Expérimental : TrendMiner Anomaly Detection Model
TrendMiner propose un modèle personnalisé pour la détection d'anomalies multi-variables via sa fonctionnalité de notebook et de machine learning model tags.
Le TrendMiner Anomaly Detection Model est entraîné sur une vue TrendHub contenant les conditions de fonctionnement normales de votre processus. Après avoir appris les conditions de processus souhaitées, le modèle sera alors capable de détecter les anomalies sur les nouvelles données entrantes.
Le modèle lui-même peut être formé à l'intérieur de la fonctionnalité de notebook intégrée après le chargement d'une vue TrendHub en tant que DataFrame. Plus d'informations sur la fonctionnalité Notebook sont disponibles ici.
Note
Le paquetage anomaly_detection est expérimental. Les fonctions de ce paquetage peuvent être modifiées ou supprimées dans les prochaines versions.
Le modèle de détection des anomalies est fourni par le paquetage expérimental et peut être chargé comme suit :
from trendminer_experimental.anomaly_detection.model import TMAnomalyModel # Instantiate the model model = TMAnomalyModel()
Le modèle d'anomalie est basé sur des cartes autoadaptatives (Self Organising Maps). Conceptuellement, le modèle ajuste une grille flexible d'unités, sur l'ensemble des données d'apprentissage. Dans la phase d'entraînement, l'algorithme tente de minimiser la distance entre les points de données d'entraînement à n dimensions et les unités les plus proches, tout en essayant de garder la grille aussi lisse que possible pour éviter l'ajustement excessif des données d'entraînement.
Pour former le modèle, nous commençons par charger une vue TrendHub qui représente les conditions de fonctionnement normales. Après le chargement de la vue, le modèle peut être entraîné. L'utilisateur peut spécifier le nombre d'itérations utilisées pour l'étape de formation.
# Loading TrendHub view: Normal Operation Conditions from trendminer.views import Views
views = Views(client)
df_train = views.load_view('c3fa5b78-3df9-4fe4-b6d0-e0da4f19c24e')# Training the model q_error, topo_error = model.fit(df_train, 500)# Training for 500 iterations
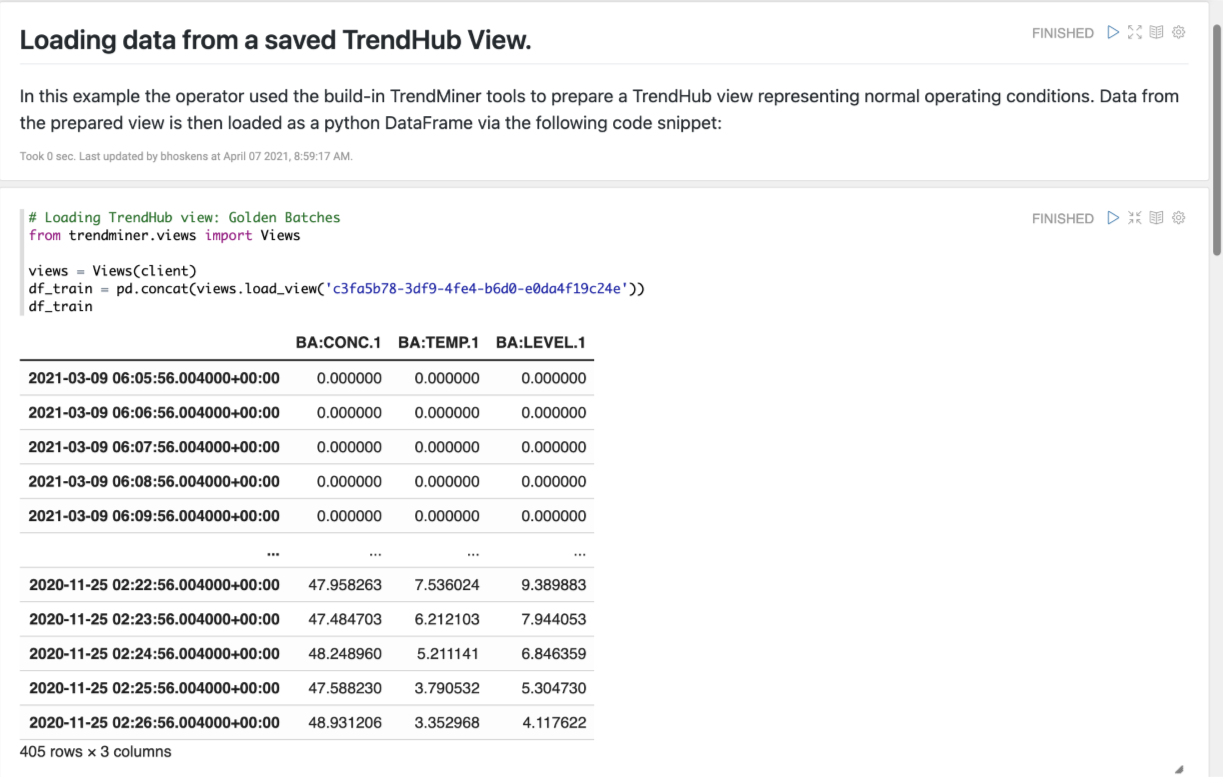
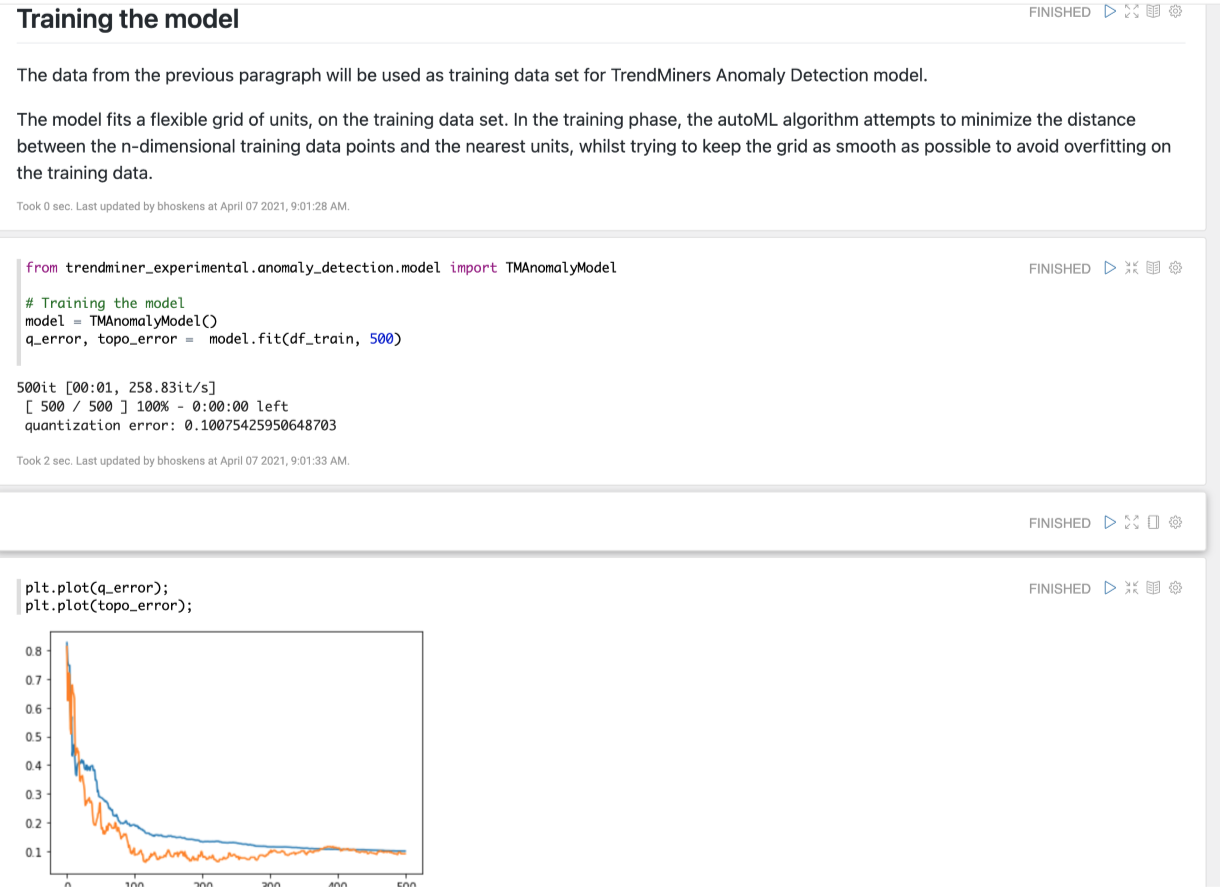
La méthode fit renvoie une liste d'erreurs de quantification et d'erreurs topologiques. L'erreur de quantification mesure la distance entre les points de données d'apprentissage et les unités de la grille, tandis que l'erreur topologique mesure la régularité de la grille et indique un surajustement.
Un score plus faible indique un meilleur ajustement.
Les erreurs doivent présenter une tendance à la baisse pour chaque itération.
# Plot errors (requires matplotlib import) plt.plot(q_error); plt.plot(topo_error);
Le TMAnomalyModel possède deux variables de sortie : Anomaly_Class et Anomaly_Score. La première (Class) identifie un point comme étant anormal ou non, en fonction de la distance du point à l'unité la plus proche dans le modèle et du pourcentage de seuil que vous avez fourni lors de la conversion du modèle en sa représentation PMML. Le second, Score, est la distance entre un point et l'unité la plus proche dans le modèle.
# Loading TrendHub view: Test data or New incoming data from trendminer.views import Views
views = Views(client)
df_test = views.load_view('c3fa5b78-3df9-4fe4-b6d0-e0da4f19c24e')# Run model (anomaly_class) anomaly_class = model.predict(df_test, 0.99)
# Run model (anomaly_score) anomaly_score = model.score_samples(df_test)
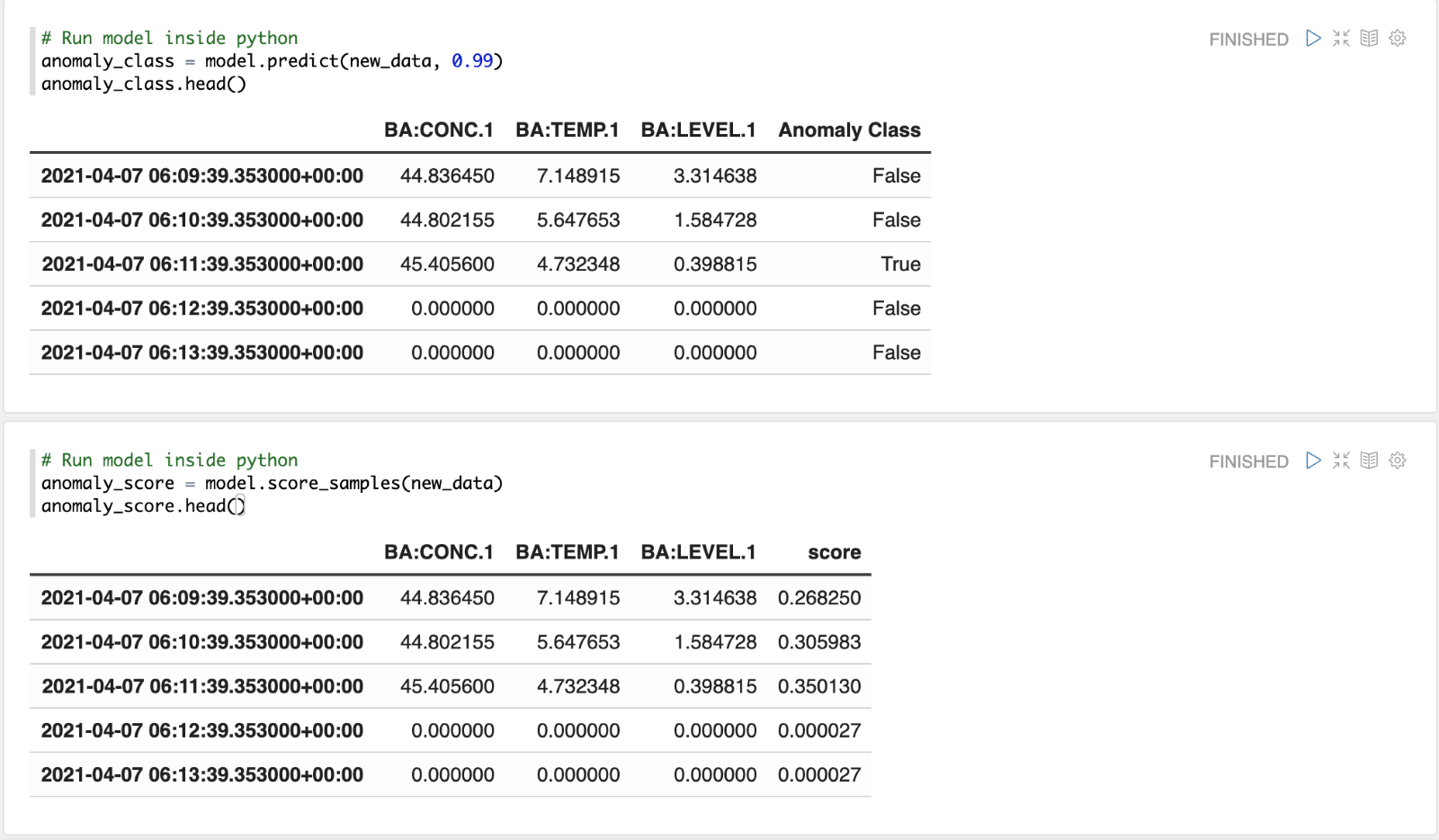
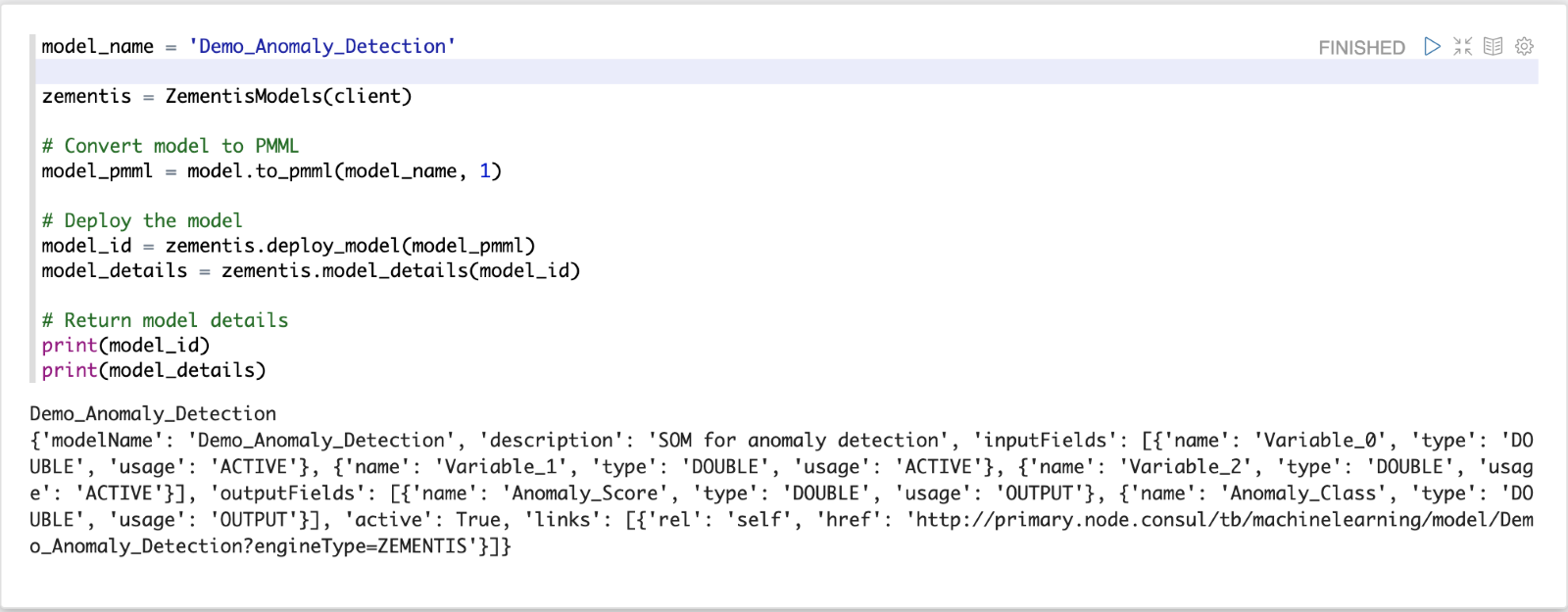
Une fois le modèle construit sur des données d'un comportement normal, nous pouvons déployer le modèle sur le moteur de scoring de TrendMiner. Pour cela, nous devons convertir le modèle dans son format PMML. Le TMAnomalyModel possède une méthode utilitaire pour convertir le modèle en PMML (to_pmml). Cette fonction prend deux arguments. Le premier argument est le nom du modèle. Le second argument est le pourcentage du seuil.
Après le déploiement, le modèle peut être sélectionné dans la fonctionnalité de tag Machine Learning Model.
model_name = 'Demo_Anomaly_Detection'
zementis = ZementisModels(client)
# Convert model to PMML model_pmml = model.to_pmml(model_name, 0.99)
# Deploy the model model_id = zementis.deploy_model(model_pmml) model_details = zementis.model_details(model_id)
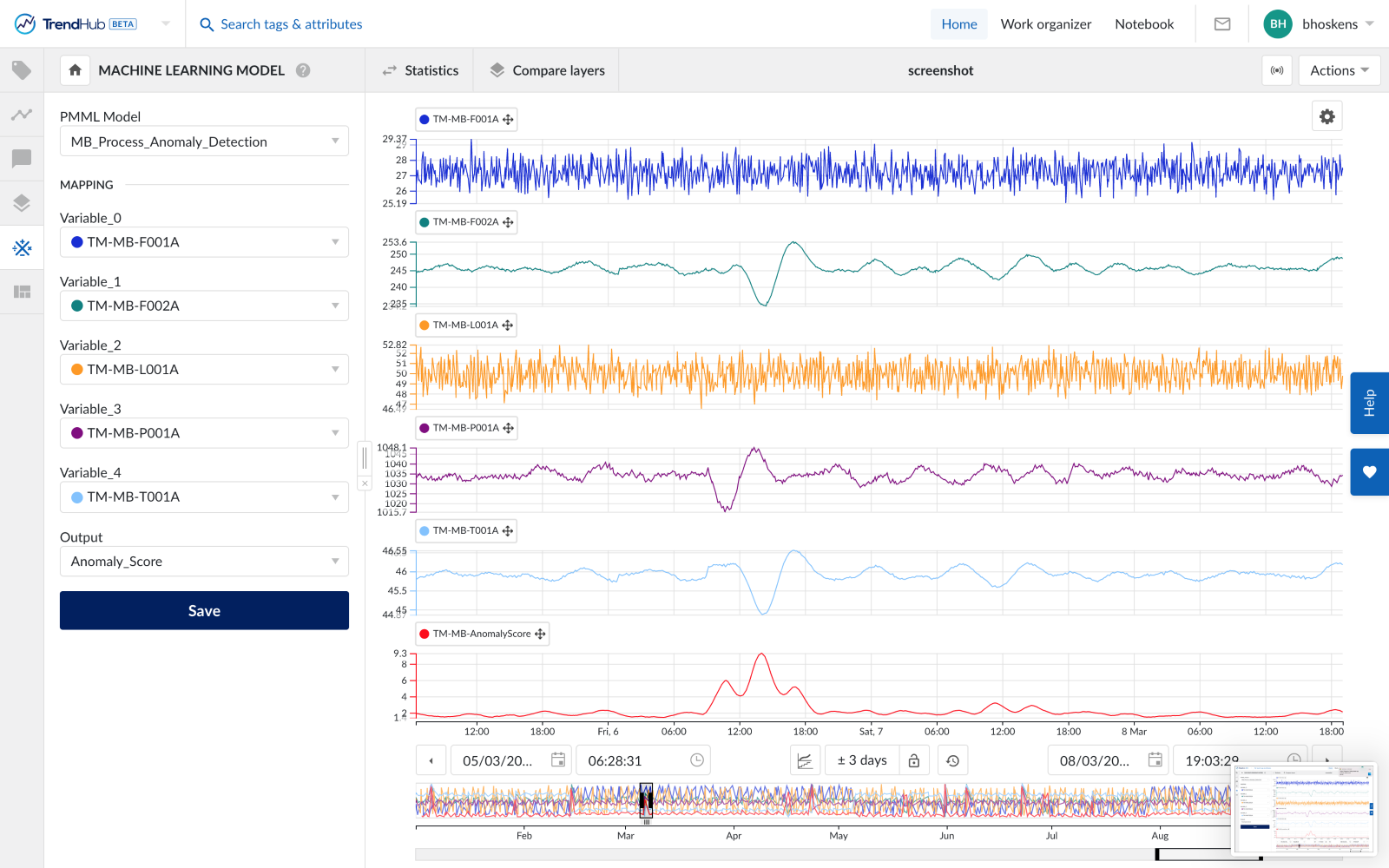
Vous trouverez de plus amples informations dans la documentation expérimentale de python.
Les limitations des Machine Learning Model tags s'appliquent à ce modèle.