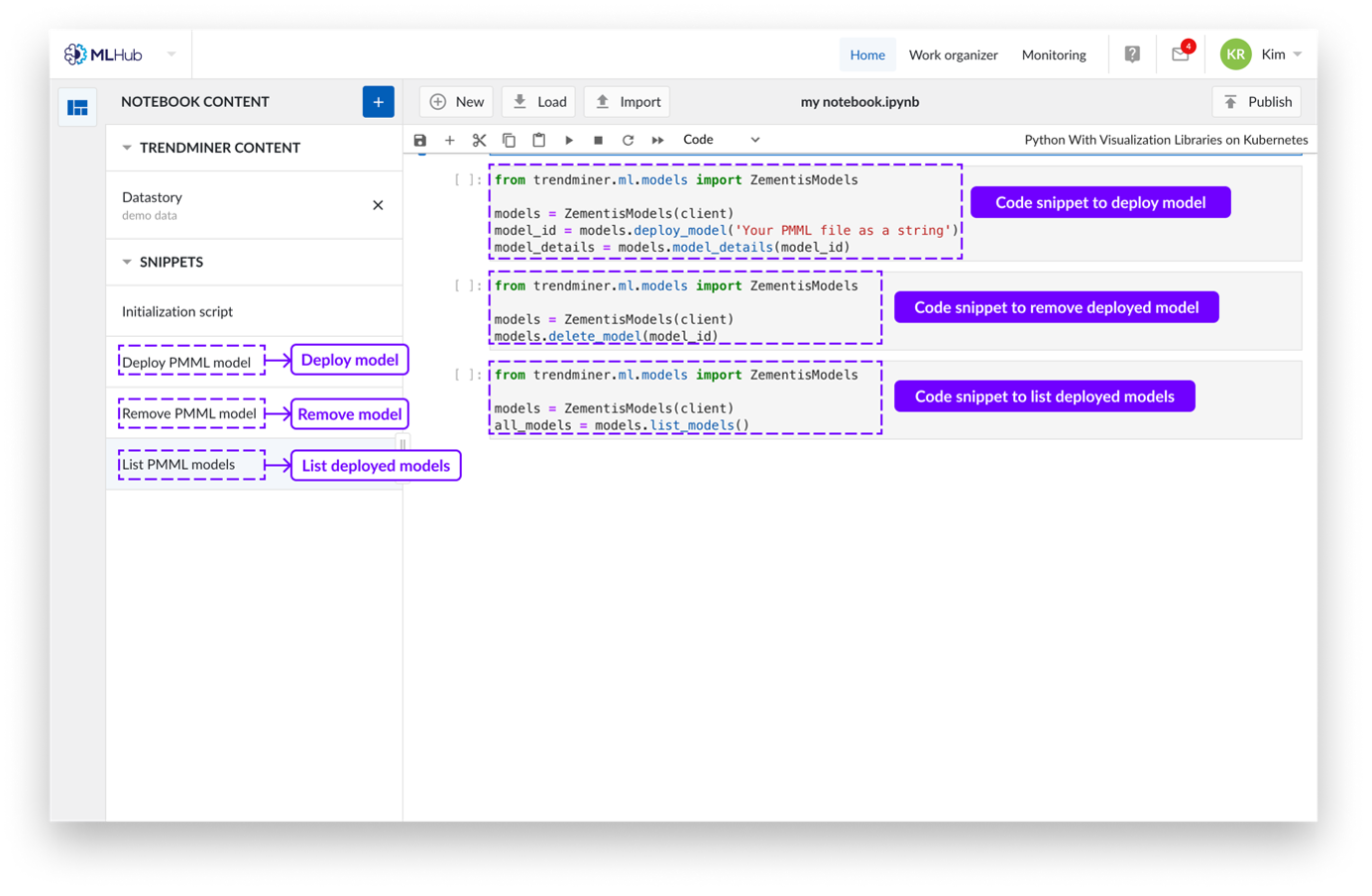
Snippets
Actuellement, les snippets sont applicables dans les kernels python pour déployer des modèles de Machine Learning.
Si vous avez une cellule de sortie de Notebook avec un résultat ou une visualisation intéressante que vous voulez partager, vous pouvez la publier dans un objet de sortie de Notebook.
Des pas :
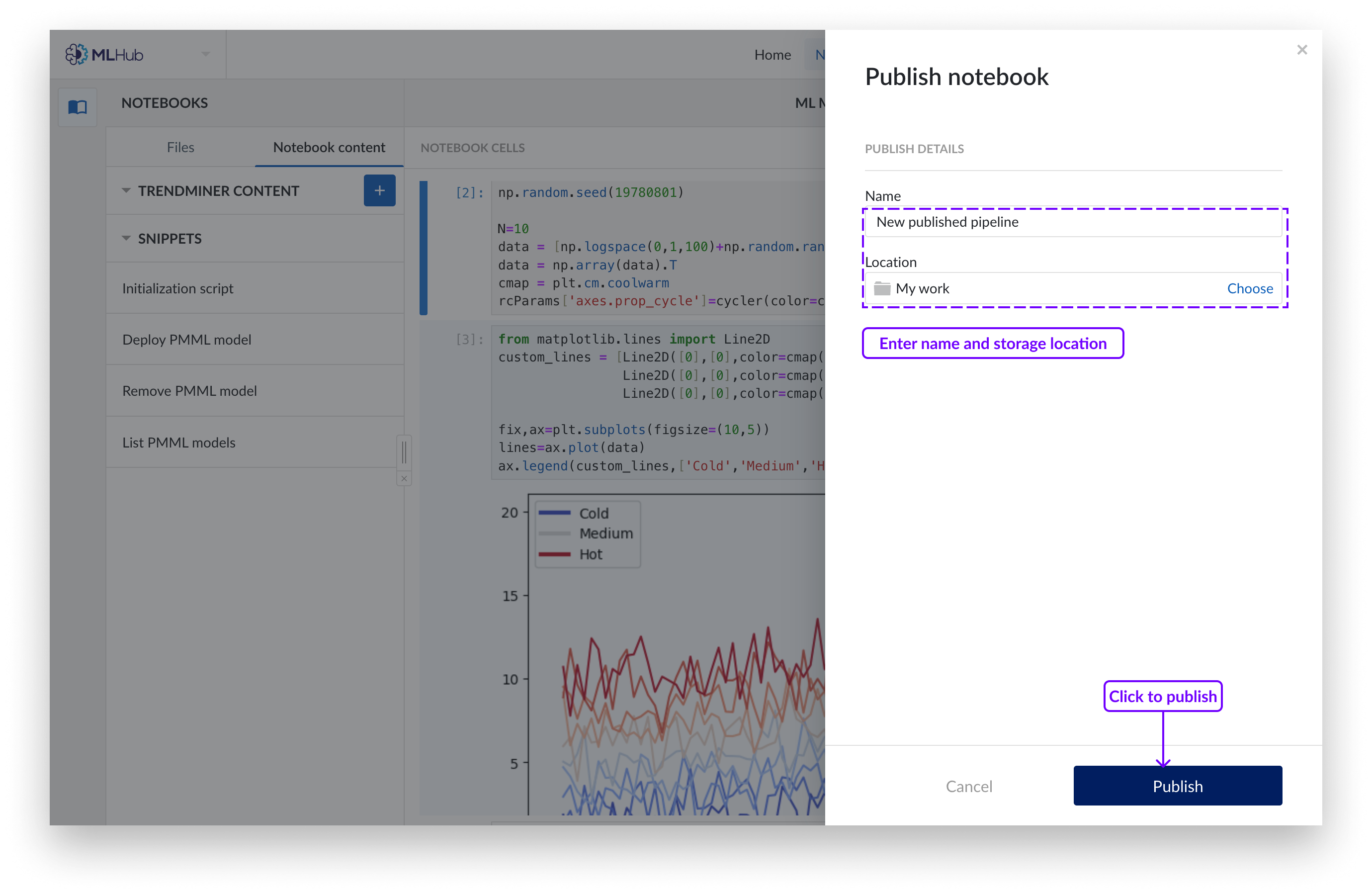
Cliquez sur le bouton "Publier" dans le coin supérieur droit.
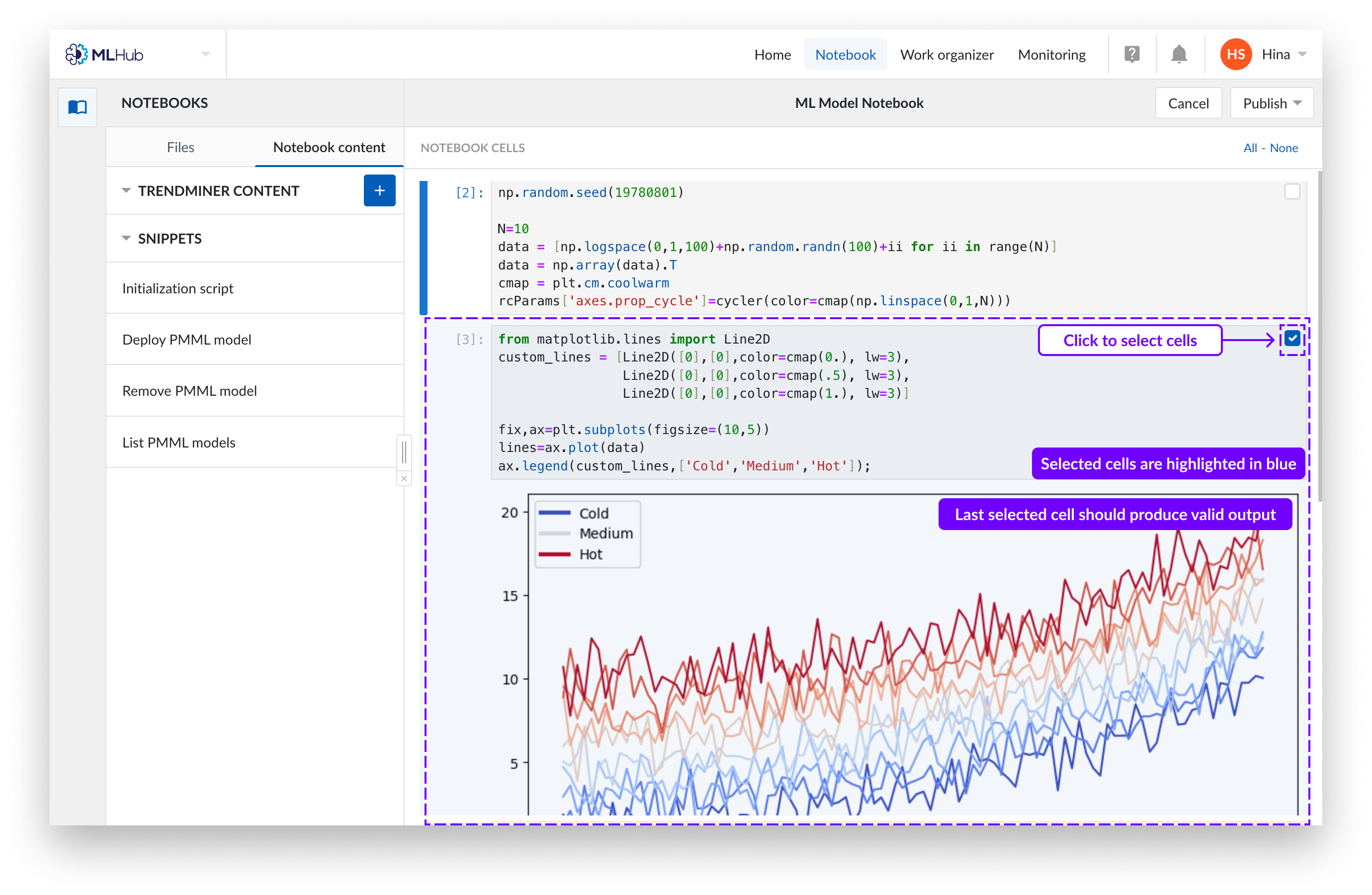
Sélectionnez TOUTES les cellules qui sont pertinentes pour le résultat que vous voulez publier, y compris les déclarations d'importation et les déclarations de variables. Assurez-vous que la dernière cellule sélectionnée produit une sortie valide. Vous pouvez sélectionner une cellule en cliquant n'importe où sur celle-ci, ou utiliser les cases à cocher dans les coins supérieurs droits.
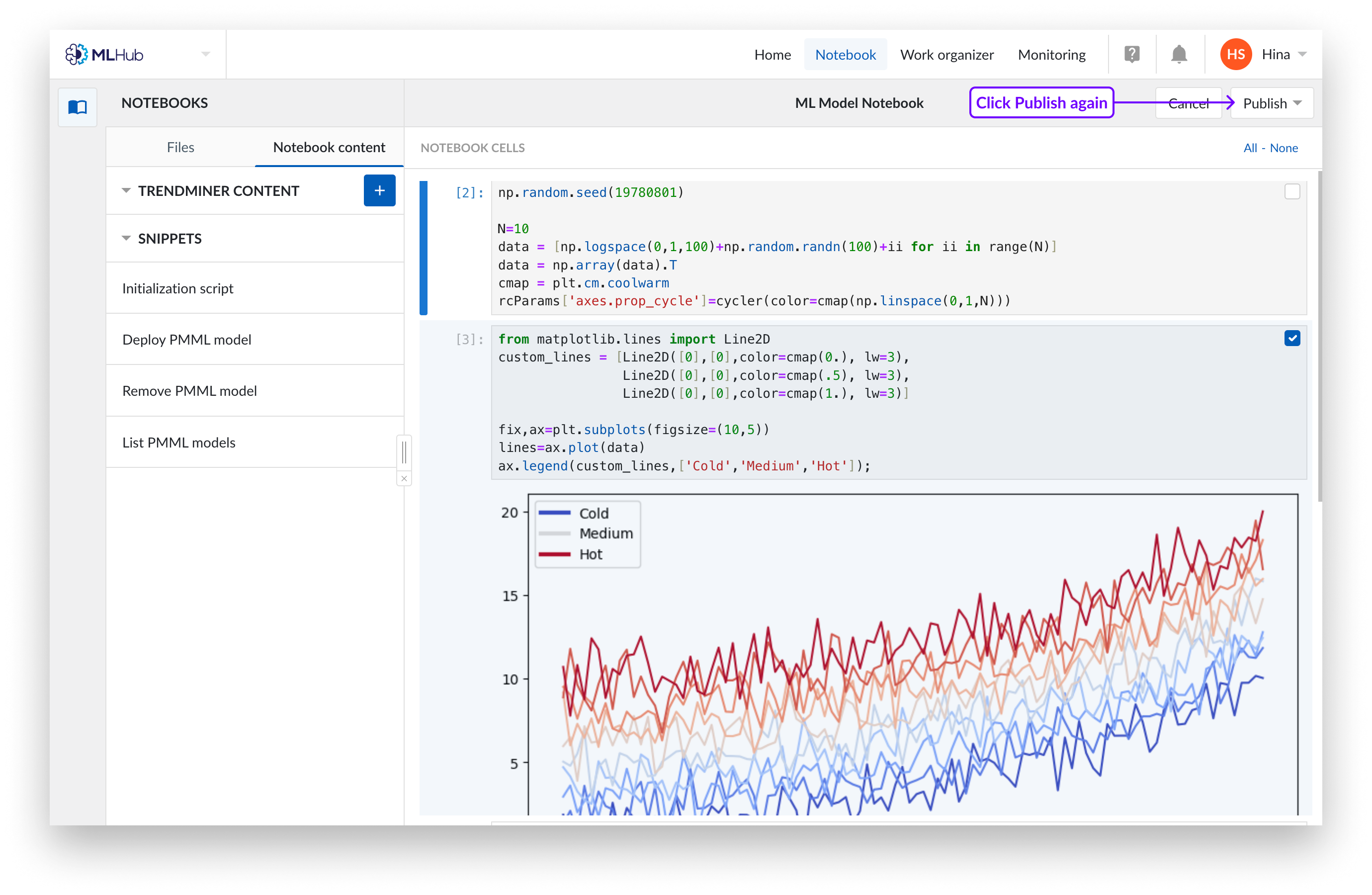
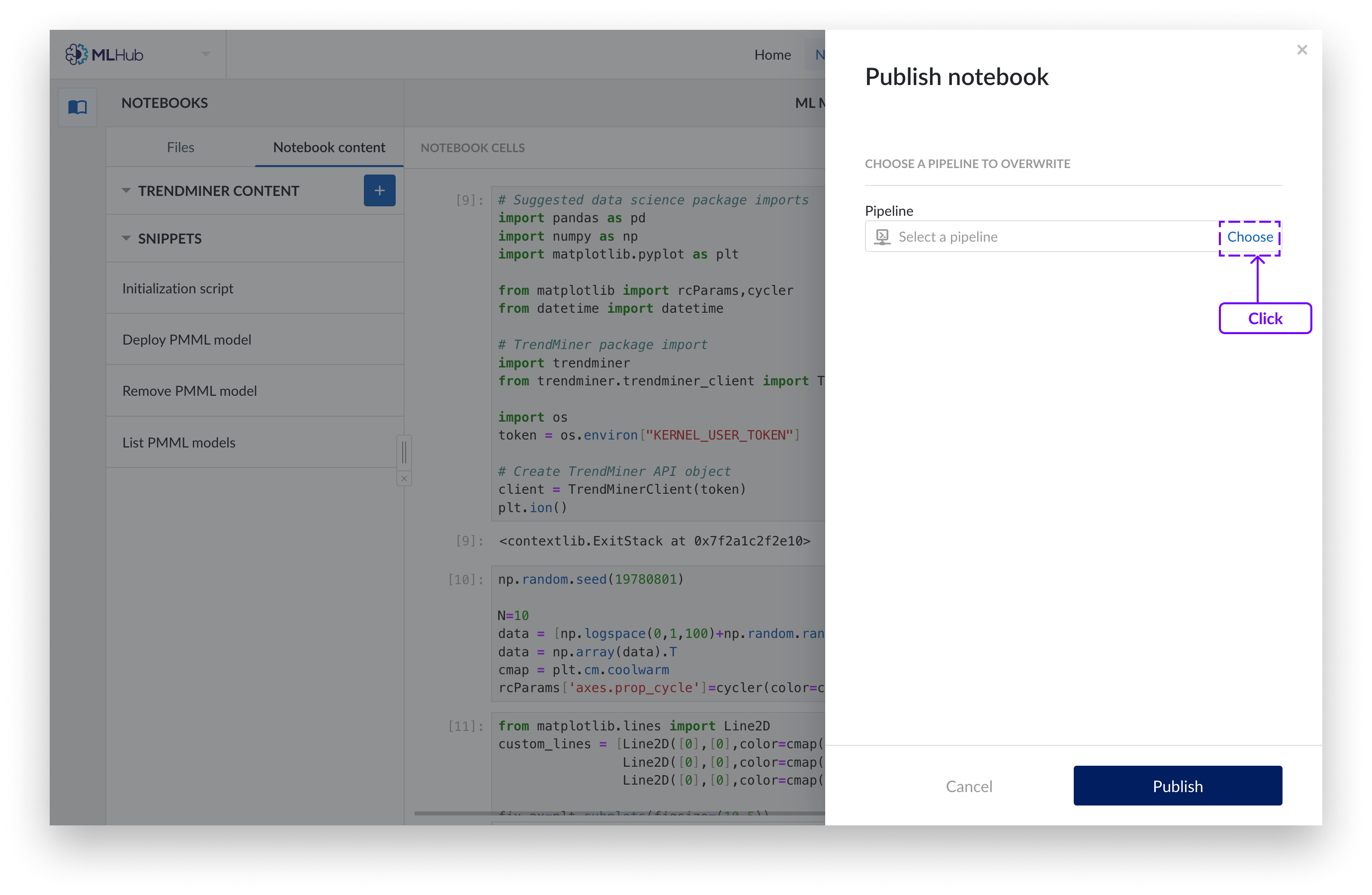
Vous pouvez publier le Notebook sur un nouveau pipeline ou écraser un pipeline existant.
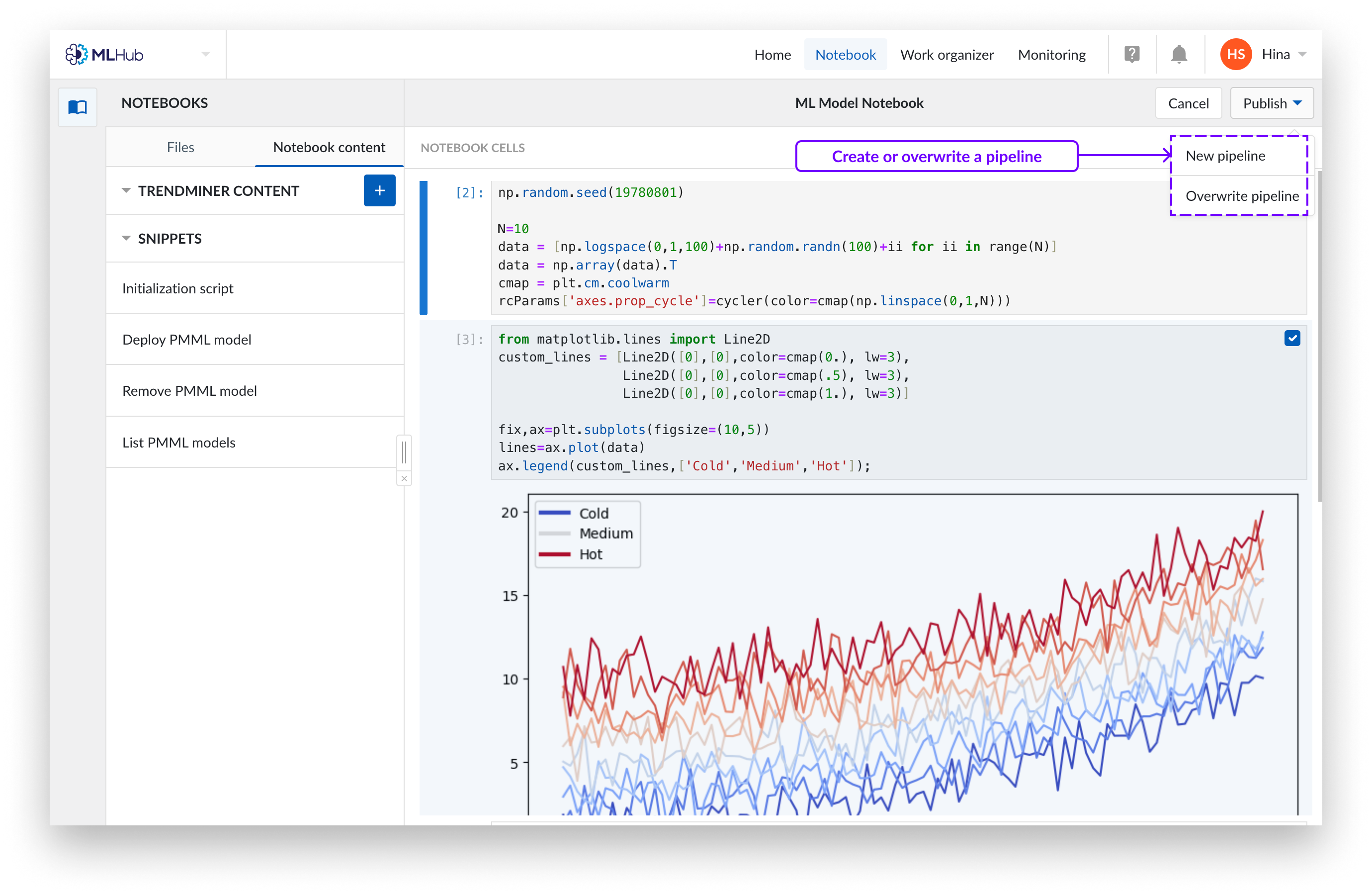
Pour publier le Notebook sur un nouveau pipeline, remplissez le nom et spécifiez l'emplacement de stockage dans l'Organizador de trabajo. Cliquez sur "Publier" pour confirmer la sélection. Cela créera un objet "pipeline", qui est un mini carnet de notes contenant uniquement les cellules sélectionnées. Les pipelines n'ont aucune relation avec leurs Notebooks d'origine, ils constituent une entité distincte.
Note
Si vous mettez à jour un Notebook, vous devrez également créer un nouvel objet pipeline.
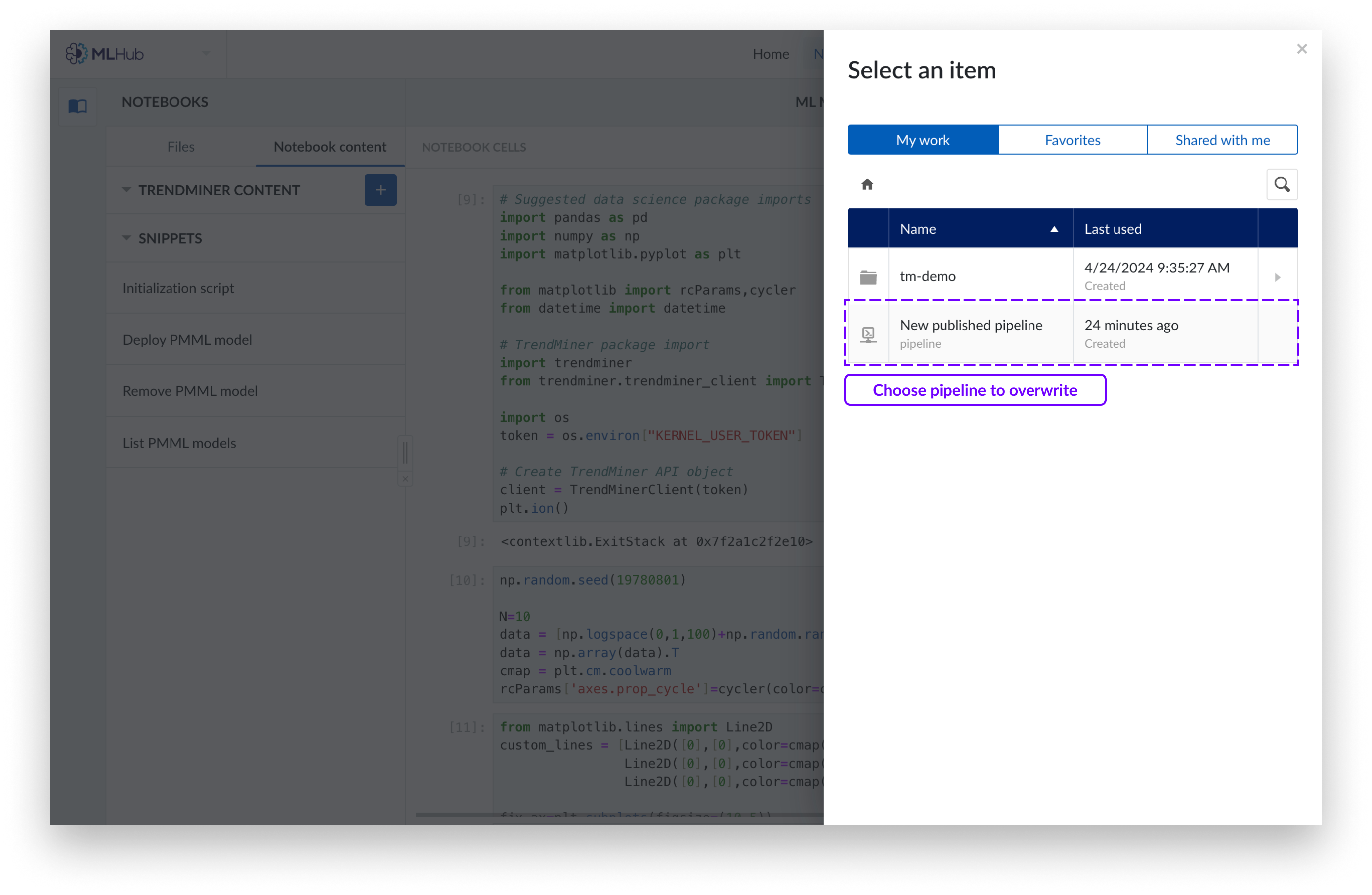
Si vous souhaitez remplacer une canalisation existante, ajoutez une description facultative et choisissez la canalisation dans l'Organiseur de travail que vous souhaitez remplacer. Cliquez sur « Publier ».
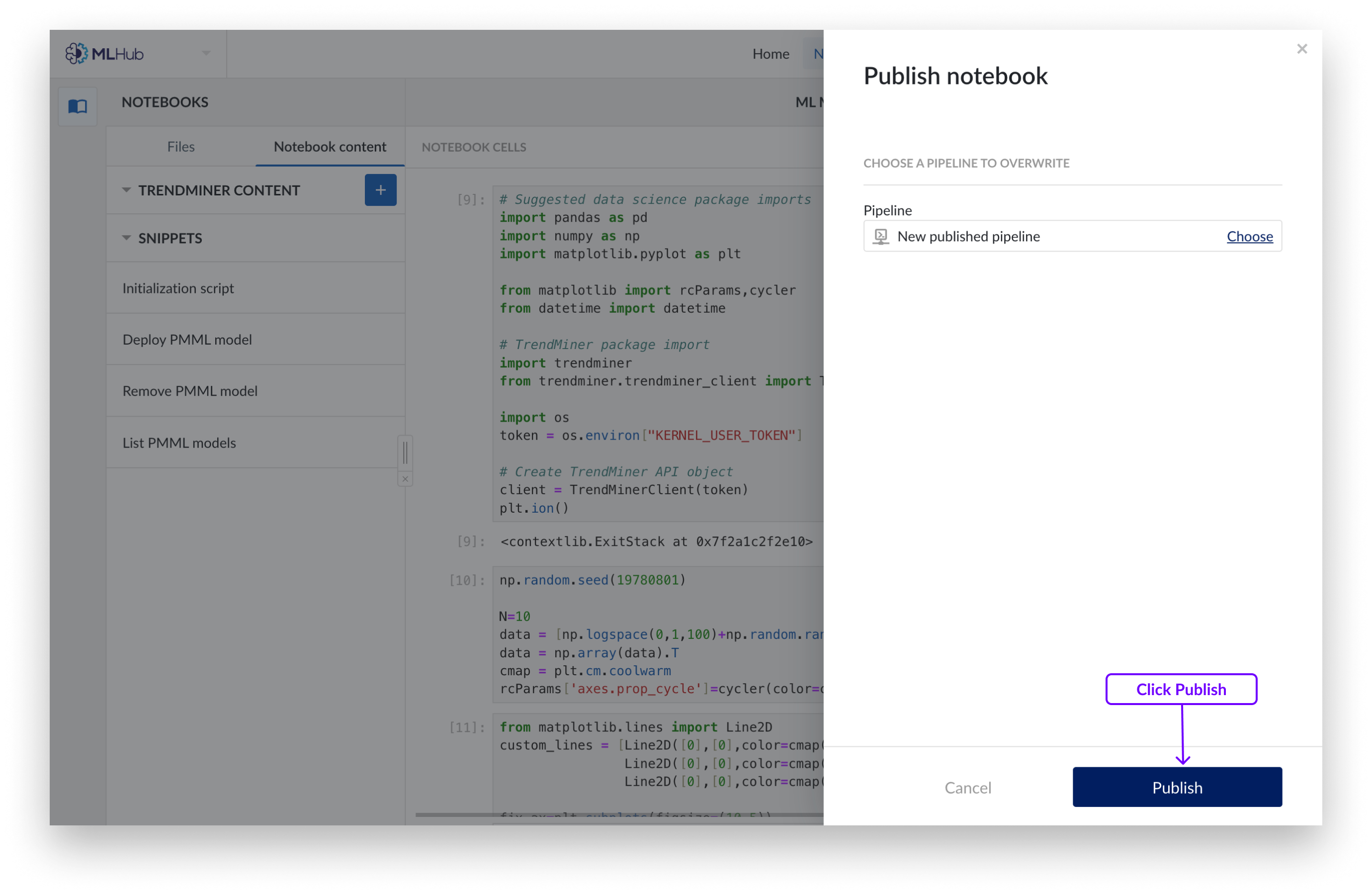
Vous disposez maintenant d'un objet pipeline contenant le code des cellules que vous avez sélectionnées.
DashHub permet d'afficher toute sortie d'un paragraphe du Notebook dans une vignette du Dashboard.
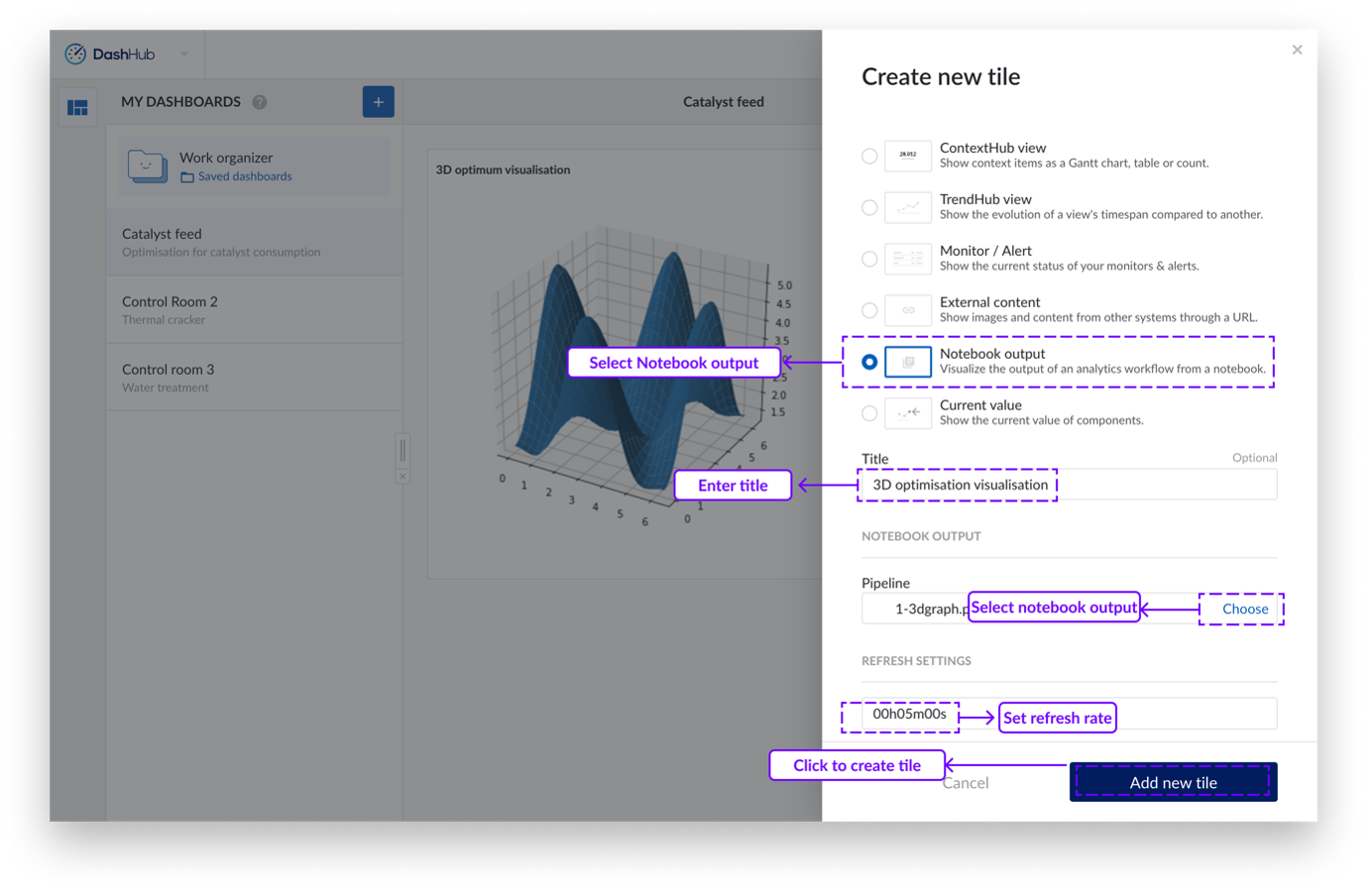
Création d'une Vignette de Notebook
Allez dans DashHub et créez un nouveau tableau de bord ou ouvrez un tableau de bord précédemment créé.
Cliquez sur le bouton "Actions". Un menu déroulant apparaît.
Cliquez sur "Ajouter une nouvelle vignette". Un panneau latéral apparaîtra sur la droite.
Cliquez sur l'option "Sortie Notebook".
Donnez un titre à la vignette du tableau de bord.
Sélectionnez l'objet pipeline dans l'Organiseur de travail.
Ajustez le paramètre de rafraîchissement si nécessaire.
Cliquez sur "Ajouter une nouvelle vignette".
Note
Lorsque vous partagez une vignette DashHub, les vues et les objets de pipeline sous-jacents doivent également être partagés.
Le partage d'un Notebook donne lieu à un lien symbolique vers le Notebook original. Cela signifie que le créateur reste le propriétaire des données de référence du notebook. Les modifications apportées aux cellules sont enregistrées selon le principe FIFO et ne seront mises à jour que lors du rafraîchissement de l'écran.
Les objets pipeline publiés ne sont plus liés aux notebooks d'origine. Une fois publiés, les changements sur le notebook n'auront pas d'impact automatique sur l'objet pipeline existant du notebook. Cela permet aux utilisateurs d'affiner les sorties de cellules de notebook, sans avoir d'impact sur les autres utilisateurs/visiteurs.
Les notebooks et les visualisations des sorties des notebooks sont exécutés en fonction de vos autorisations et privilèges. Cela signifie que certaines sources de données peuvent être bloquées, et que vous ne pouvez traiter les données qu'en fonction de votre rôle.