Hub für maschinelles Lernen und Notebooks
Was ist Machine Learning Hub?
Die Vision von TrendMiner, Analysen zu demokratisieren, geht über die Befähigung von Fachexperten mit Self-Service-Tools hinaus und umfasst auch eine engere Zusammenarbeit zwischen verschiedenen Experten bei der Lösung von Problemen. Einige der komplexesten Probleme erfordern den Einsatz von Datenwissenschaftlern, die spezielle Techniken einbringen, mit denen Unternehmen die tiefsten Erkenntnisse aus den verfügbaren Daten gewinnen können. Denken Sie dabei an fortgeschrittene Statistik und Modelle des maschinellen Lernens.
Mit MLHub können Datenwissenschaftler auf TrendMiner-Daten zugreifen (sowohl Rohdaten als auch vorverarbeitete und kontextualisierte Daten in TrendMiner-Ansichten) und Hypothesen validieren oder Machine-Learning-Modelle in der neuen Notebook-Umgebung erstellen/trainieren/bereitstellen, die andere Benutzer über Machine-Learning-Modell-Tags anwenden und in DashHub visualisieren können.
So verwenden Sie den MLHub
Wichtig
Der Zugriff auf MLHub ist nur nach Einrichtung der Zugriffsverwaltung möglich, für die eine separate Lizenz erforderlich ist. Weitere Informationen zur Zugriffsverwaltung finden Sie hier. Wenn Sie weitere Informationen zur Lizenzierung benötigen, wenden Sie sich bitte an TrendMiner.
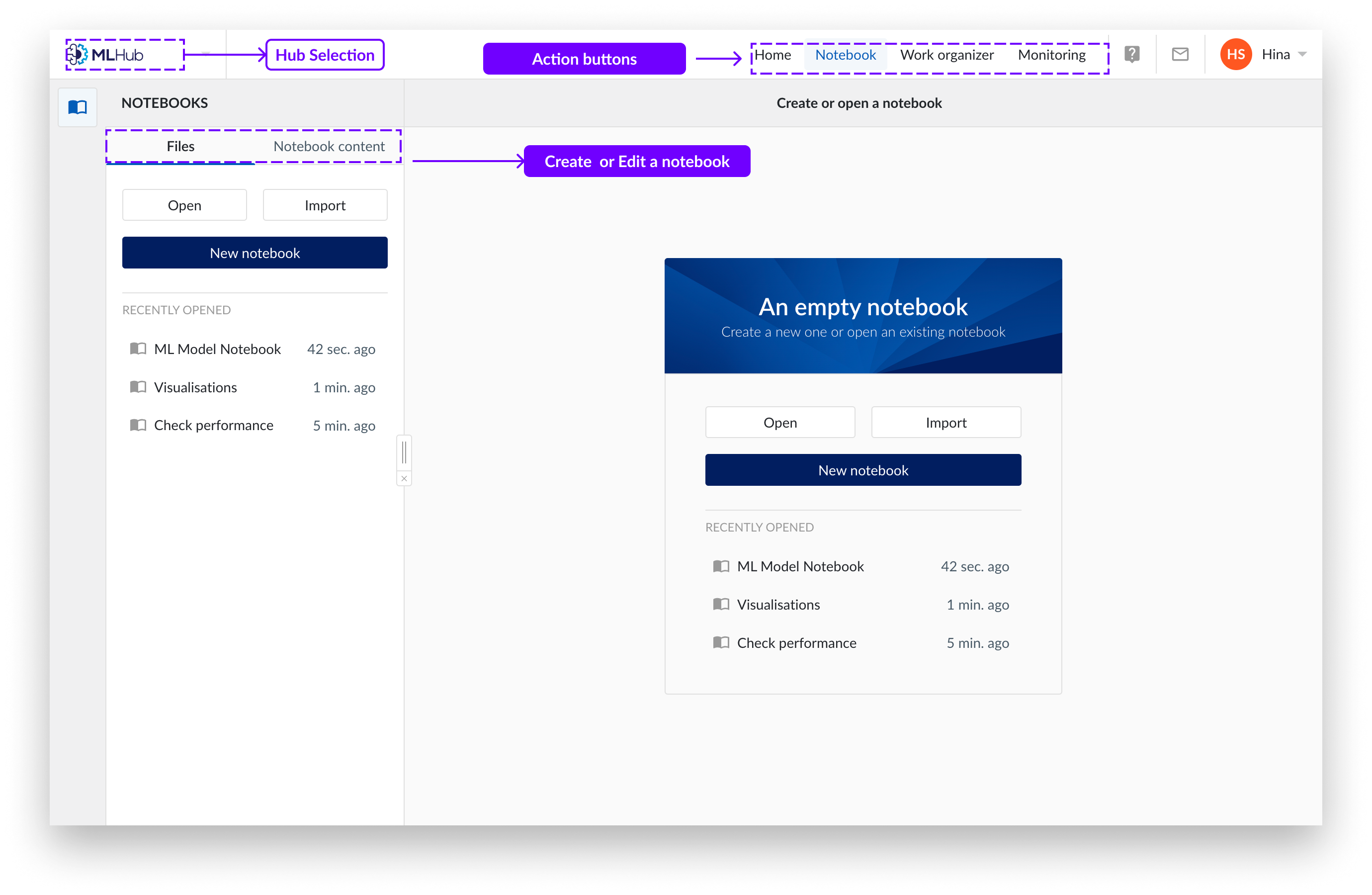
In der oberen linken Ecke der TrendMiner-Umgebung finden Sie die Schaltfläche zur Auswahl des Hubs. Hier können Sie den Hub auswählen, zu dem Sie navigieren möchten.
Klicken Sie auf die Schaltfläche „MLHub“. Um den Startbildschirm zu schließen und auf „Dateien“ oder „Notizbuchinhalt“ zuzugreifen, klicken Sie darauf. Unter „Dateien“ können Sie Notizbücher erstellen, öffnen oder importieren. Unter „Notizbuchinhalt“ können Sie Notizbücher bearbeiten.
Über die obere Leiste können Sie zu „Startseite“, „Notizbücher“, „Arbeitsplaner“ und „Überwachung“zurückkehren .
Die Notebook-Funktionalität von TrendMiner ist eine Plattform, die es Benutzern ermöglicht, innerhalb der TrendMiner-Umgebung über die robusten integrierten Funktionen hinaus erweiterte Tools zu erstellen und damit zu arbeiten.
Mit eingebetteten Notebooks können Sie:
Laden Sie Daten aus einer TrendHub-Ansicht, die mit den typischen integrierten TrendMiner-Funktionen entwickelt wurde (Auswahl interessanter Tags, Auswahl interessanter Zeiträume, z. B. über Suchanfragen, …).
Visualisieren und analysieren Sie Ihre Daten auf verschiedene Arten, die innerhalb von TrendHub nicht möglich sind.
Führen Sie die Automatisierung von Analysen über Skripte durch (z. B. Wiederholung von Analysen über einen großen Bereich von Assets).
Erstellen Sie (vorausschauende) Tags mithilfe benutzerdefinierter Modelle (z. B. neuronale Netze oder Clustering), die von den typischen Notebook-Bibliotheken unterstützt werden.
Sie können die erweiterten Visualisierungsoptionen nutzen, die im Notebook integriert sind. Das eingebettete Notebook verfügt über eine eigene Notebook-Kachel, sodass Sie Ihre Arbeit auch in ein DashHub-Dashboard einbetten und Ihrem gesamten Unternehmen zur Verfügung stellen können.
Anmerkung
Interpreter – Der Standardinterpreter der Notebooks ist Python.
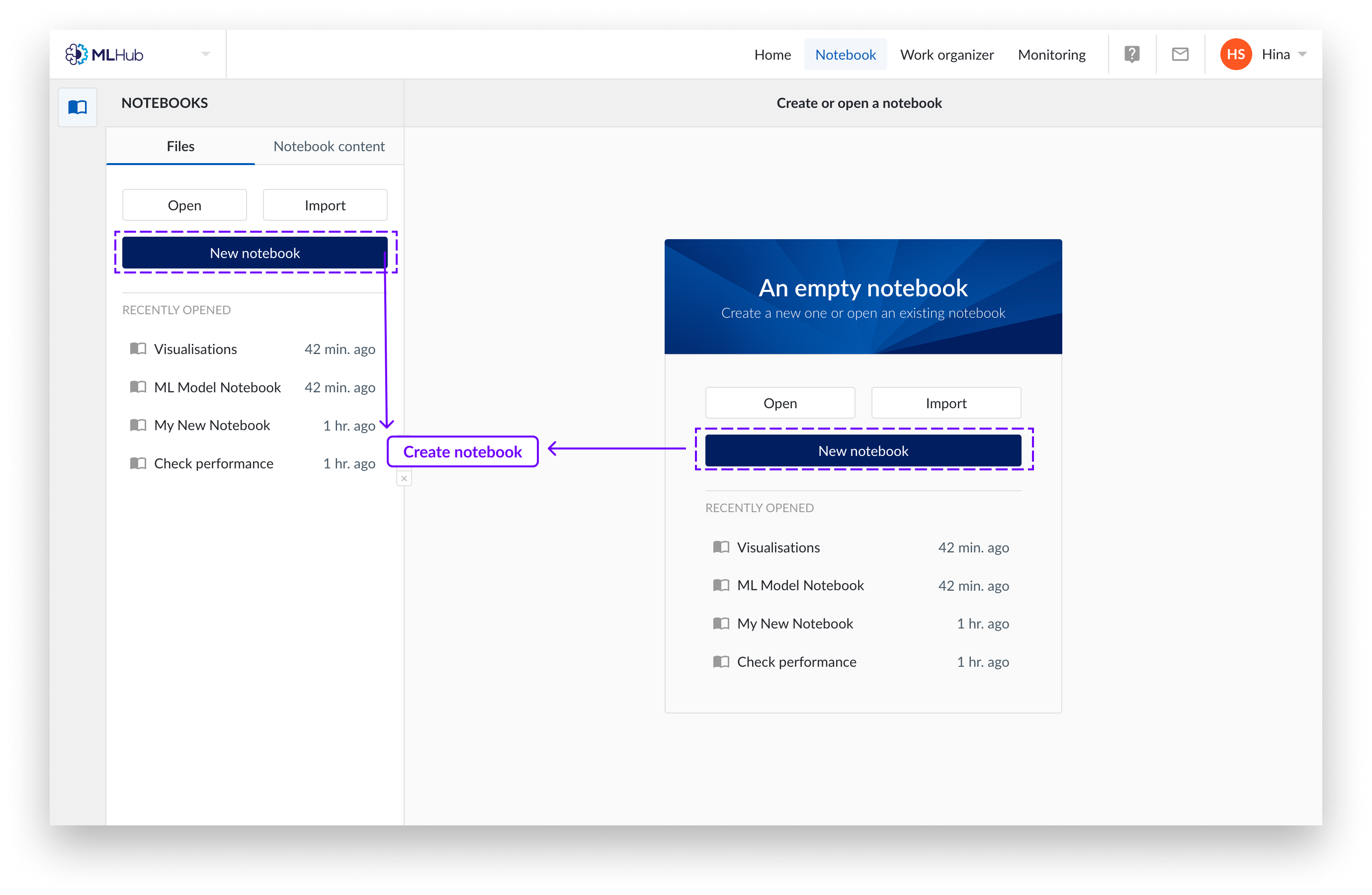
Auf der Registerkarte „Notizbuch“ von MLHub können Sie entweder ein neues Notizbuch erstellen oder eine vorhandene Notiz laden oder importieren. Ein neues Notizbuch ist immer leer.
Klicken Sie auf die Registerkarte „Dateien“ von MLHub.
Klicken Sie auf„Neues Notizbuch“.
Füllen Sie die offenen Felder aus und wählen Sie einen Arbeitsordner aus, in dem Ihr neues Notizbuch gespeichert werden soll.
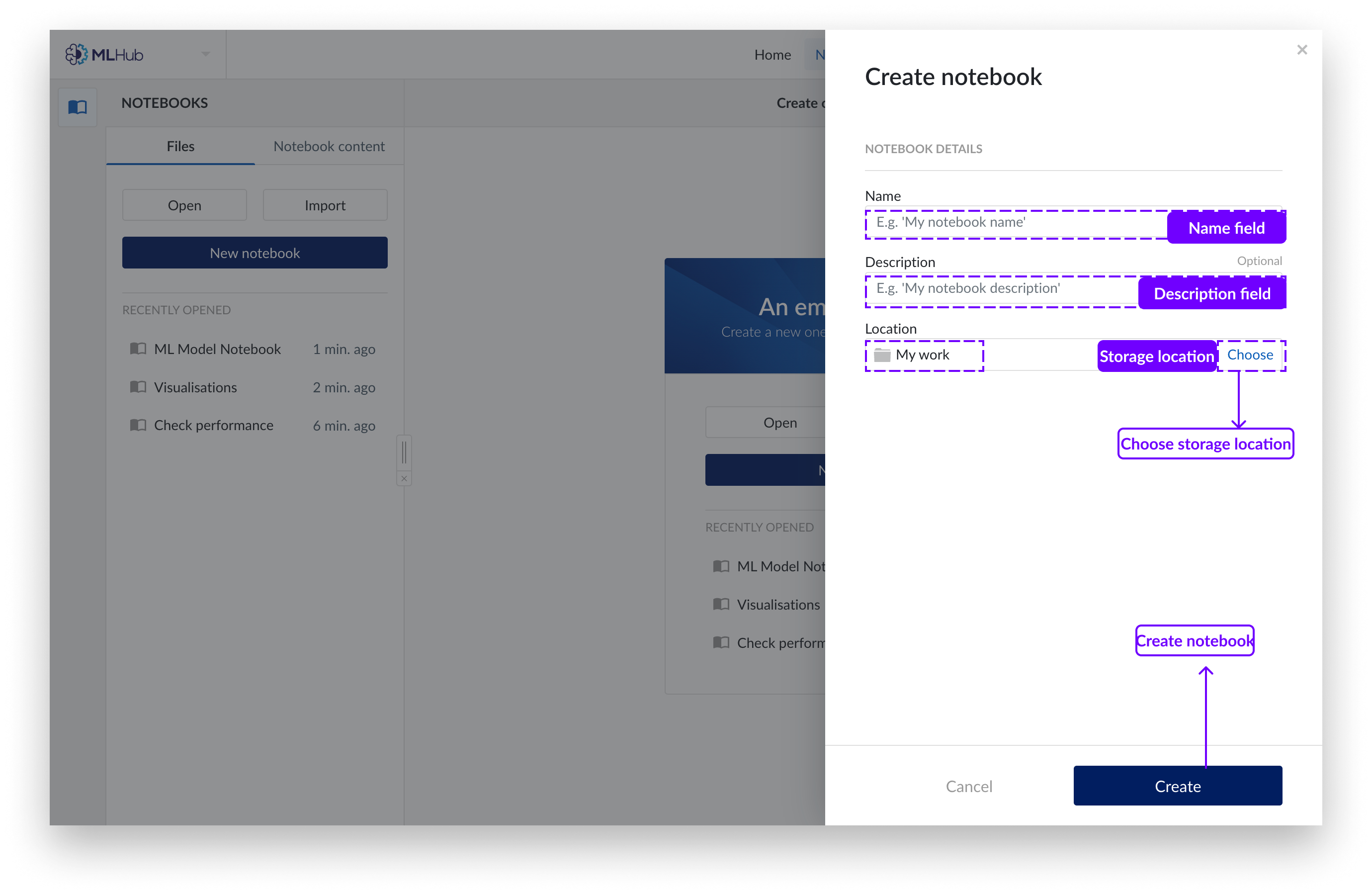
Klicken Sie auf die Schaltfläche „Erstellen“.
Sie gelangen nun in den Modus „Notizbuchinhalt“ mit Codeausschnitten im linken Seitenbereich. Dabei handelt es sich um vordefinierte Codeblöcke, die Sie in Ihren Notizbüchern verwenden können. Weitere Informationen finden Sie unter „Codeausschnitte“ weiter unten.
Wählen Sie die Kernel-Konfiguration, die Sie starten möchten. Wir bieten Kernel mit vorinstallierten Visualisierungspaketen an. Wir empfehlen Ihnen, mit dem Kernel „Python 3.11 auf Kubernetes“ zu starten.
Bestätigen Sie Ihre Auswahl , indem Sie auf „Auswählen“ klicken .
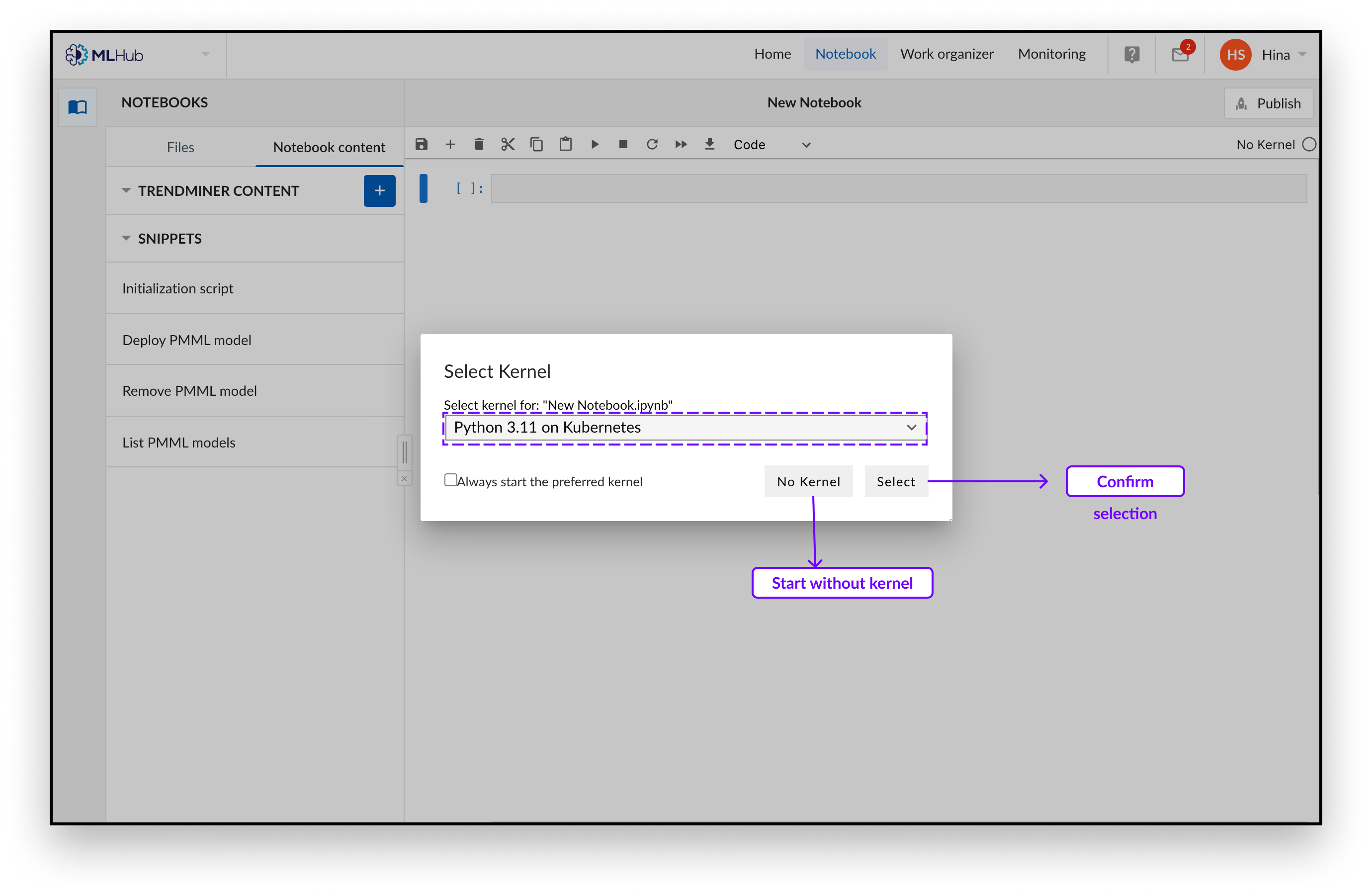
Sie können nun Ihren Python-Code in das erstellte Notizbuch schreiben. Möglicherweise möchten Sie unseren Boilerplate-Code einfügen, der dringend empfohlene Pakete lädt, da Sie diesen zum Einlesen der TrendMiner-Inhalte benötigen. Sie können diesen Code hinzufügen, indem Sie im Snippet-Menü auf der linken Seite auf die Schaltfläche „Initialisierungsskript“ klicken.
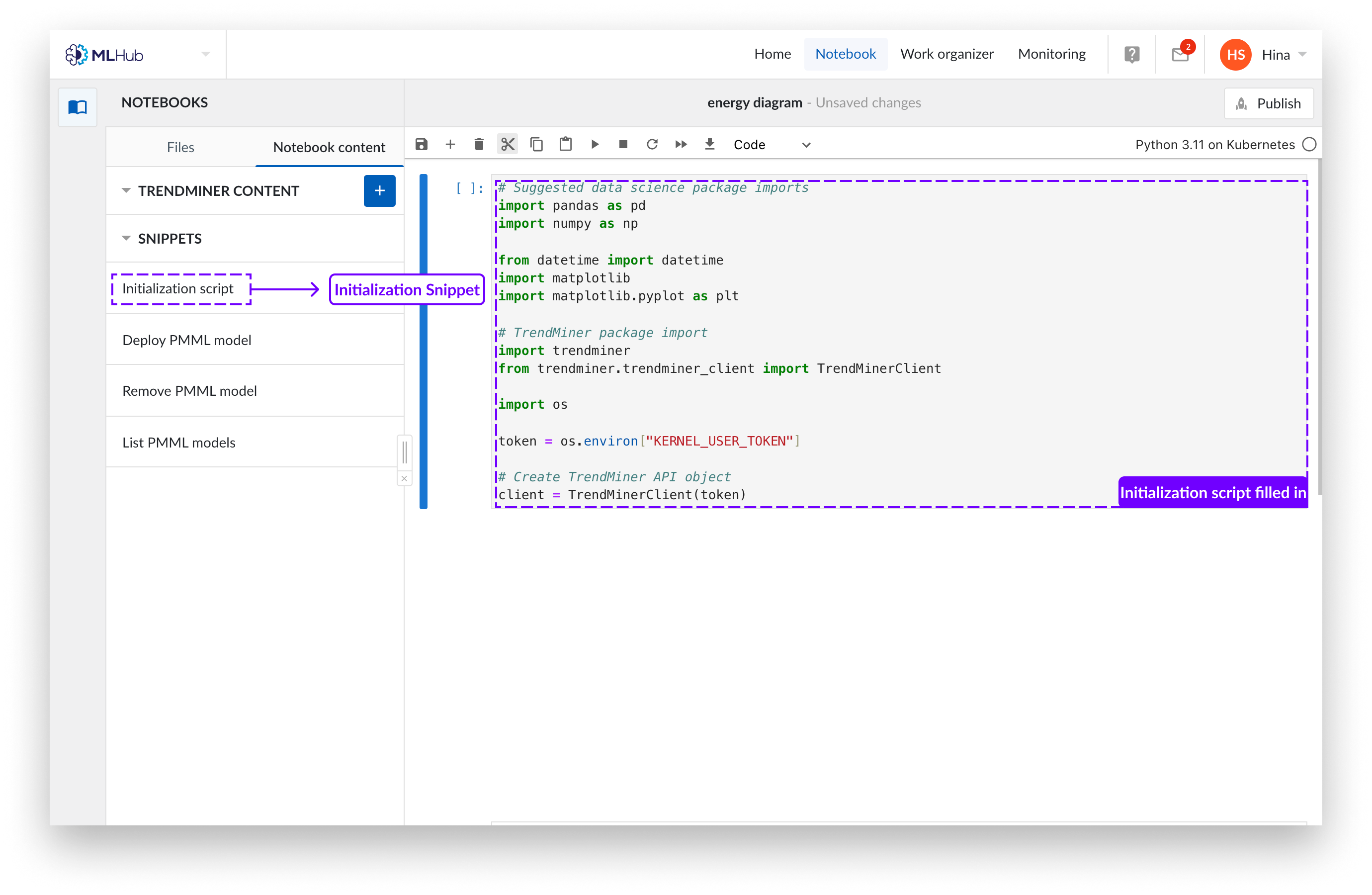
Notizbuch öffnen
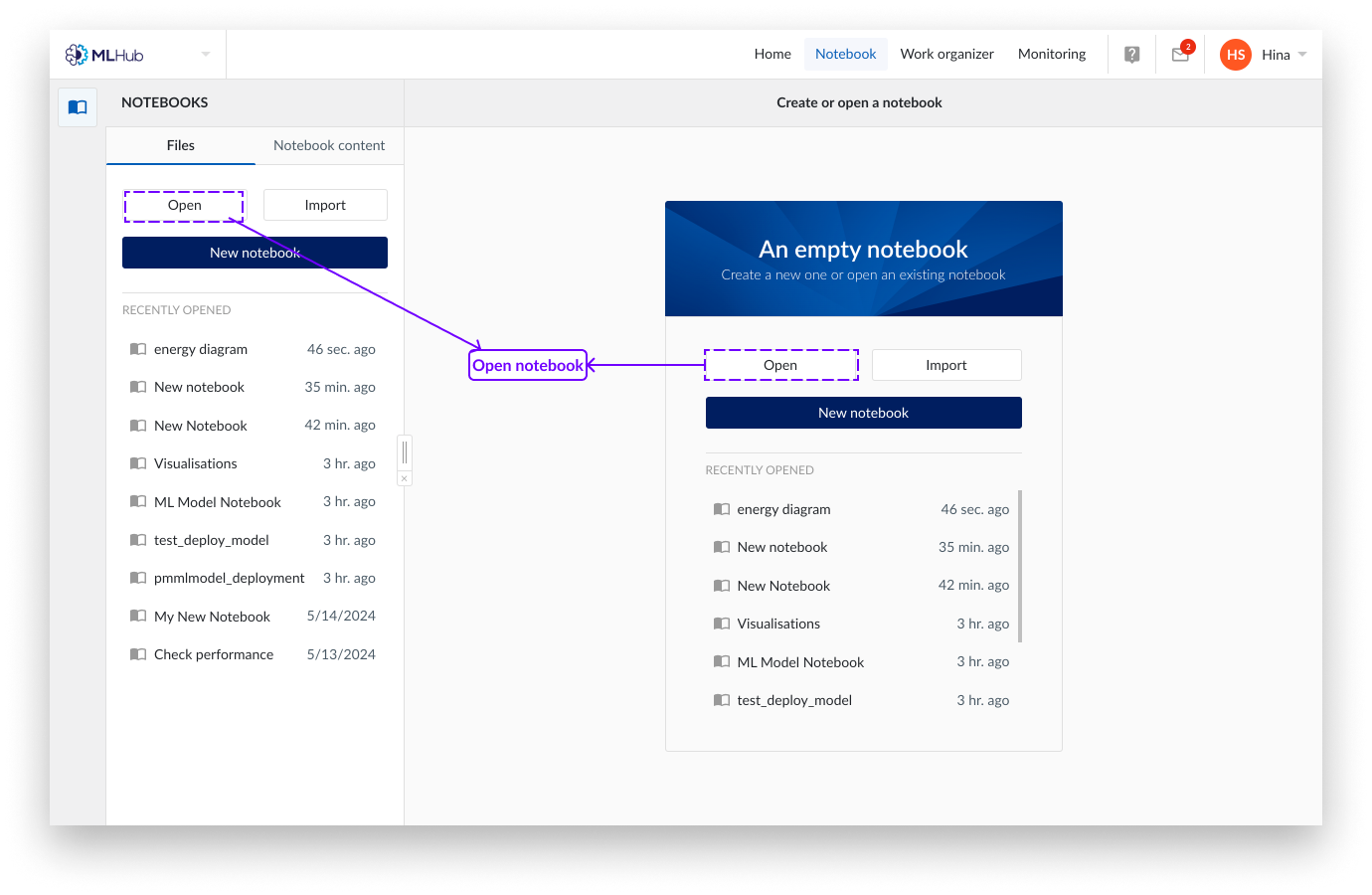
Klicken Sie auf die Registerkarte„Dateien“ von MLHub.
Klicken Sie auf„Öffnen“.
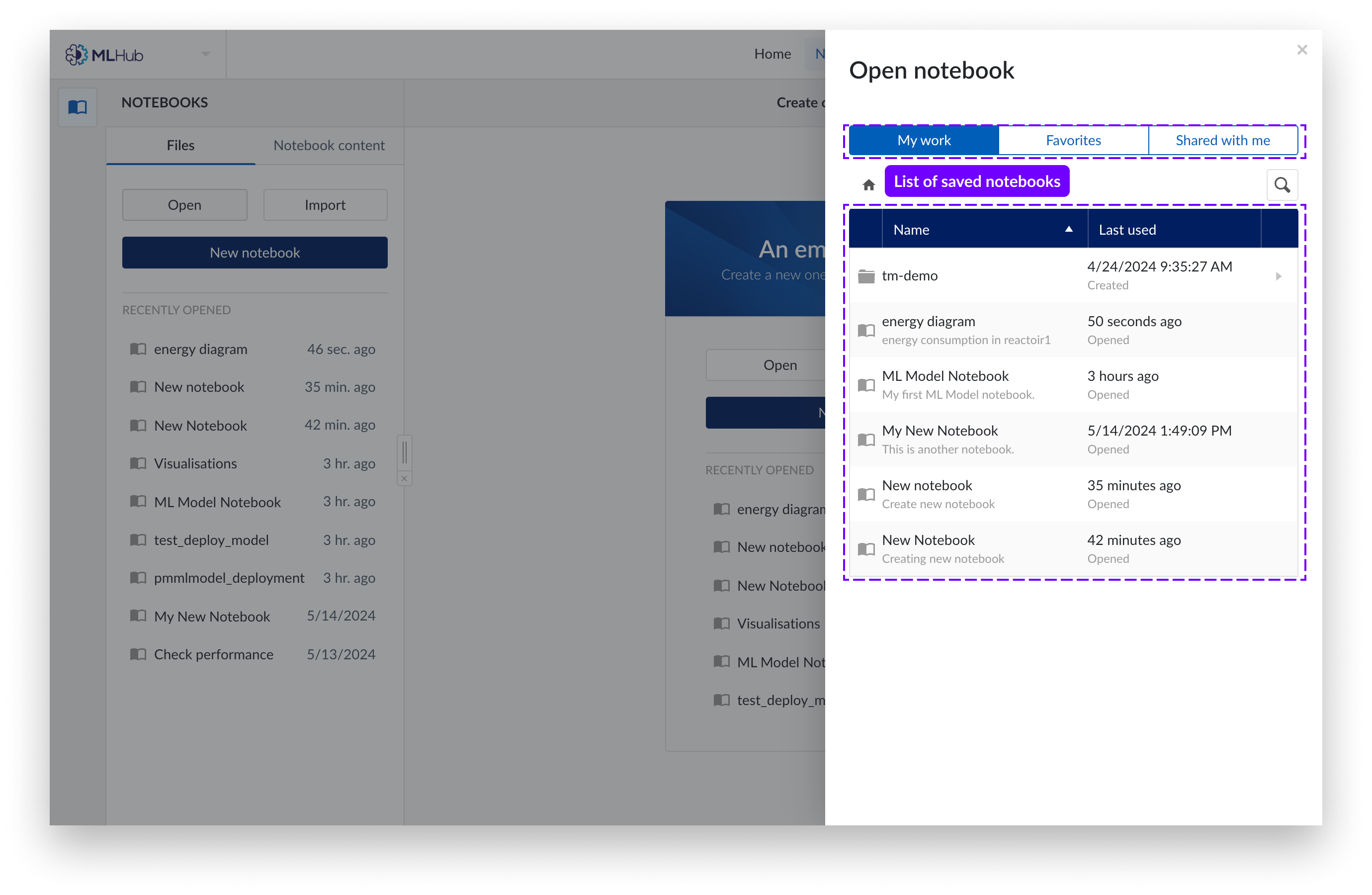
Sie können Ihre Notizbücher nun unter „Meine Arbeit“ oder„Favoriten“ anzeigen. Klicken Sie auf das Notizbuch, das Sie öffnen möchten.
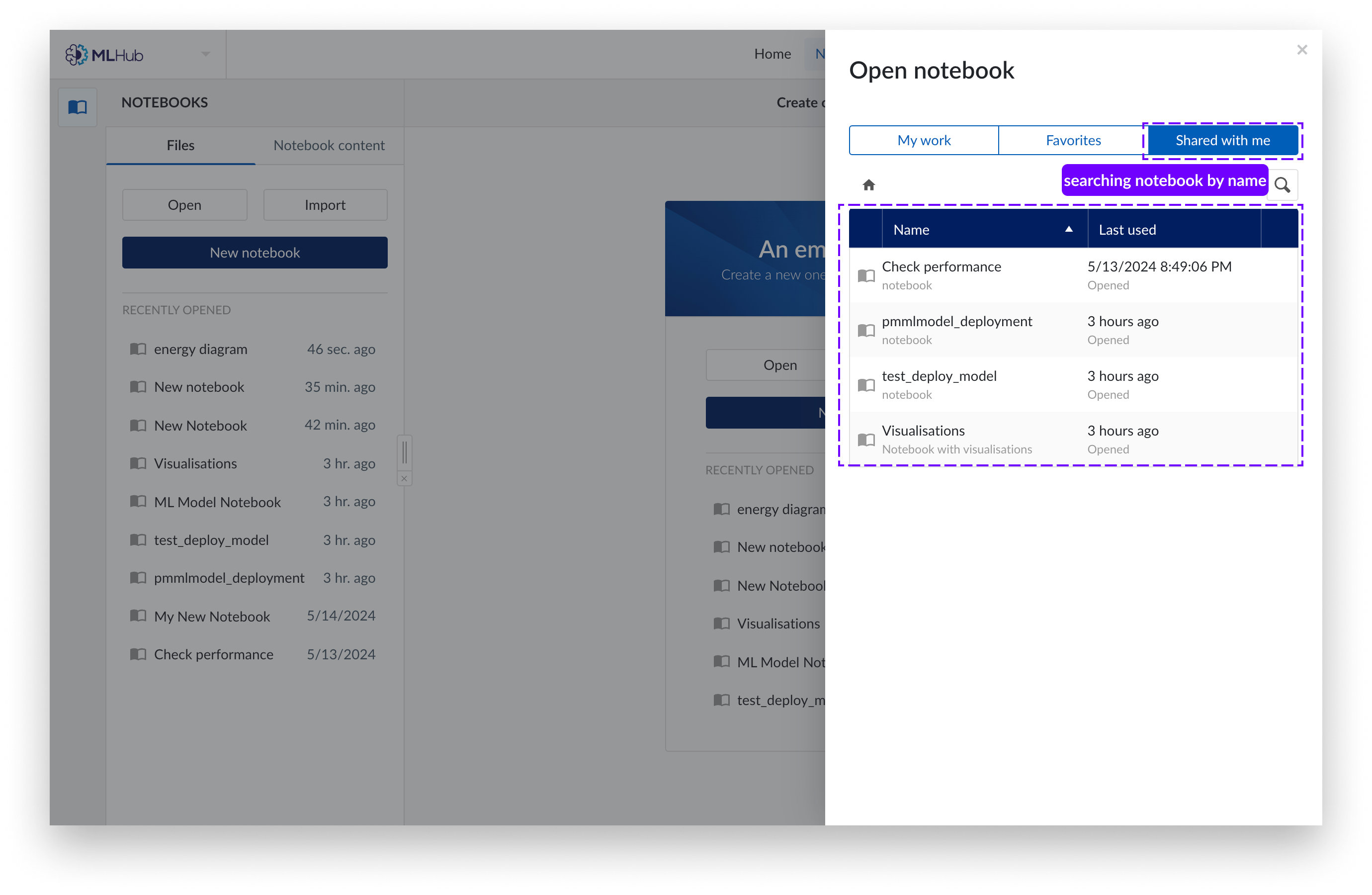
Sie können auch auf Notizbücher zugreifen, die andere Benutzer für Sie freigegeben haben, unter „Für mich freigegeben “.
Klicken Sie auf die Registerkarte„Dateien“ von MLHub.
Klicken Sie auf die Schaltfläche„Importieren“.
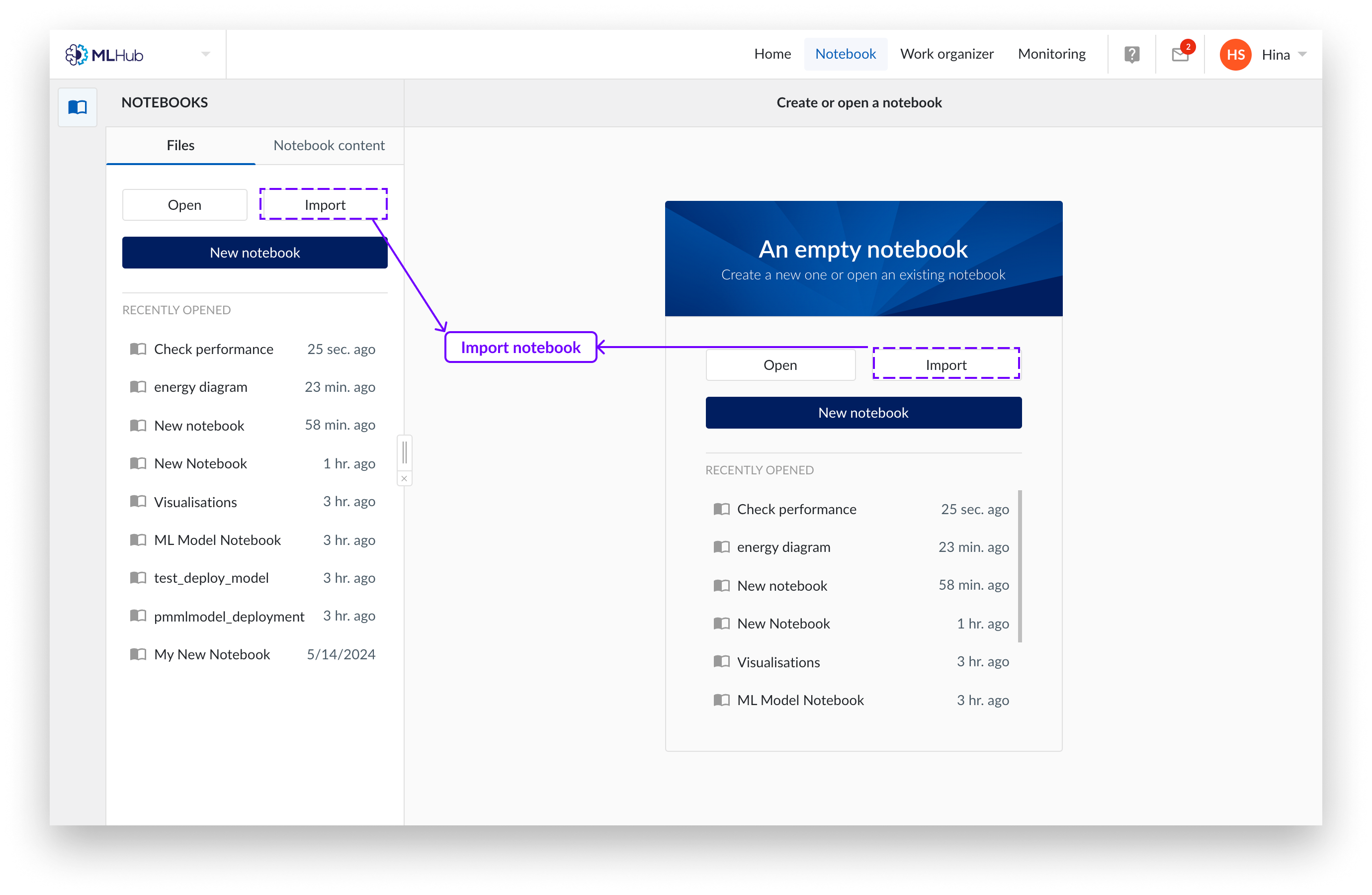
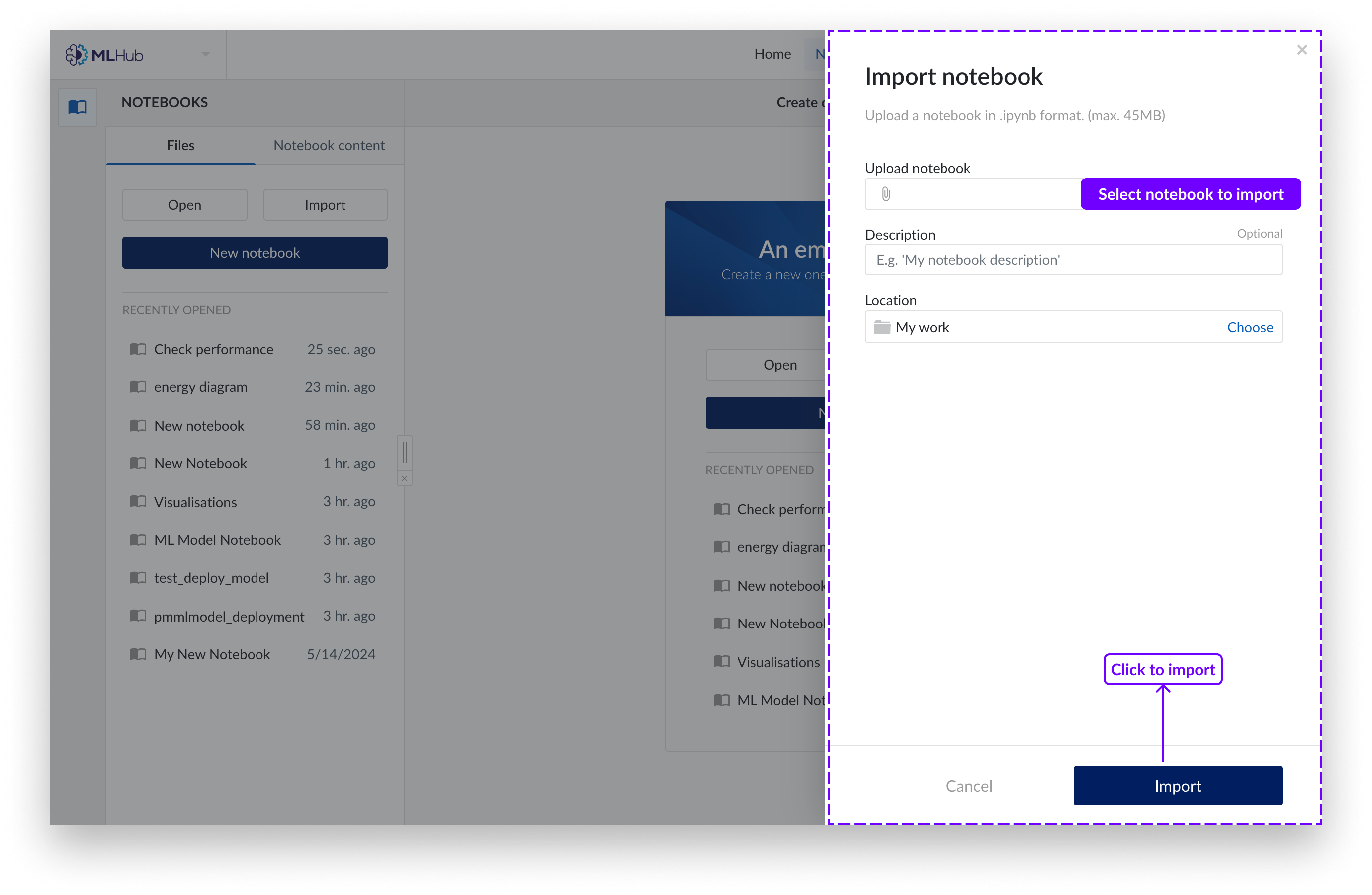
Auf der rechten Seite des Bildschirms erscheint ein Fenster. Wählen Sie, ob Sie ein Notizbuch mit Ihrem lokalen Dateibrowser hochladen oder den Arbeitsorganisator verwenden möchten. Es werden nur Jupyter-Notizbücher (Dateiendung .ipynb) unterstützt.
Wählen Sie „Importieren“.
Anmerkung
Ab Version 2022.R2 sind nur „TrendHub Views“ und „ContextHub Views“ als TrendMiner-Inhalte verfügbar. Weitere Inhalte werden in späteren Versionen eingeführt.
Sie können TrendHub- oder ContextHub-Ansichten, beispielsweise von normalen und/oder abnormalen Betriebsperioden, laden und diese mithilfe erweiterter Analysen vergleichen und zu Ihrer TRENDMINER CONTENT-Liste hinzufügen.
Klicken Sie auf die blaue Schaltfläche „+“. Auf der rechten Seite erscheint ein Seitenbereich.
Wählen Sie die gespeicherten Ansichtselemente aus, die Sie als Datensatz hinzufügen möchten.
Klicken Sie auf „Laden“.
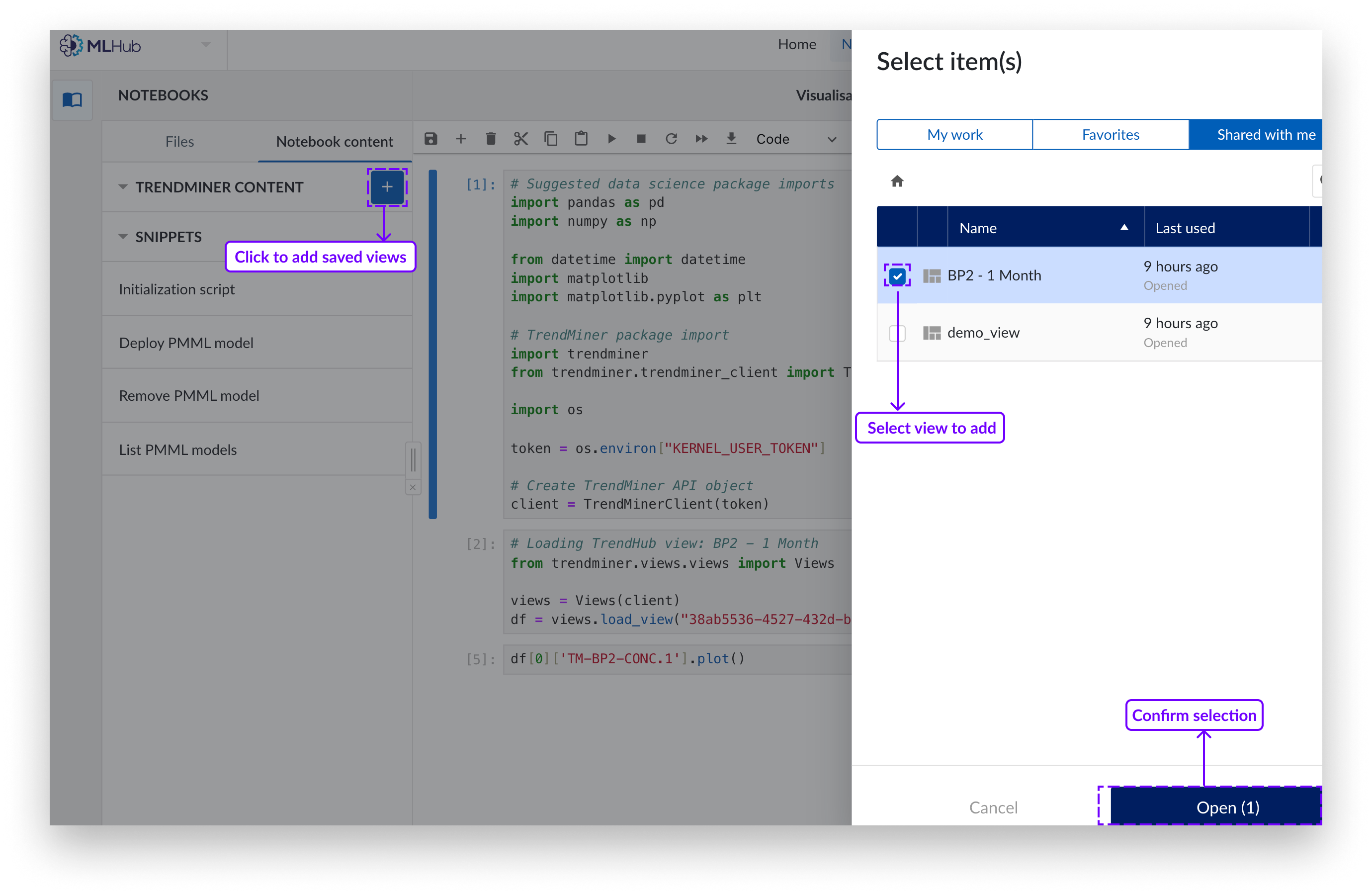
Die Elemente in der Inhaltsmenüliste können entweder geöffnet oder gelöscht werden. Zum Löschen klicken Sie auf das „x“ im Menü rechts neben dem zu löschenden Element.
Klicken Sie auf den neuen Inhalt, um ihn zu öffnen. Dadurch wird der entsprechende Python-Code in eine neue Zelle am Ende des Notebooks eingefügt.
Wenn für ein TrendMiner-Dashboard ein globaler Zeitrahmen festgelegt ist, wird dieses Zeitfenster nun automatisch an alle MLHub-Notebook-Kacheln auf diesem Dashboard weitergegeben. Auf diese Weise können Ihre Notebooks dynamisch auf den vom Benutzer ausgewählten Zeitrahmen reagieren, ohne dass Sie Daten in Ihrem Code fest codieren müssen.
So funktioniert es
Wenn ein Benutzer einen globalen Zeitrahmen auf einem TrendMiner-Dashboard festlegt, werden die ausgewählten Start- und Endzeitstempel als Umgebungsvariablen in den Kernel des Notebooks eingefügt:
Variable | Beschreibung | Format |
|---|---|---|
| Beginn des ausgewählten Zeitraums | ISO 8601 (z. B. |
| Ende des ausgewählten Zeitraums | ISO 8601 (z. B. |
Diese Variablen sind verfügbar, sobald der Notebook-Kernel gestartet wird.
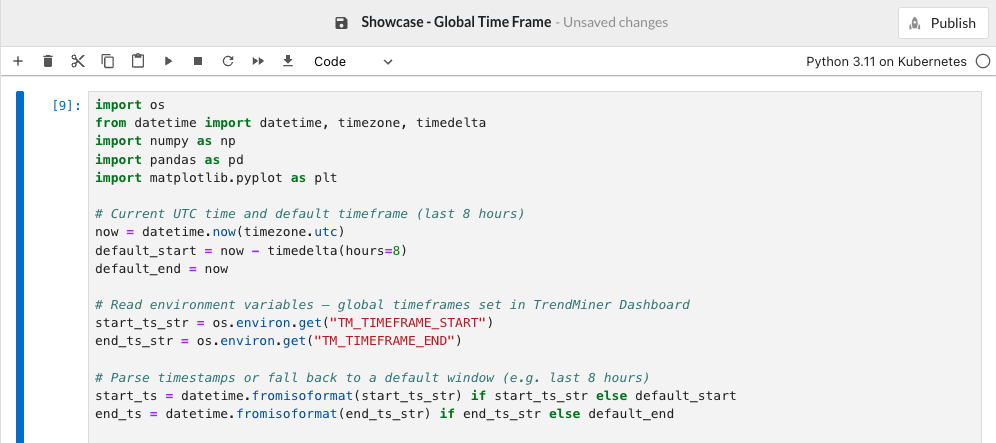
Verwenden Sie os.environ.get(), um die Variablen sicher zu lesen. Stellen Sie immer eine sinnvolle Ausweichlösung bereit, falls das Notebook außerhalb eines Dashboard-Kontexts ausgeführt wird.
Anmerkung
Die Umgebungsvariablen werden nur gesetzt, wenn das Notizbuch über eine Dashboard-Kachel ausgelöst wird, für die ein globaler Zeitrahmen konfiguriert ist. Wenn Sie ein Notizbuch direkt in MLHub öffnen oder wenn auf dem Dashboard kein globaler Zeitrahmen festgelegt ist, sind TM_TIMEFRAME_START und TM_TIMEFRAME_END auf NONE gesetzt. Behandeln Sie diesen Fall immer mit einem Fallback in Ihrem Code (siehe Beispiele unten). Der Zeitrahmen ist auch für die Lebensdauer des Kernels festgelegt und wird nicht automatisch aktualisiert, wenn der Benutzer den Zeitrahmen des Dashboards ändert. Dies geschieht erst bei der Aktualisierung des Dashboards.
Beispiel:
import os
from datetime import datetime, timezone, timedelta
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Current UTC time and default timeframe (last 8 hours)
now = datetime.now(timezone.utc)
default_start = now - timedelta(hours=8)
default_end = now
# Read environment variables — global timeframes set in TrendMiner Dashboard
start_ts_str = os.environ.get("TM_TIMEFRAME_START")
end_ts_str = os.environ.get("TM_TIMEFRAME_END")
# Parse timestamps or fall back to a default window (e.g. last 8 hours)
start_ts = datetime.fromisoformat(start_ts_str) if start_ts_str else default_start
end_ts = datetime.fromisoformat(end_ts_str) if end_ts_str else default_end
# Generate synthetic data
timestamps = pd.date_range(start=start_ts, end=end_ts, freq="1min")
values = np.random.random(len(timestamps))
# Create DataFrame and plot
df = pd.DataFrame({"ts": timestamps, "value": values})
df.set_index('ts').plot(title="Synthetic Time Series")
plt.xlabel("Timestamp")
plt.ylabel("Value")
plt.tight_layout()
plt.show()
print("end")Weitere Informationen erhalten Sie, indem Sie den folgenden Befehl im Notizbuch ausführen:
help(trendminer.dataframes.data_frames)
load_view( ): Lädt die Zeitreihendaten einer gespeicherten TrendHub-Ansicht in eine Liste von Pandas DataFrames.
Pro Ebene in der Ansicht wird ein DataFrame zurückgegeben.
Jeder DataFrame kann über einen anderen Satz von Tags verfügen.
Mit den optionalen Parametern [layer_ids] können Sie nur eine bestimmte Liste von Ebenen laden (identifiziert durch die Ebenen-IDs, die von der Funktion view_info bereitgestellt werden).
view_info( ): Sammelt Informationen über eine Ansicht anhand ihrer ID. Diese Informationen können zum Abrufen von Daten aus einer Ansicht verwendet werden: Es werden alle Ebenen aufgelistet, die in der Ansicht enthalten sind. Beim Abrufen von Daten aus der Ansicht können Sie Ebenen auswählen, die in die Daten aufgenommen werden sollen.
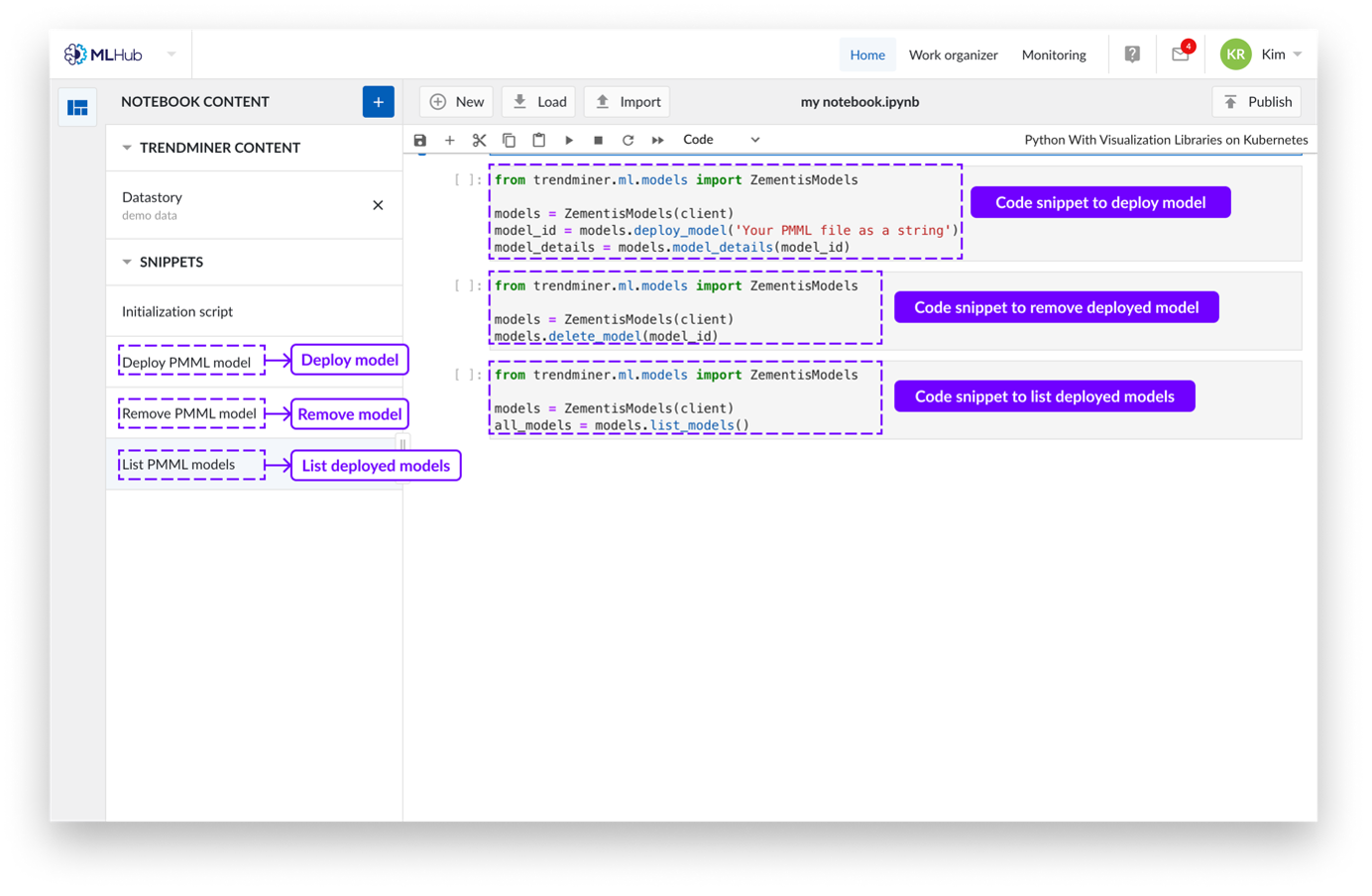
Ausschnitte
Derzeit sind Snippets in Python-Kernels zur Bereitstellung von Machine-Learning-Modellen einsetzbar.
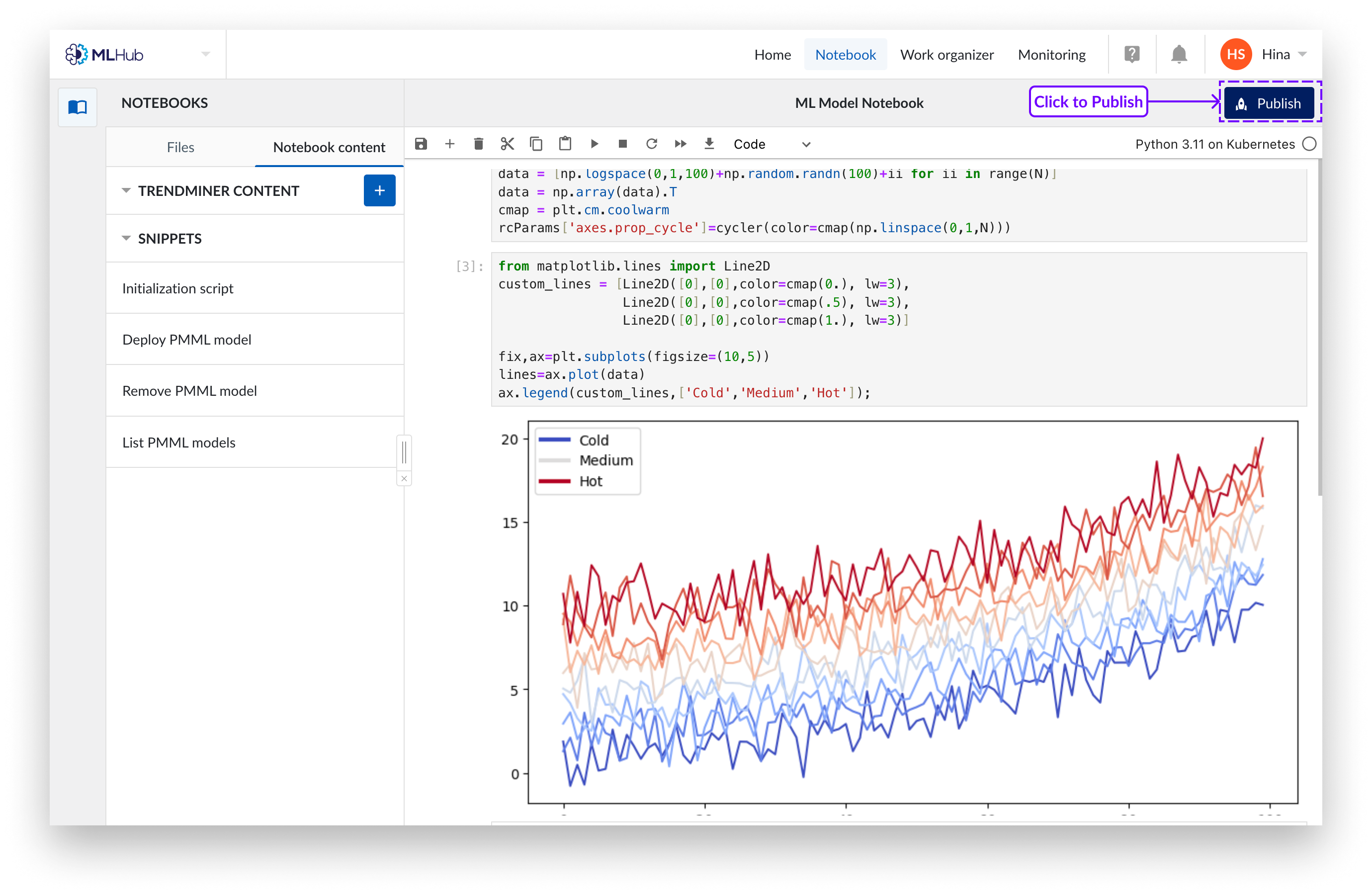
Wenn Sie eine Notebook-Ausgabezelle mit einem interessanten Ergebnis oder einer Visualisierung haben, die Sie teilen möchten, können Sie diese in einem Notebook-Pipeline-Objekt veröffentlichen.
Schritte:
Klicken Sie auf die Schaltfläche „Veröffentlichen“ in der oberen rechten Ecke.
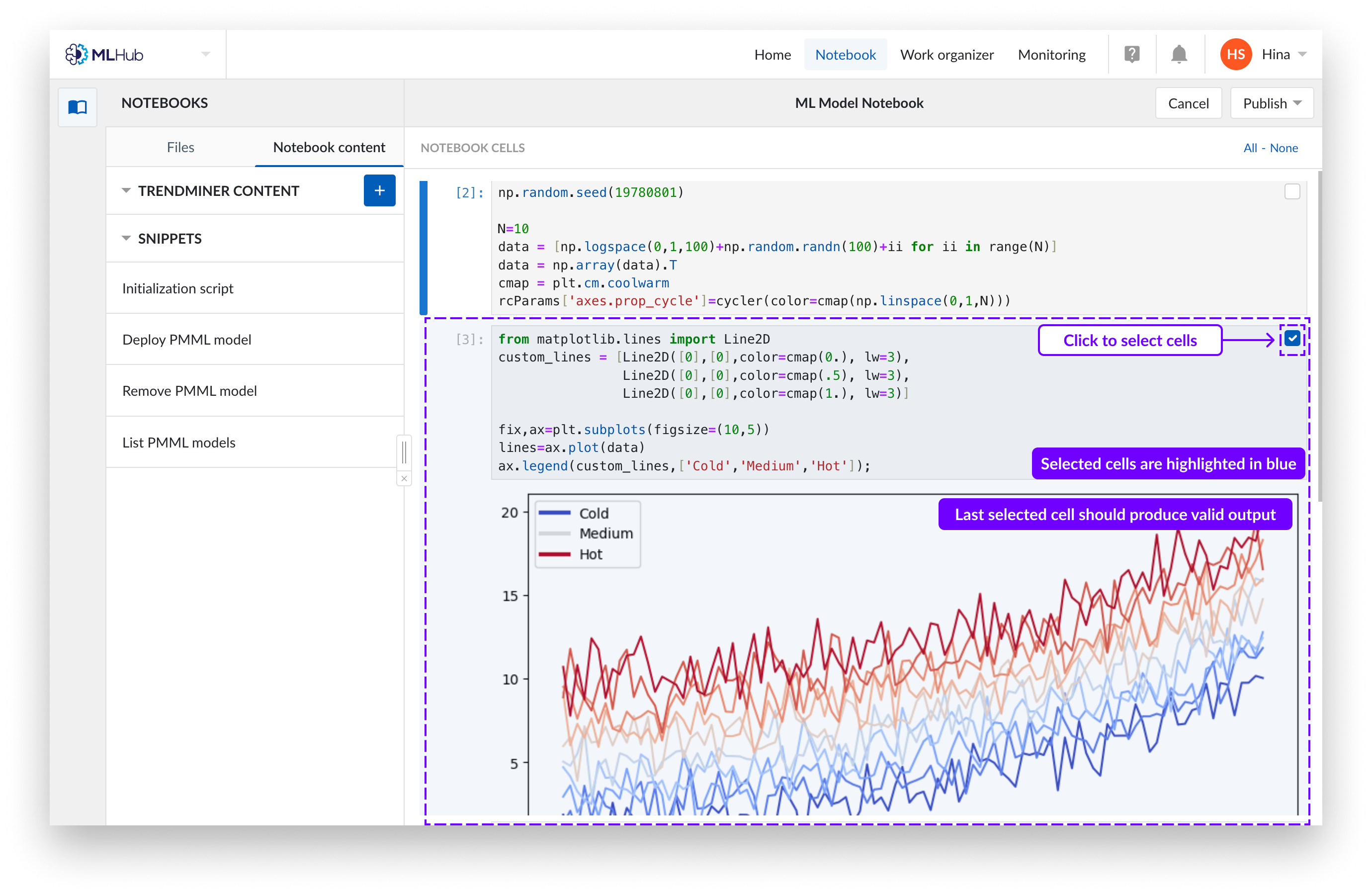
Wählen Sie ALLE Zellen aus, die für die gewünschte Ausgabe relevant sind, einschließlich „import“-Anweisungen und Variablendeklarationen. Stellen Sie sicher, dass die zuletzt ausgewählte Zelle eine gültige Ausgabe erzeugt. Sie können eine Zelle auswählen, indem Sie auf eine beliebige Stelle darin klicken, oder indem Sie die Kontrollkästchen in der oberen rechten Ecke verwenden.
Klicken Sie erneut auf „Veröffentlichen“. Es erscheint ein Dropdown-Menü, in dem Sie auswählen können, ob Sie das Notizbuch in einer neuen Pipeline veröffentlichen oder eine bestehende Pipeline überschreiben möchten.
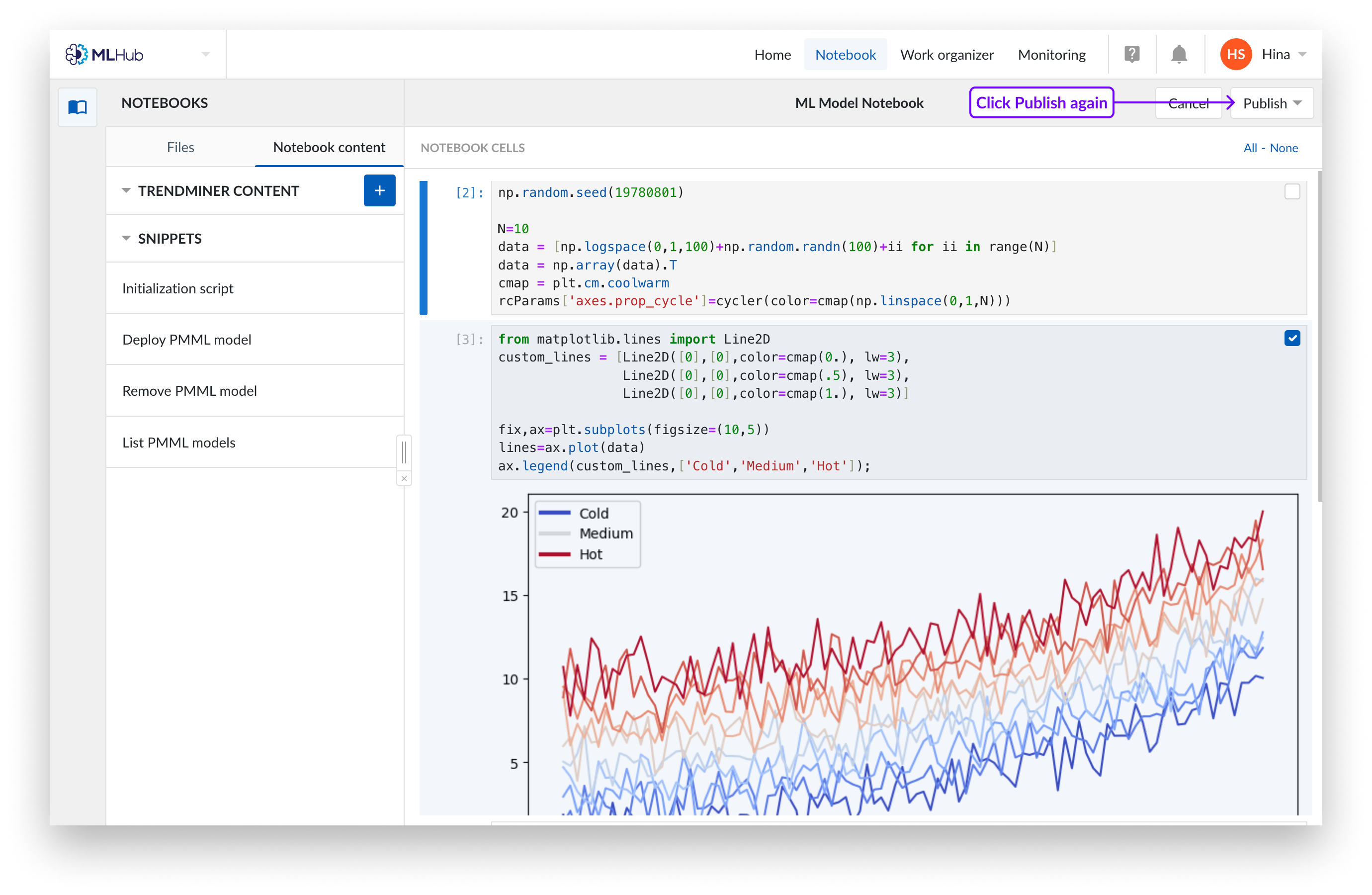
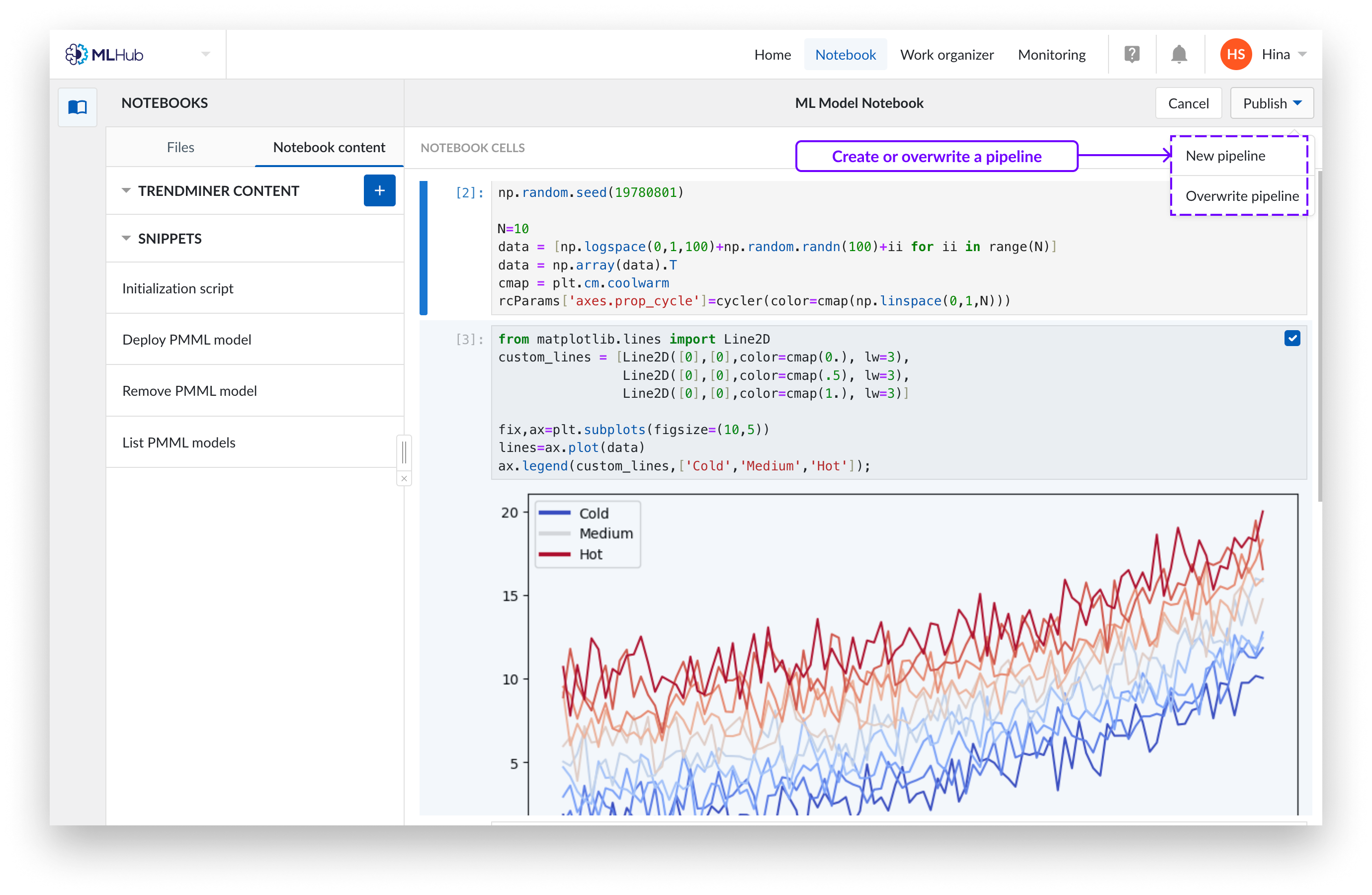
Um ein Notizbuch in einer neuen Pipeline zu veröffentlichen, geben Sie den Namen ein und legen Sie den Speicherort im Work Organizer fest. Klicken Sie auf „Veröffentlichen“, um die Auswahl zu bestätigen. Dadurch wird ein „Pipeline“-Objekt erstellt, bei dem es sich um ein Mini-Notizbuch handelt, das nur die ausgewählten Zellen enthält. Pipelines stehen in keiner Verbindung zu ihren ursprünglichen Notizbüchern, sondern sind eigenständige Einheiten.
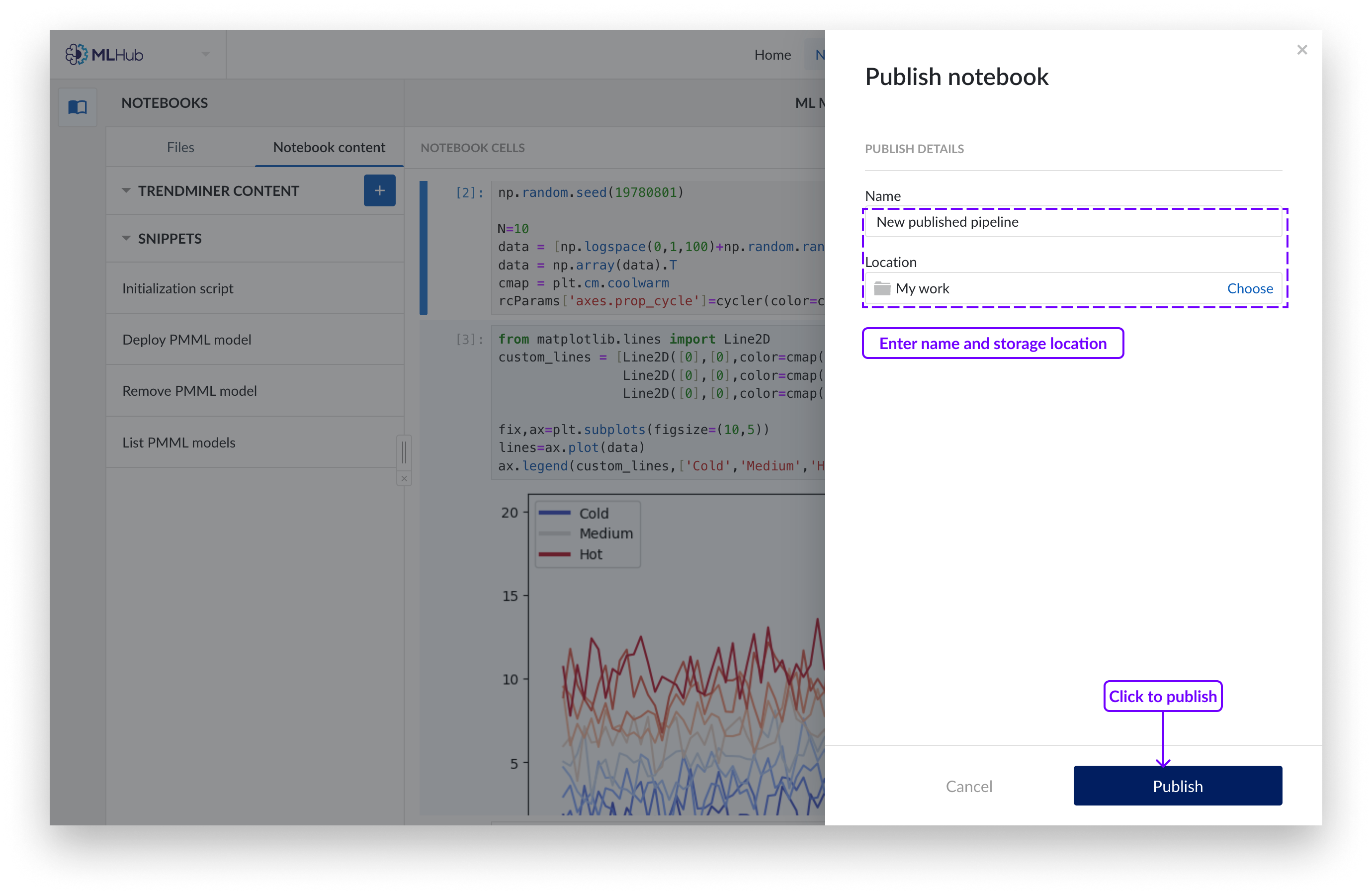
Anmerkung
Wenn Sie ein Notizbuch aktualisieren, müssen Sie auch ein neues Pipeline-Objekt erstellen.
Wenn Sie eine vorhandene Pipeline überschreiben möchten, wählen Sie die Pipeline, die Sie überschreiben möchten, im Work Organizer aus und klicken Sie auf„Veröffentlichen“.
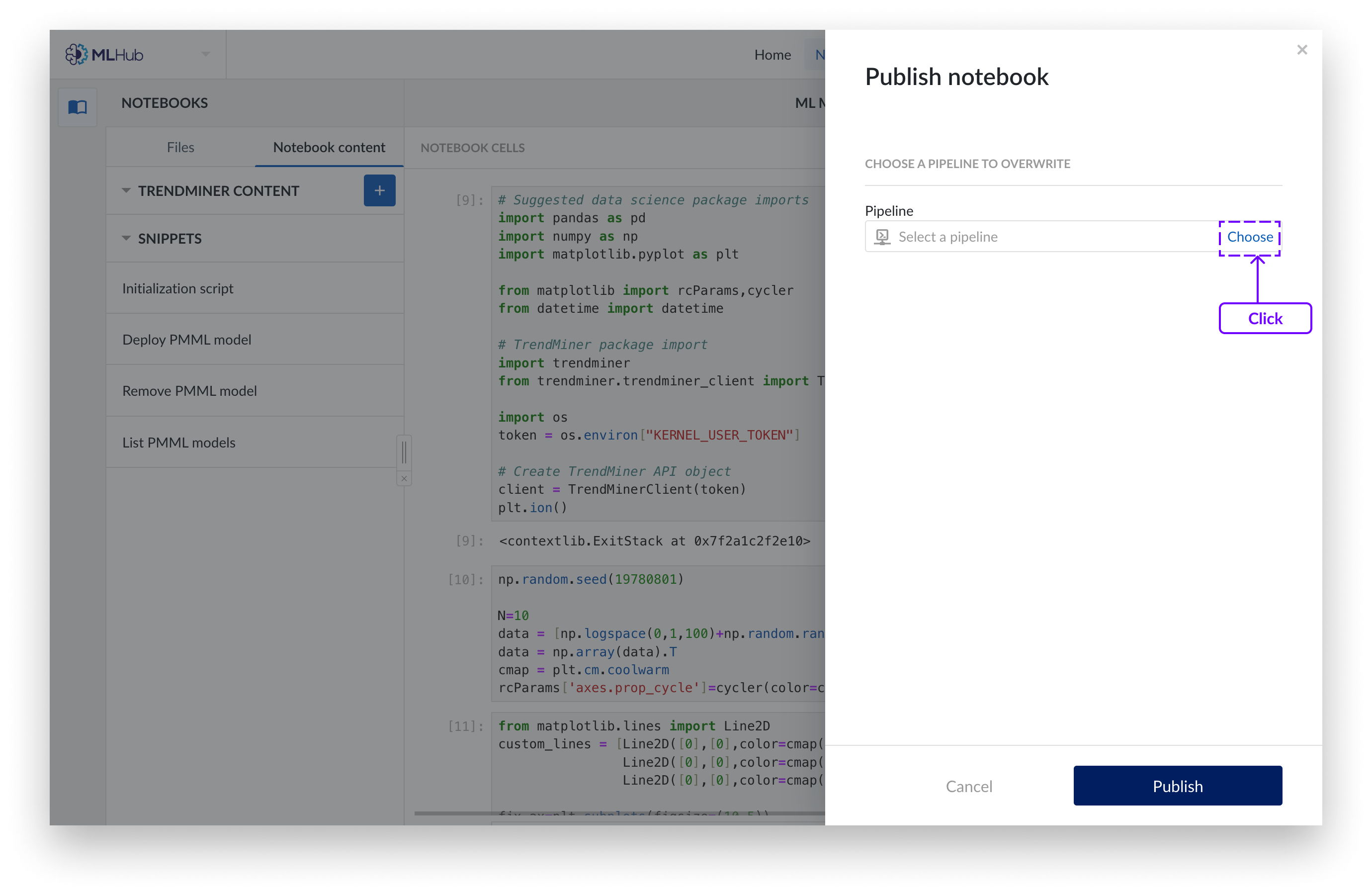
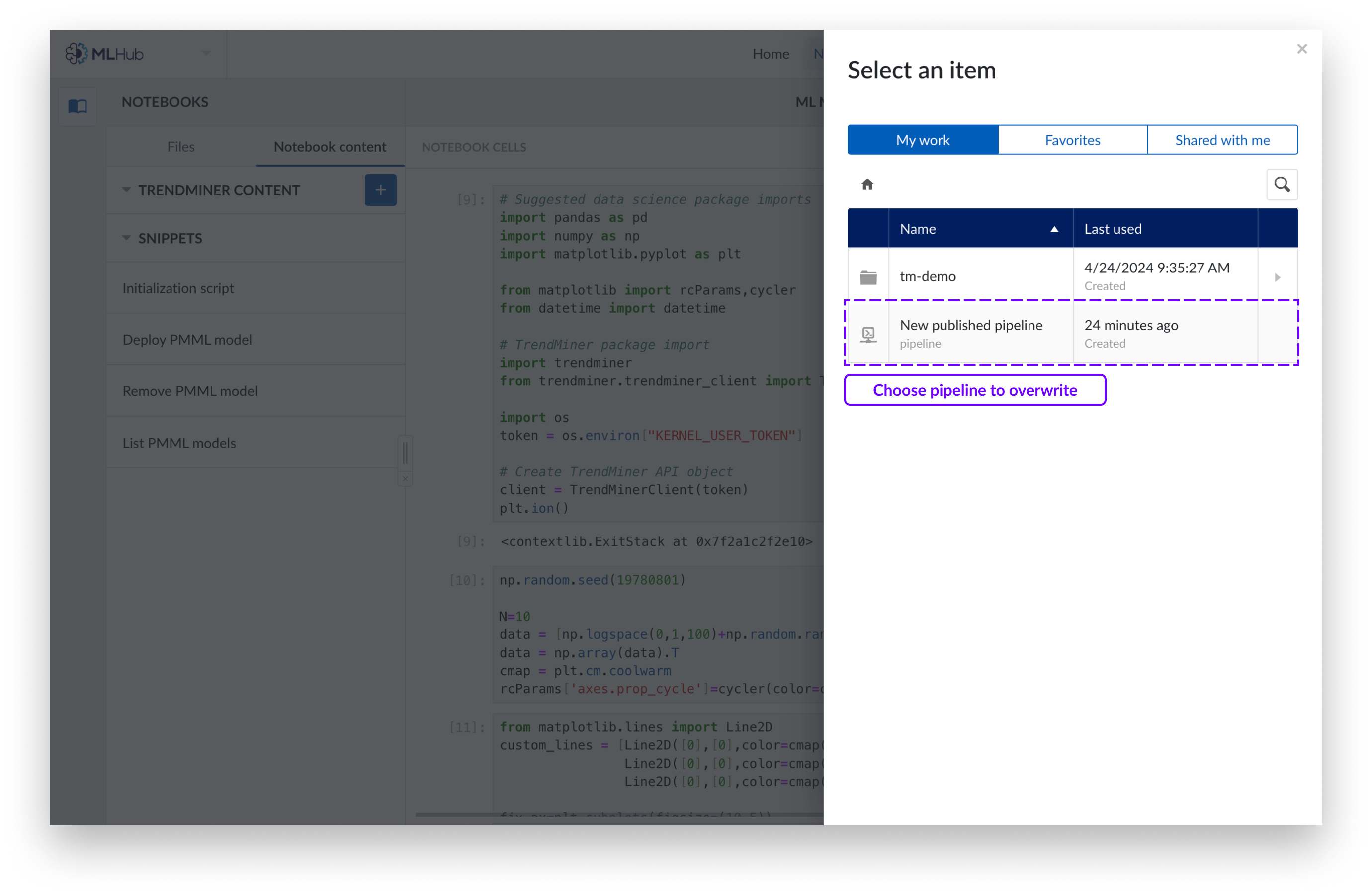
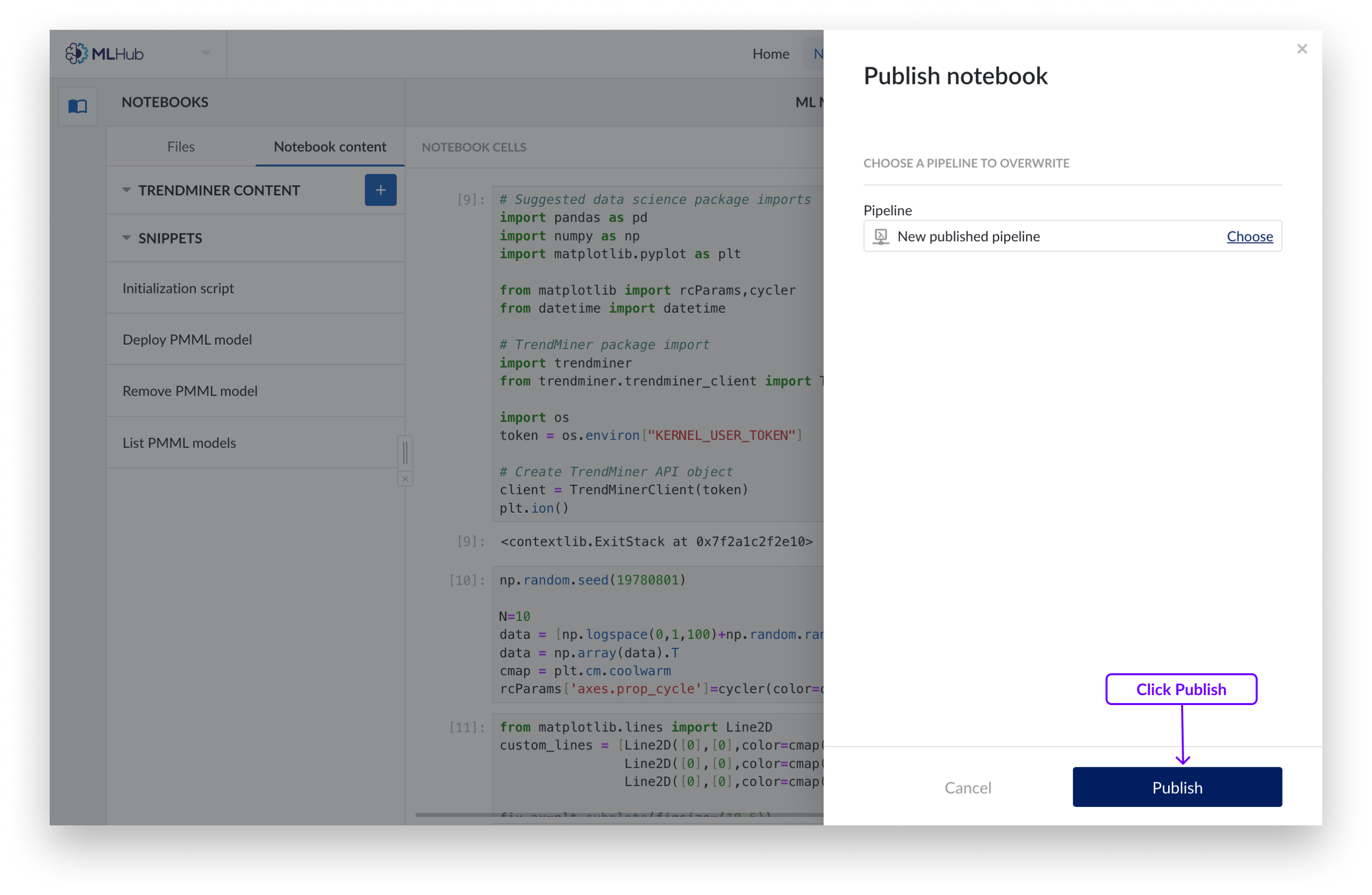
Sie verfügen nun über ein Pipeline-Objekt, das den Code der von Ihnen ausgewählten Zellen enthält.
Mit DashHub kann jede Ausgabe eines Notebook-Absatzes in einer Dashboard-Notebook-Kachel angezeigt werden.
Notizbuchkachel erstellen
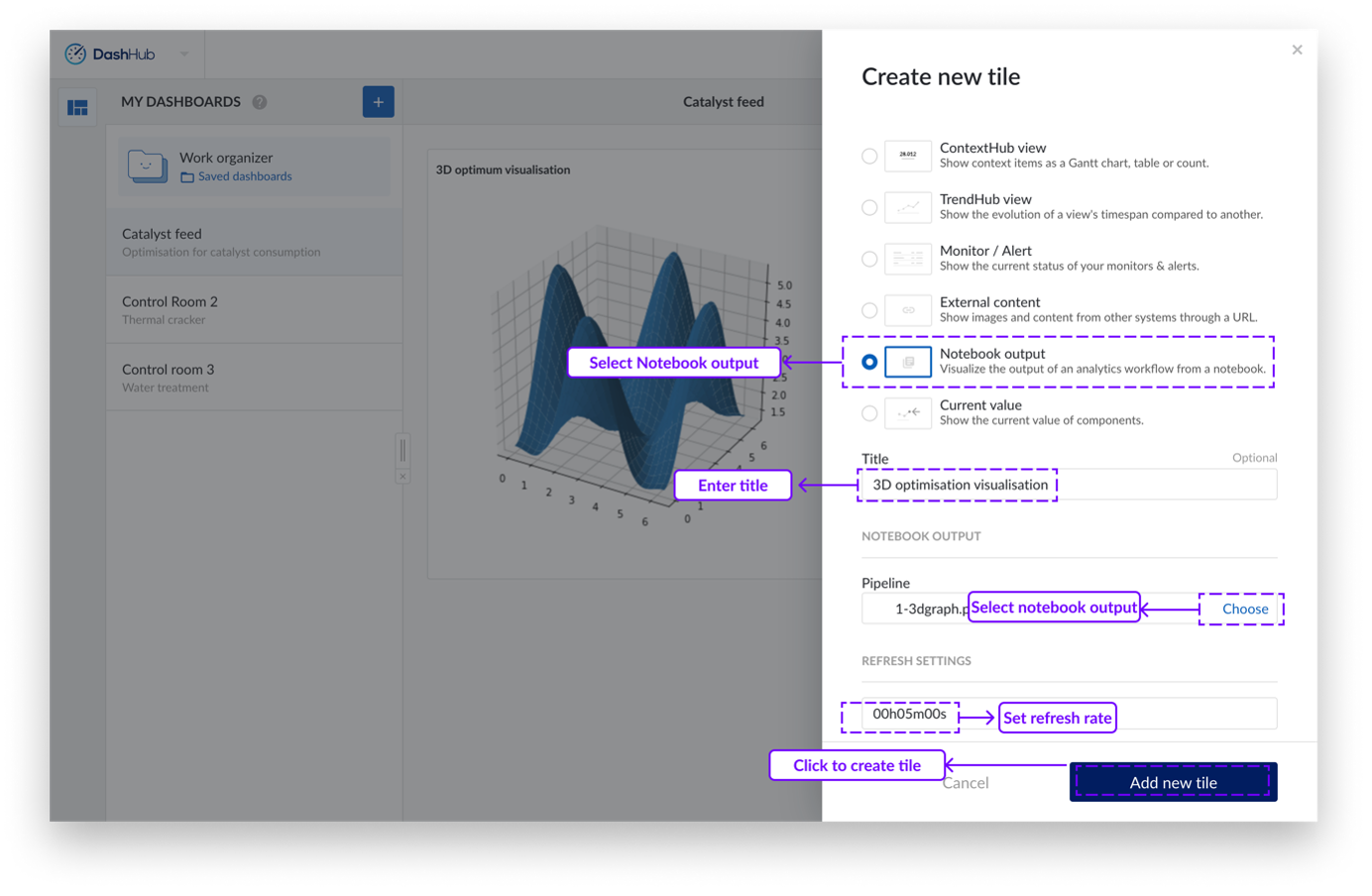
Gehen Sie zu DashHub und erstellen Sie ein neues Dashboard oder öffnen Sie ein zuvor erstelltes Dashboard.
Klicken Sie auf die Schaltfläche „Aktionen“. Es erscheint ein Dropdown-Menü.
Klicken Sie auf „Neue Kachel hinzufügen”. Auf der rechten Seite erscheint ein Seitenbereich.
Klicken Sie auf die Option „Notebook-Ausgabe“.
Geben Sie einen Titel für die Dashboard-Kachel ein.
Wählen Sie das Pipeline-Objekt aus dem Work Organizer aus.
Passen Sie gegebenenfalls die Aktualisierungseinstellung an.
Klicken Sie auf „Neue Kachel hinzufügen”.
Anmerkung
Beim Freigeben einer DashHub-Kachel müssen auch die zugrunde liegenden Ansichten und Notebook-Pipeline-Objekte freigegeben werden.
Das Freigeben eines Notizbuchs führt zu einem symbolischen Link zum ursprünglichen Notizbuch. Das bedeutet, dass der Ersteller Eigentümer der Stammdaten des Notizbuchs bleibt. Änderungen an Zellen werden nach dem FIFO-Prinzip gespeichert und erst bei einer Bildschirmaktualisierung übernommen.
Die veröffentlichten Pipeline-Objekt-Ausgabeobjekte sind nicht mehr mit den ursprünglichen Notizbüchern verknüpft. Nach der Veröffentlichung wirken sich Änderungen am Notizbuch nicht mehr automatisch auf das vorhandene Notizbuch-Pipeline-Objekt aus. Auf diese Weise können Benutzer die Ausgaben der Notizbuchzellen optimieren, ohne dass dies Auswirkungen auf andere Benutzer/Betrachter hat.
Die Notebooks und Visualisierungen der Notebook-Ausgaben werden entsprechend Ihren Berechtigungen und Privilegien ausgeführt. Das bedeutet, dass einige Datenquellen möglicherweise blockiert sind und Sie nur Daten verarbeiten können, die Ihrer Rolle entsprechen.