Données
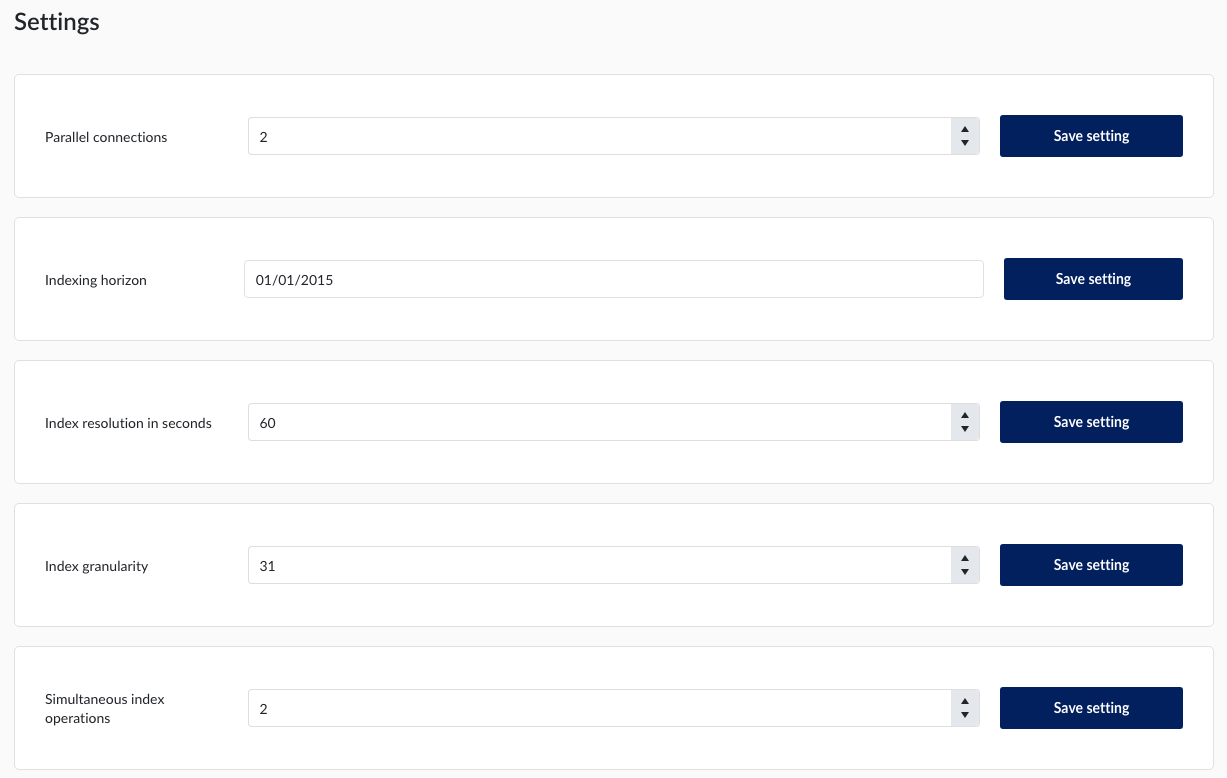
TrendMiner utilise certains paramètres de connexion pour optimiser les performances de la connexion historique. Par défaut, 2 connexions parallèles sont utilisées. Dans la plupart des cas, la valeur du paramètre "Historian Parallelism" doit être égale au nombre de cœurs de votre serveur Historian.
Il s'agit d'un paramètre global, mais les connexions parallèles peuvent également être définies par source de données (dans le menu datqa > ; datasource) en tant qu'option prioritaire. La modification de la valeur globale par défaut ne mettra pas à jour les valeurs prioritaires existantes. Elles conserveront la valeur actuelle définie comme prioritaire.
Note
Consultez l'assistance TrendMiner à l'adresse support@trendminer.com si vous rencontrez des problèmes de performance ou si vous pensez qu'il serait approprié de modifier ce paramètre.
L'horizon d'indexation indique la date la plus ancienne à partir de laquelle les tags sont indexés. Les données des tags antérieures à cette date ne seront pas disponibles pour l'analyse de TrendMiner. L'horizon d'indexation par défaut est le 1er janvier 2015 (référence 1). Lorsque vous augmentez l'horizon d'indexation (par exemple de 2015 à 2010), les tags déjà indexés reprendront automatiquement l'indexation jusqu'au nouvel horizon chaque fois que ces tags seront utilisés dans les graphiques ou par les moniteurs.
La résolution de l'index définit le niveau de détail de l'index. Pour une résolution de 1 minute (par défaut), l'index contient jusqu'à 4 points par minute.
Les résolutions d'index valides sont les suivantes.
Minimum : 1 (une seconde)
Maximum : 86400 (un jour)
86400 doit être divisible par la résolution de l'indice
Attention
Si nécessaire, une résolution d'index de 1 seconde peut être configurée, bien que cela ne soit pas officiellement pris en charge et puisse entraîner des problèmes de performances.
Note
La modification de la résolution de l'index supprimera tous les index de balises existants.
La granularité de l'index définit les périodes de temps qui sont extraites de la source de données pour construire l'index, au cours du processus d'indexation ascendante. Plus les périodes de temps sont petites, plus le nombre d'appels à la source de données est élevé, ce qui entraîne des frais généraux plus importants et une indexation plus lente. Plus la granularité est grande, plus le risque d'interruption de la connexion est élevé et plus la consommation de mémoire est importante.
La granularité par défaut est de 1 mois ("1M").
Les granularités d'index valides sont, par exemple, "1D" (1 jour), "5D" (5 jours) ou "2M" (2 mois). La modification de la granularité n'aura pas d'incidence sur les tags déjà indexés.
Cette valeur définit le nombre d'opérations d'indexation simultanées. La valeur par défaut est 2, ce qui signifie que seules 2 tâches d'indexation peuvent être exécutées à un moment donné. Les périodes de différents Tag seront entrelacées, en donnant une plus grande priorité aux périodes les plus récentes, garantissant ainsi que tous les Tag seront indexés à un rythme similaire.
Veuillez contacter le service d'assistance de TrendMiner avant de modifier ce paramètre - support@trendminer.com
Ajoutez un nouveau connecteur en cliquant sur l'étiquette (+ Ajouter un connecteur) à côté du titre et remplissez les champs pour les détails du connecteur.
Nom : vous êtes libre de choisir un nom. La seule restriction est que chaque nom de connecteur doit être unique.
Host : nom d'hôte du connecteur.
Nom d'utilisateur et mot de passe : ne doivent être remplis que s'ils sont configurés lors de l'installation du connecteur.
Dès qu'un nouveau connecteur est ajouté avec succès, il commence à synchroniser toutes les sources de données qui sont configurées pour le connecteur.
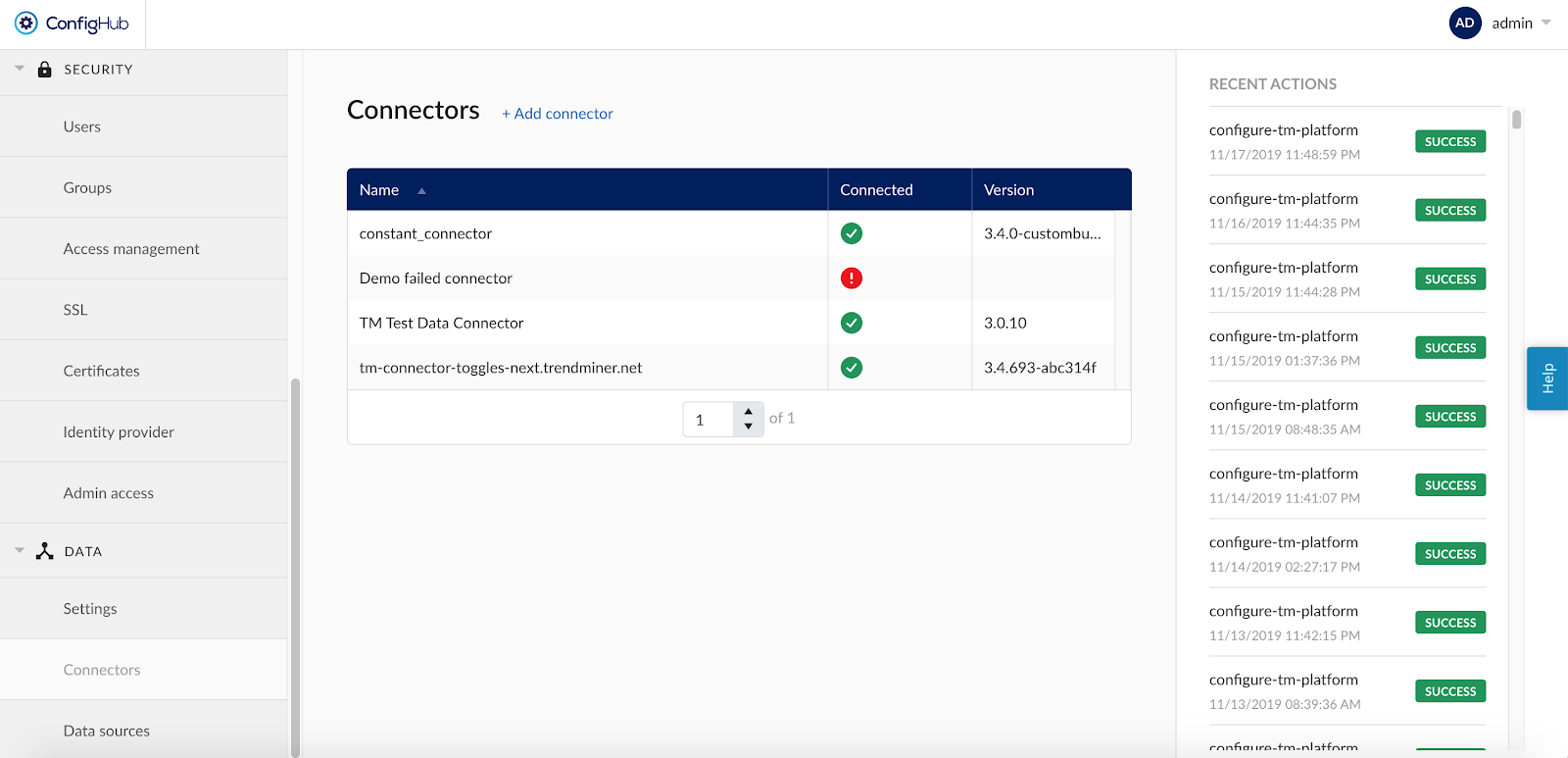
Si un connecteur ne peut pas être synchronisé, un point d'exclamation rouge apparaît dans la liste des connecteurs. Pour en savoir plus sur la cause de l'échec, ouvrez les détails du connecteur en cliquant sur son nom. Le retour d'information sur l'erreur s'affiche sous "Dernière synchronisation".
Pour les connecteurs qui sont connectés avec succès, le champ "Dernière synchronisation" dans les détails du connecteur indiquera la date et l'heure de la dernière synchronisation. La date et l'heure de la dernière synchronisation seront mises à jour lorsqu'une synchronisation manuelle est déclenchée ou lorsque TrendMiner synchronise le cache de balises pour ce connecteur, généralement lors d'un rafraîchissement nocturne du cache de balises.
Important
Une coche verte dans la liste des connecteurs indique que TrendMiner est connecté avec succès au connecteur, mais elle n'indique pas s'il y a des problèmes de synchronisation entre le connecteur et la source de données. L'état de santé des sources de données connectées doit être visualisé dans le menu "Sources de données". Notez également que l'état n'est pas automatiquement mis à jour lorsque la page est chargée. Actualisez la page ou choisissez l'option "Tester la connexion" pour mettre à jour l'état de connexion d'un connecteur.
Pour modifier les détails d'un connecteur, cliquez sur son nom pour ouvrir les détails et choisissez ensuite "Options" ; "Modifier" Dans l'aperçu des connecteurs, la version de chaque connecteur est répertoriée. Cette information est importante au cas où une version plus récente du connecteur prendrait en charge de nouvelles fonctionnalités ou améliorations pour une source de données spécifique.
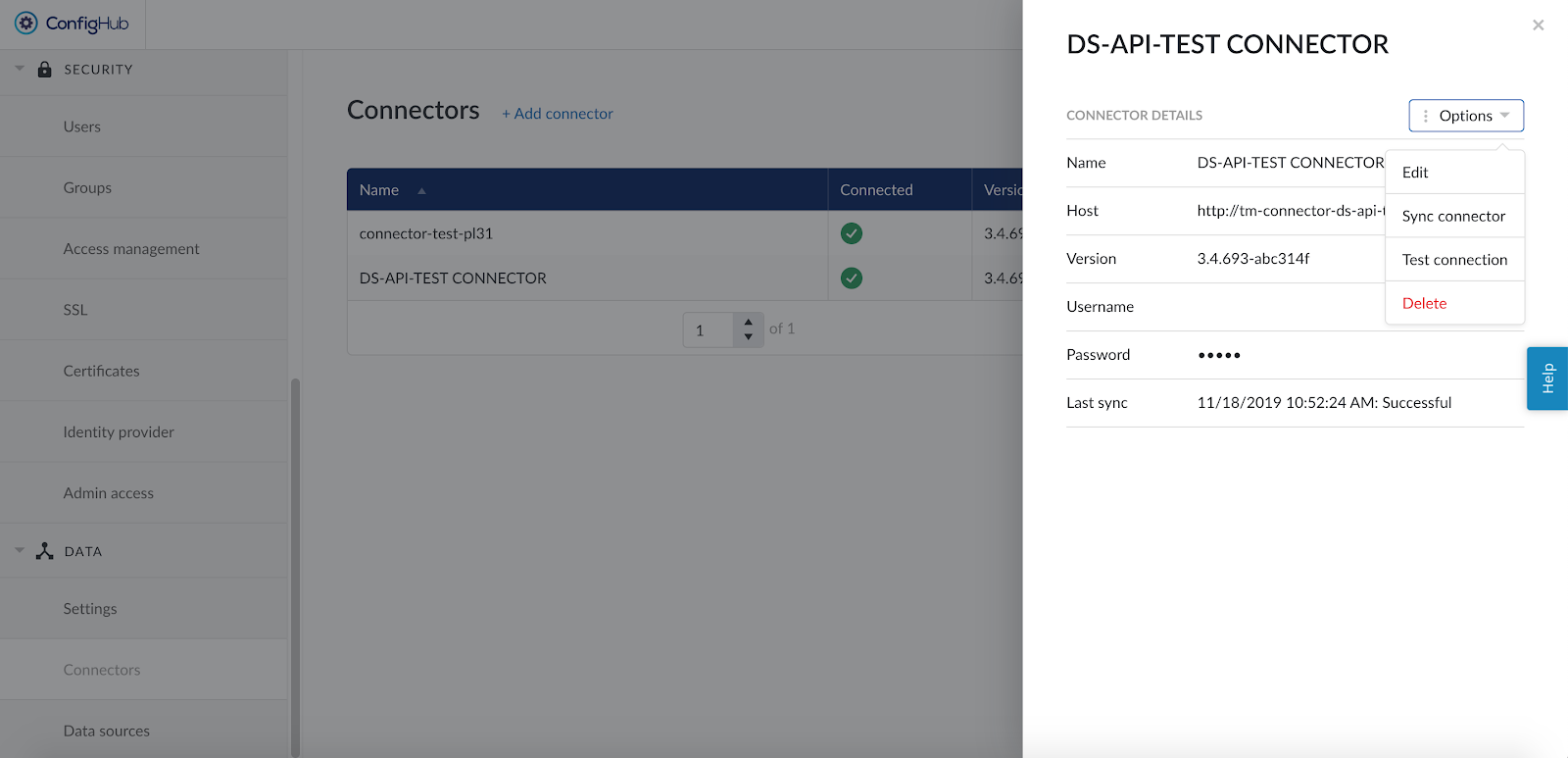
La modification du nom du connecteur n'affectera pas les balises des sources de données connectées, mais la modification de l'hôte, du nom d'utilisateur ou du mot de passe à une valeur incorrecte rendra les balises des sources de données connectées inaccessibles.
D'autres options sont disponibles.
Synchroniser le connecteur : Cette option déclenche une (re)synchronisation manuelle de toutes les sources de données configurées sur ce connecteur. Choisissez cette option pour mettre à jour tous les tags de toutes les sources de données connectées en une seule fois.
Tester la connexion : Cette option permet de tester la connexion du connecteur sans déclencher de synchronisation et de mettre à jour l'état de santé du connecteur.
Supprimer : Cette option supprime le connecteur de la configuration et supprime toutes les sources de données qui utilisent ce connecteur, jusqu'à ce que les sources de données soient reconnectées par un connecteur correctement configuré.
Lorsque vous cliquez sur l'option Sources de données, le menu des sources de données apparaît :
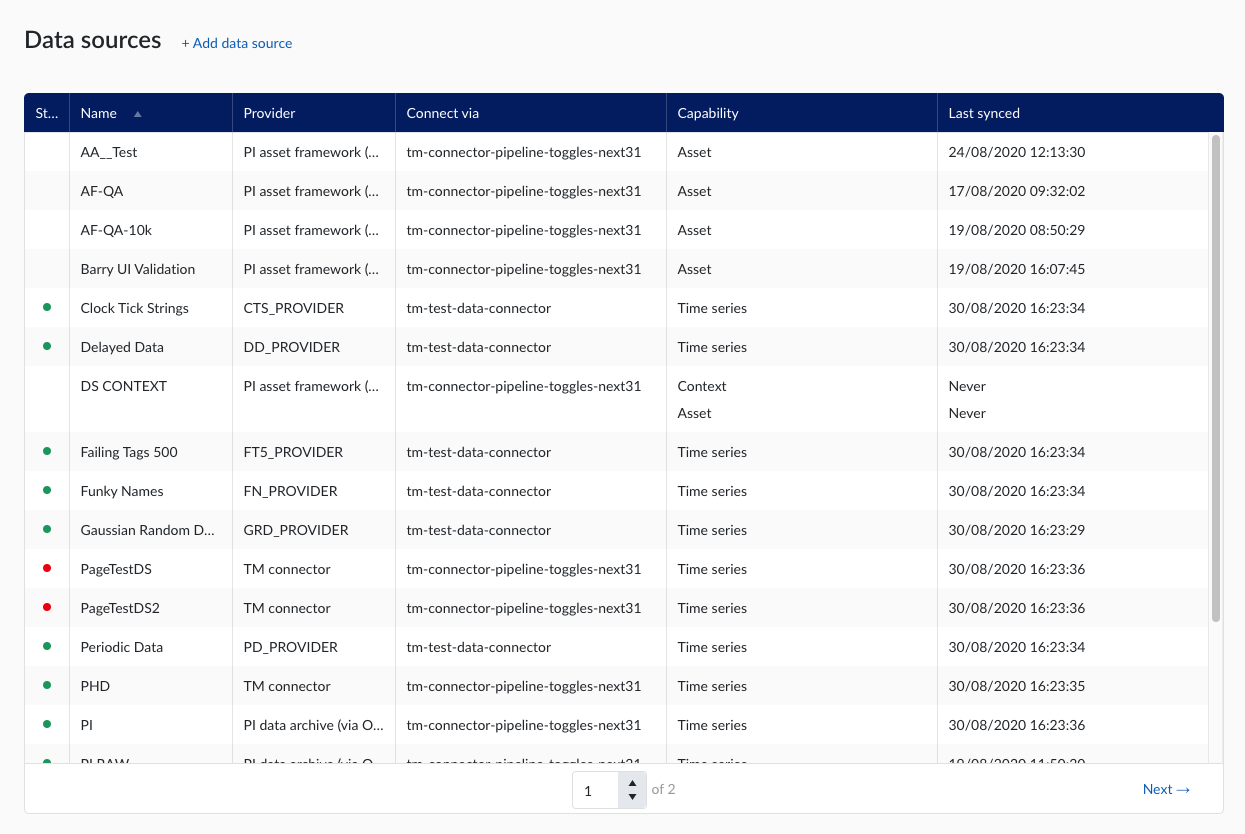
Ajoutez une nouvelle source de données en cliquant sur l'étiquette (+ Ajouter une source de données) à côté du titre. Un panneau latéral "Ajouter une source de données" apparaît à droite de l'écran :
Détails de la source de données
Remplissez les champs du panneau latéral "Ajouter une source de données" :
Nom : vous êtes libre de choisir les noms des sources de données, mais ils sont obligatoires, insensibles à la casse et uniques. Le nom d'une source de données identifie la source de données.
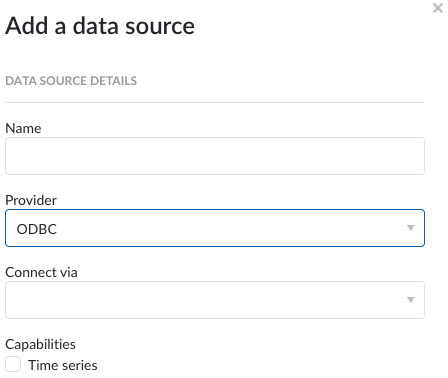
Fournisseur : TrendMiner fournit une connectivité prête à l'emploi aux sources de données via des implémentations de fournisseurs spécifiques (par exemple OSIsoft PI, Honeywell PHD, ...) et via des alternatives plus génériques (par exemple ODBC, OleDB, ...) Le fournisseur 'TM connector' permet la connexion de sources de données via une configuration de connecteur à connecteur. Pour connecter une source de données via plusieurs connecteurs, une configuration supplémentaire est nécessaire via l'API Connecteur TrendMiner.
Connecter via : ce champ obligatoire permet de sélectionner le connecteur utilisé pour se connecter à la source de données. Toutes les sources de données doivent être connectées via un connecteur. Pour ajouter une source de données, il faut d'abord ajouter au moins un connecteur.
Important
Les noms de tags en double ne sont pas pris en charge. Si deux tags portant exactement le même nom sont synchronisés avec TrendMiner, les analyses, les calculs et l'indexation sur/pour ces tags risquent d'échouer. Utilisez les préfixes des sources de données pour éviter les problèmes de noms de balises en double.
Note
Selon le fournisseur que vous sélectionnez, les détails de connexion requis pour l'achèvement peuvent différer. Les données gérées peuvent être de deux types (ou les deux) :
Séries chronologiques
Installation
 |  |
Données de séries temporelles
Lorsque vous cochez la case Série temporelle, d'autres champs s'affichent pour être complétés.
Détails de la connexion :
Host : le nom d'hôte de la source de données, par exemple myhistorian.mycompany.com
Nom d'utilisateur et mot de passe : nom d'utilisateur et mot de passe du compte configuré dans la source de données.
Mot de passe
Préfixe : vous êtes libre de choisir des préfixes. Il s'agit de chaînes de caractères uniques insensibles à la casse et d'une longueur maximale de 5 caractères. Lors de la synchronisation d'une source de données, tous les noms de tags de cette source de données seront précédés du préfixe afin de garantir l'unicité du nom du tag dans TrendMiner. Les préfixes sont facultatifs, mais nous vous recommandons vivement de fournir un préfixe lors de la connexion d'une source de données afin d'éviter les noms de balises en double.
Configuration des séries chronologiques
Filtre de tag : ce champ facultatif permet d'ajouter une expression régulière. Seuls les tags correspondant à cette expression régulière seront synchronisés avec TrendMiner.
Exemples :
Filtre Tag | Résultat |
|---|---|
LINE.[1]+ | Les tags dont le nom contient 'LINE.1' seront disponibles, mais les tags dont le nom contient 'LINE.3' seront exclus. |
^(?:(?!BA:TEMP).).*$ | N'exclut que les tags commençant par BA:TEMP (donc garde test_BA:TEMP.1) |
^\[pref\]PI.*$ | Ne synchronise que les tags provenant d'une source de données dont le préfixe est "pref" et qui commencent par "PI". |
Cliquez sur la source de données
Important
Cette configuration dépend du fournisseur.
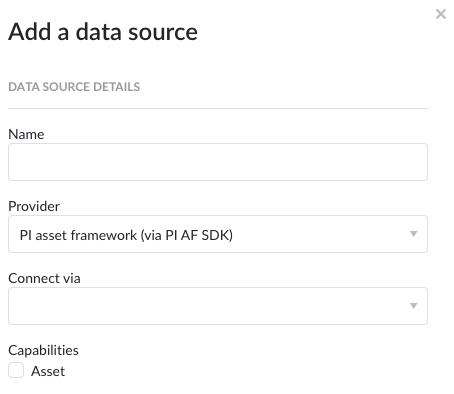
Données sur les installations
La procédure concernant les sources de données sur les installations est quelque peu similaire à celle des séries chronologiques, mais les champs à remplir sont beaucoup moins nombreux.
Important
Il n'est pas permis d'ajouter la même connexion plusieurs fois avec les installations activées sur les deux instances ! Les permissions de l'Arbre des installations doivent être gérées dans la section des permissions des installations (ContextHub).
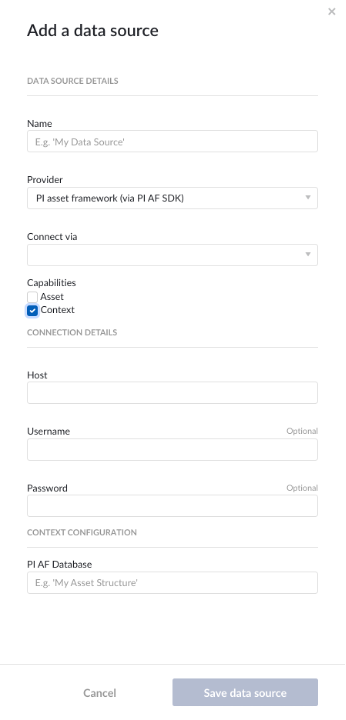
Données contextuelles
Les sources de données contextuelles sont gérées de la même manière que les sources de données d'Installation. Lorsqu'une source de données est capable de gérer le contexte, la case "capacité de gestion du contexte" peut être cochée, après quoi la base de données correcte pour les données contextuelles doit être spécifiée.
Note
Les données de contexte synchronisées à partir d'une source de données dans OSISoft PI seront liées aux données d'installation dans TrendMiner en fonction des "éléments référencés" des cadres d'événement PI. Le système tente toujours de relier l'Item de contexte à l'Installation correspondant à l'élément référencé principal dans PI (s'il existe). Dans le cas contraire, le système utilise par défaut le premier élément référencé pour lequel un actif correspondant est connu dans TrendMiner.
Important
Il n'est pas permis d'ajouter la même connexion plusieurs fois avec les capacités de contexte activées sur les deux instances ! Cela entraînera la création d'items de contexte en double.
Menu source de données
Dès qu'une nouvelle source de données est ajoutée avec succès, elle commencera à synchroniser tous les Tag de la source de données, et peut être trouvée dans le menu Source de données.
Pour synchroniser manuellement la source de données, il suffit de :
Cliquez sur la source de données de votre choix dans le menu des sources de données. Un panneau latéral apparaît à droite.
Cliquez sur le bouton de synchronisation.
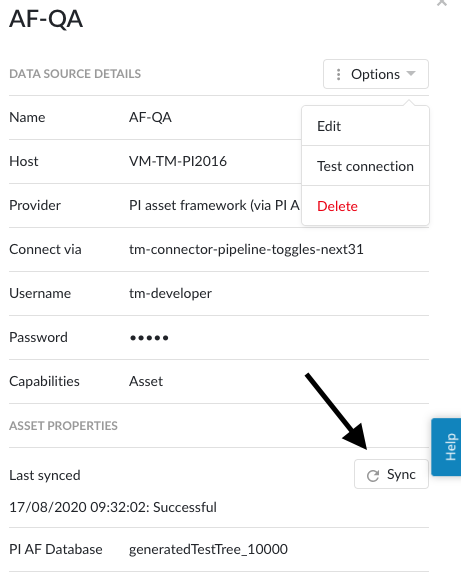
Si une source de données ne peut pas être synchronisée, elle apparaît dans la liste des sources de données. Pour en savoir plus sur la cause de l'échec, ouvrez les détails de la source de données en cliquant sur son nom. Le retour d'information sur l'erreur s'affiche sous "Dernière synchronisation".
Pour les sources de données qui sont connectées avec succès, le champ "Dernière synchronisation" dans les détails de la source de données indiquera la date et l'heure de la dernière synchronisation. La date et l'heure de la dernière synchronisation seront mises à jour lorsqu'une synchronisation manuelle est déclenchée ou lorsque TrendMiner synchronise le cache de balises pour cette source de données, généralement lors d'un rafraîchissement nocturne du cache de balises.
Note
L'état n'est pas automatiquement mis à jour lorsque la page est chargée. Actualisez la page ou choisissez l'option "Tester la connexion" (pour les séries chronologiques) afin de mettre à jour l'état de connexion d'une source de données.
Pour modifier les détails d'une source de données, cliquez sur son nom pour ouvrir les détails, puis choisissez "Options" -> "Modifier".
Il est interdit de modifier le préfixe d'une source de données existante, car cela perturberait les vues, les formules, etc. existantes. Il est également interdit de modifier le champ "Connecter via". Tous les autres champs peuvent être mis à jour, après quoi la source de données est à nouveau synchronisée.
D'autres options sont disponibles :
Tester la connexion (uniquement pour les sources de données de séries temporelles) : cette option permet de tester la connexion à la source de données sans déclencher de synchronisation et de mettre à jour l'état de santé de la source de données.
Supprimer : cette option supprime la source de données et tous les Tag de cette source de données jusqu'à ce qu'elle soit à nouveau connectée via un connecteur correctement configuré.
Lorsqu'une source de données est supprimée, tous les Tag de cette source de données deviennent immédiatement indisponibles, ainsi que les vues et les calculs qui dépendent de ces Tag. Il est possible de restaurer ces balises et les vues et formules dépendantes en ajoutant à nouveau la source de données, en utilisant exactement le même nom et le même préfixe via le même connecteur ou un connecteur alternatif.
Événement Frame Sync
La section "Event frame sync" de la page de diagnostic dans la section des données de ConfigHub permet aux administrateurs de surveiller efficacement l'état de synchronisation des sources de données contextuelles. Les synchronisations sont divisées en plusieurs types, pour chacun desquels une section distincte existe sur la page de diagnostic :
La synchronisation en temps réel vise à maintenir les éléments de contexte dans TrendMiner aussi proches que possible de l'état des Event Frame dans la source de données. Elle traite les Event Frame entrants de manière séquentielle, selon le principe "premier entré, premier sorti".
La synchronisation par intervalles excessifs est automatiquement déclenchée à partir de la synchronisation en direct, en cas de réception d'un grand nombre d'images d'événements sur une courte période. Cette mise à jour en bloc sera isolée de la file d'attente de la synchronisation en direct et traitée en parallèle.
La synchronisation historique peut être déclenchée à la demande pour les sources de données contextuelles et synchronisera, à des intervalles spécifiques, toutes les trames d'événements de cette source de données pour un intervalle de temps spécifique dans le passé. Elle est traitée parallèlement à la synchronisation en direct et à la synchronisation par intervalles excessifs.
La synchronisation des cadres d'événements est pilotée par leur date de dernière modification. Cela permet de s'assurer que les modifications seront toujours prises en compte, même si l'Événement lui-même s'est produit en dehors de l'intervalle de synchronisation.
Synchronisation en direct
Pour chaque source de données contextuelle dont la synchronisation en direct est activée, TrendMiner vérifiera périodiquement la source de données pour les nouveaux cadres d'événements ou les cadres d'événements mis à jour. Tous les Event Frame créés ou mis à jour entre la dernière vérification et le moment présent seront pris en compte pour la synchronisation. L'application garde une trace de la progression de la synchronisation, de sorte que même si la synchronisation est interrompue (par exemple en raison de problèmes de connexion), elle reprendra là où elle s'était arrêtée une fois le problème résolu.
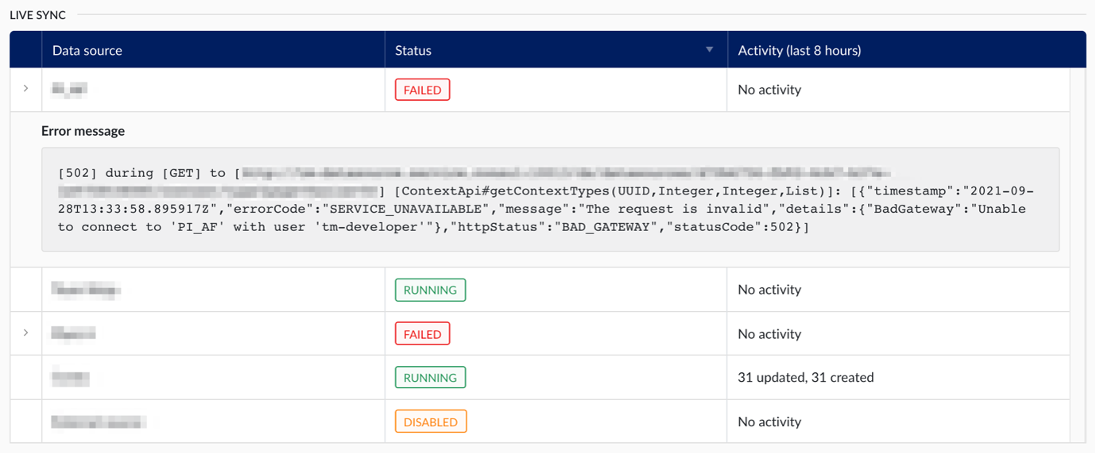
Si la synchronisation en temps réel rencontre une exception (par exemple, la source de données ne peut être atteinte et aucune trame d'événement ne peut être récupérée), elle recevra le statut "Échec" et un message d'exception peut être rendu visible en cliquant sur la flèche dans la colonne la plus à gauche.
Les événements erronés lors du traitement de trames d'événements uniques n'entraîneront pas un état d'échec. Ces événements seront simplement ignorés et suivis dans le cadre de la section des éléments de contexte ayant échoué.
Synchronisation excessive des intervalles
La synchronisation par intervalle excessif se déclenche automatiquement lorsque la synchronisation en direct détecte un grand nombre d'images d'événements dans le même intervalle de synchronisation. Le seuil de synchronisation par intervalle excessif est fixé à 800 images d'événements par intervalle. Une fois ce seuil atteint, l'ensemble de l'intervalle est isolé de la synchronisation en direct et traité en parallèle. Cela permet d'éviter de retarder l'intervalle suivant de la synchronisation en direct, en raison du temps de traitement requis pour le grand nombre de trames d'événements dans l'intervalle actuel.

Le tableau présente un historique complet de toutes les synchronisations d'intervalles excessifs qui se sont produites. Pour chacune d'entre elles, les informations suivantes sont disponibles :
Source de données : La source de données pour laquelle le besoin d'un intervalle de synchronisation excessif a été détecté.
Intervalle : L'intervalle de temps pendant lequel le besoin d'une synchronisation à intervalle excessif s'est fait sentir.
Progression : La colonne de progression combine l'état de la synchronisation avec une barre de progression. Les statuts suivants sont possibles :
En attente : Si trop de synchronisations à intervalles excessifs sont déjà en cours, les synchronisations supplémentaires seront mises en attente jusqu'à ce que des ressources soient disponibles pour les prendre en charge.
Échec : La synchronisation d'intervalle excessive a rencontré une exception dure, ce qui a entraîné le non-traitement de certaines ou de toutes les trames d'événement. La synchronisation par intervalles peut être réessayée en cliquant sur l'icône de réessai dans la colonne la plus à droite du tableau (visible uniquement pour les lignes ayant échoué). L'exception rencontrée peut être affichée en cliquant sur la flèche dans la colonne la plus à gauche.
Terminé : La synchronisation de l'intervalle excessif s'est achevée avec succès. Toutes les trames d'événements ont été traitées avec succès ou ont été ajoutées à la liste des éléments de contexte ayant échoué.
Synchronisation historique
Une synchronisation historique peut être demandée à la demande par les administrateurs, pour les sources de données contextuelles, en sélectionnant la source de données souhaitée dans le tableau et en lançant la synchronisation historique pour un intervalle spécifié dans le passé. Le résultat est une resynchronisation complète de tous les Event Frame modifiés pendant cette période.
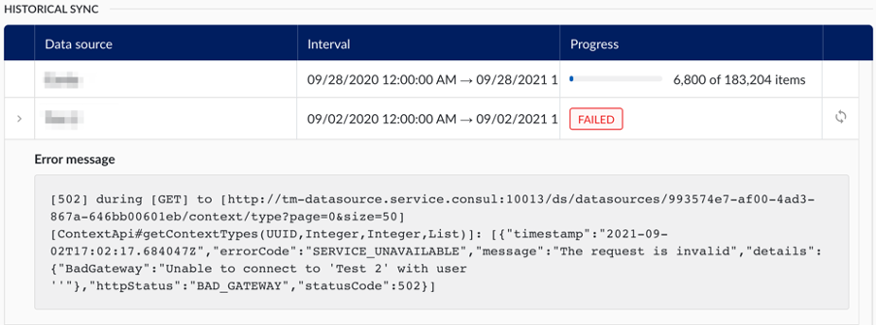
Le tableau conserve une vue d'ensemble de toutes les synchronisations historiques qui se sont produites. Les informations disponibles dans le tableau sont les mêmes que pour la synchronisation par intervalle excessif, y compris la possibilité de réessayer les synchronisations qui ont échoué.
Processus de nettoyage
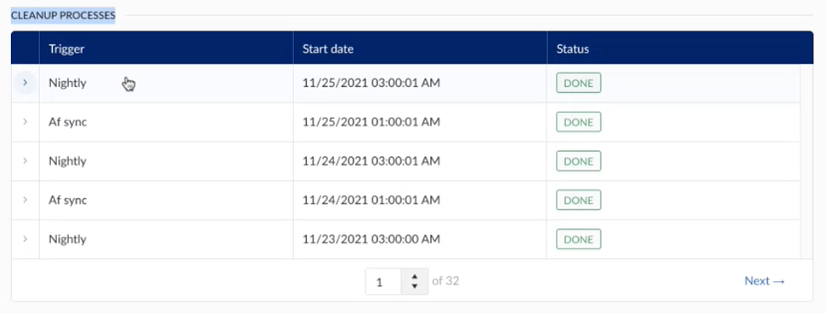
Il existe deux déclencheurs pour les processus de nettoyage : le processus de nettoyage nocturne déclenché chaque nuit à une heure prédéfinie et une resynchronisation automatique des éléments sans composant.
Note
Les resynchronisations automatiques sont surveillées et gérées exclusivement par les administrateurs de ConfigHub, dans la "Source de données" sous l'option "Paramètres" dans ConfigHub. Reportez-vous à la section "Source de données" ci-dessus.
Synchronisation nocturne
La resynchronisation nocturne automatique des items ouverts apparaîtra dans l'écran de diagnostic comme une tâche active, une fois qu'elle aura démarré. Cette synchronisation est programmée dans les Paramètres, dans la section Données de ConfigHub.
Chaque nuit, le système vérifie si des éléments de contexte sont ouverts depuis plus de 24 heures. Cela signifie que les éléments de contexte ont une date de début présente mais pas d'heure/date de fin indiquée. Cela signifie que les éléments de contexte sont toujours ouverts.
Des Evénements ouverts pendant plus de 24 heures peuvent indiquer que l'événement de départ était bon, mais que quelque chose a mal tourné pendant l'événement de clôture, empêchant la clôture de l'élément de contexte.
Les items contextuels devant être fermés seront correctement mis à jour dans le cadre du nettoyage nocturne. Si ce n'est pas le cas, les éléments de contexte resteront ouverts jusqu'à ce qu'un événement de fin apparaisse à partir de la source.
Note
Un nettoyage manuel peut être déclenché à partir de la source de données, dans les paramètres de ConfigHub. Consultez la section "Source de données" ci-dessus.
Sync AF (Framework des installations)
Un autre processus de nettoyage des éléments de contexte est déclenché par la réussite d'une synchronisation AF (qui peut être lancée à partir des sources de données compatibles avec les installations dans ContextHub) ou d'une importation AF (qui peut être initiée par les administrateurs de TrendMiner dans ContextHub).
Si des installations ont été ajoutées ou retirées de l'AF source, une synchronisation AF identifiera les différences et mettra à jour l'AF TrendMiner en conséquence. Par la suite, cela déclenchera une resynchronisation automatique des éléments de contexte n'ayant pas de composant associé, qui apparaîtra dans l'écran de diagnostic en tant que tâche planifiée.
Note
Pour ajouter une synchronisation AF, reportez-vous à la section "Données d'installation" ci-dessus.
Échec des Context Item
Si un cadre d'événement n'est pas traité correctement et que l'élément de contexte correspondant ne peut pas être créé ou mis à jour, il sera ajouté au tableau des éléments de contexte ayant échoué.
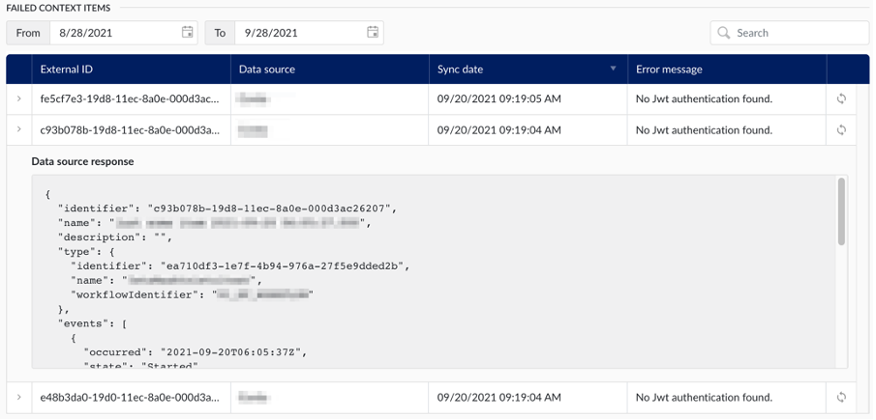
Le tableau fournit un aperçu historique complet de toutes ces défaillances et, pour chacune d'entre elles, les informations suivantes sont disponibles :
ID externe : l'ID du cadre d'événement correspondant, dans le système source.
External ID: the ID of the corresponding event frame in the source system.
Date de synchronisation : L'heure à laquelle la dernière synchronisation a eu lieu (et a échoué).
Message d'erreur : Le message d'erreur rencontré au moment de l'échec.
En outre, la table offre deux caractéristiques supplémentaires :
Afficher la réponse de la source de données : En cliquant sur la flèche dans la colonne la plus à gauche, l'administrateur peut visualiser la charge utile reçue de la source de données.
Retraiter la trame de l'événement : En cliquant sur l'icône de réessai dans la colonne la plus à droite, l'application tentera de retraiter la trame de l'événement, ce qui permettra peut-être de résoudre l'échec.
Synchronisation du Framework des installations
La section "synchronisation du Framework des installations" de la page de diagnostic dans la section des données de ConfigHub permet aux administrateurs de surveiller efficacement l'état de synchronisation des sources de données compatibles avec les installations.
L'histoire
La table d'historique conserve l'historique complet des synchronisations du Framework des installations.
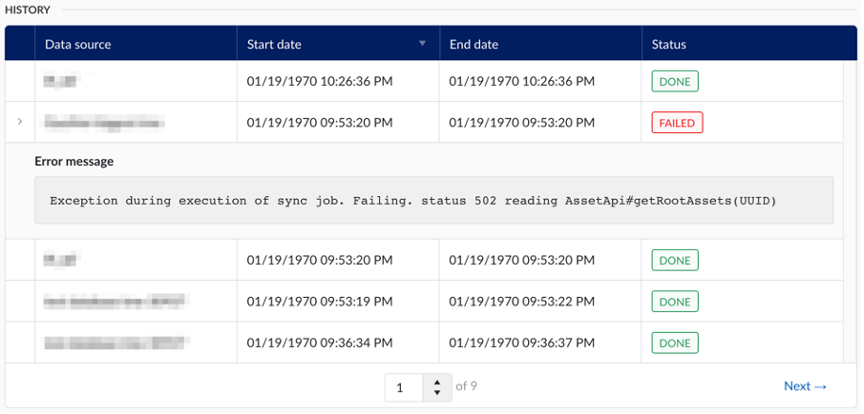
L'administrateur dispose des informations suivantes :
Source de données : La source de données à partir de laquelle la structure des installations a été synchronisée.
Date de début : La date et l'heure à laquelle la synchronisation a été lancée.
Date de fin : La date et l'heure à laquelle la synchronisation s'est terminée.
Statut : Le statut final de la synchronisation.
En cas d'échec de la synchronisation, un message d'erreur peut être affiché en cliquant sur la flèche dans la colonne la plus à gauche du tableau.
Références
Pour les installations propres de 2019.R2 ou plus récentes. Les mises à niveau à partir d'une installation TrendMiner antérieure conserveront l'horizon d'indexation par défaut précédent, à savoir le 1er janvier 2010, ou l'horizon d'indexation qu'ils ont défini manuellement.