Constructeur de Tag : Calculs personnalisés
Note
Cette fonctionnalité est disponible à partir de la version 2024.R1.1 de TrendMiner et nécessite une licence d'utilisateur expert.
L'option de calcul personnalisé dans le Generador etiquetas vous permet de créer de nouveaux tags TrendMiner basés sur un script Python développé sur mesure. Cela vous permet d'aller au-delà des capacités de manipulation de tags standard de TrendMiner et d'ouvrir des cas d'utilisation supplémentaires. Une fois créées, ces balises peuvent être affichées et analysées comme n'importe quelle autre balise dans TrendMiner. Les Calculs personnalisés se trouvent dans le menu du Generador de etiquetas. La fonctionnalité des Calculs personnalisés est marquée comme une fonctionnalité LAB, ce qui signifie qu'elle est en cours de développement actif et qu'elle pourrait être modifiée dans les nouvelles versions.
Avis
Cette fonction n'est disponible que si vous disposez de droits de gestion de l'accès aux Calculs personnalisés.
Cette première partie de l'article décrit le déroulement de la mise en place d'une balise de Calculs personnalisés et les exigences relatives aux scripts fournis. L'article décrit également les données qui seront utilisées pour tracer les données et les limitations propres aux calculs personnalisés.
Le flux de travail général du créateur de tags s'applique aux calculs personnalisés. Vous trouverez une vue d'ensemble de ces flux de travail ici. Les panneaux de configuration des tags de calcul personnalisé sont configurés différemment pour permettre des cycles d'itération faciles pendant le développement du script. Pour ce faire, un éditeur de code et un mode de prévisualisation dédiés sont disponibles.
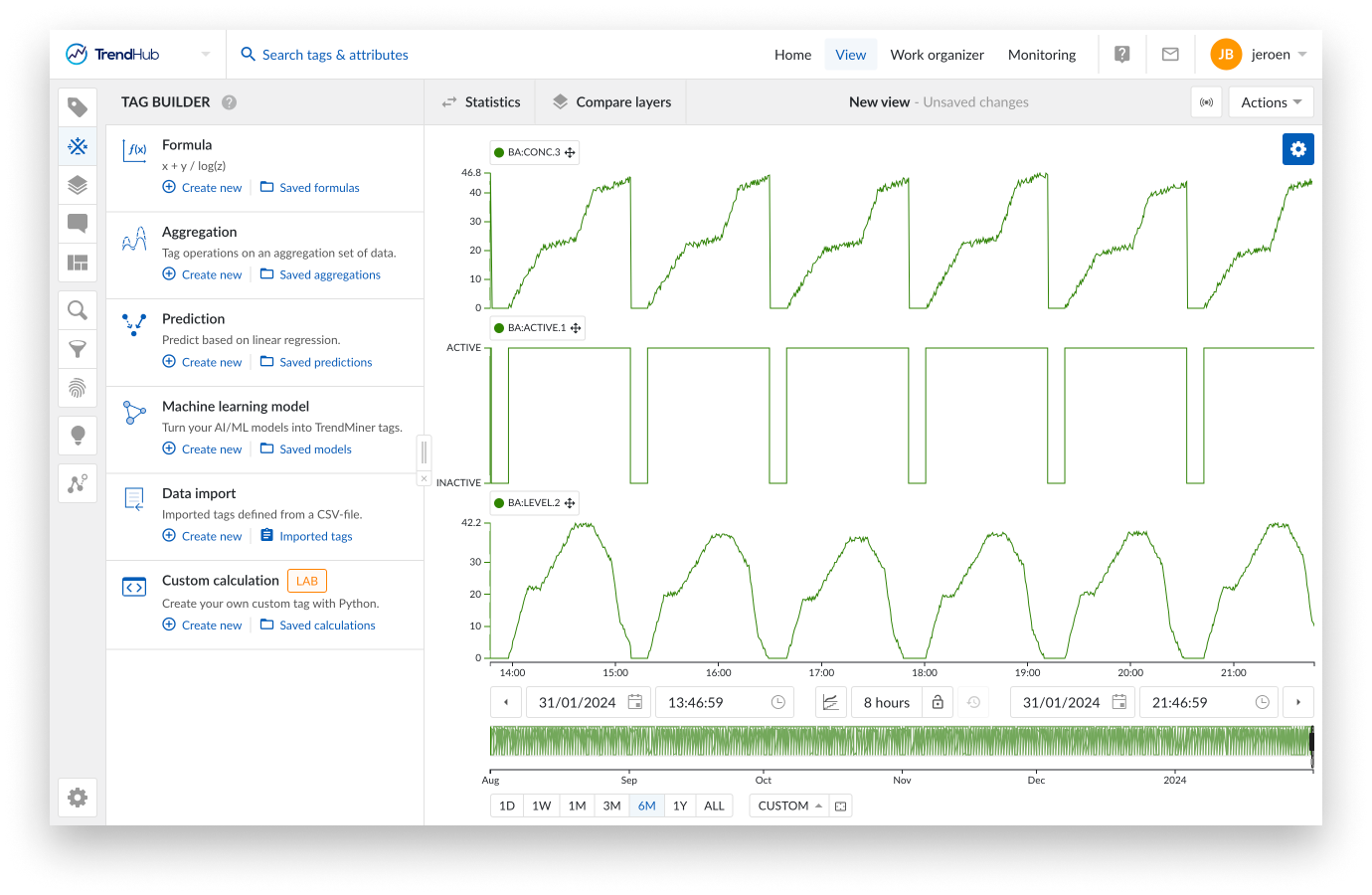
Panneau de développement de scripts
Lorsque vous entrez dans le menu de calcul personnalisé, le Graphique de focus est complètement remplacé par le panneau de développement de script, composé de 2 onglets :
Code
Prévisualisation
Votre script python personnalisé peut être copié ou créé à partir de zéro dans l'éditeur sur l'onglet code. La coloration syntaxique de Python est activée d'emblée pour améliorer la lisibilité. Veuillez vous référer à la section suivante pour apprendre comment un script doit être configuré pour produire un Tag TrendMiner utilisable. Le bouton "Run" sur le côté droit peut être utilisé pour exécuter le script actuel et ouvrira automatiquement l'onglet de prévisualisation. Bien que tout script sans sortie graphique puisse être exécuté, l'objectif principal de cette fonctionnalité est de créer un nouveau tag, et l'ensemble des horodatages et des valeurs doit donc être fourni. S'ils sont fournis, l'onglet de prévisualisation affichera un graphique du comportement du script du tag en fonction de l'heure de début et de fin appliquée dans les paramètres de prévisualisation.
Vous pouvez passer de l'onglet "code" à l'onglet "Prévisualisation". Le script ne sera exécuté que si vous cliquez sur Exécuter. Un horodatage est affiché dans l'onglet de prévisualisation pour indiquer quand le script a été exécuté pour la dernière fois.
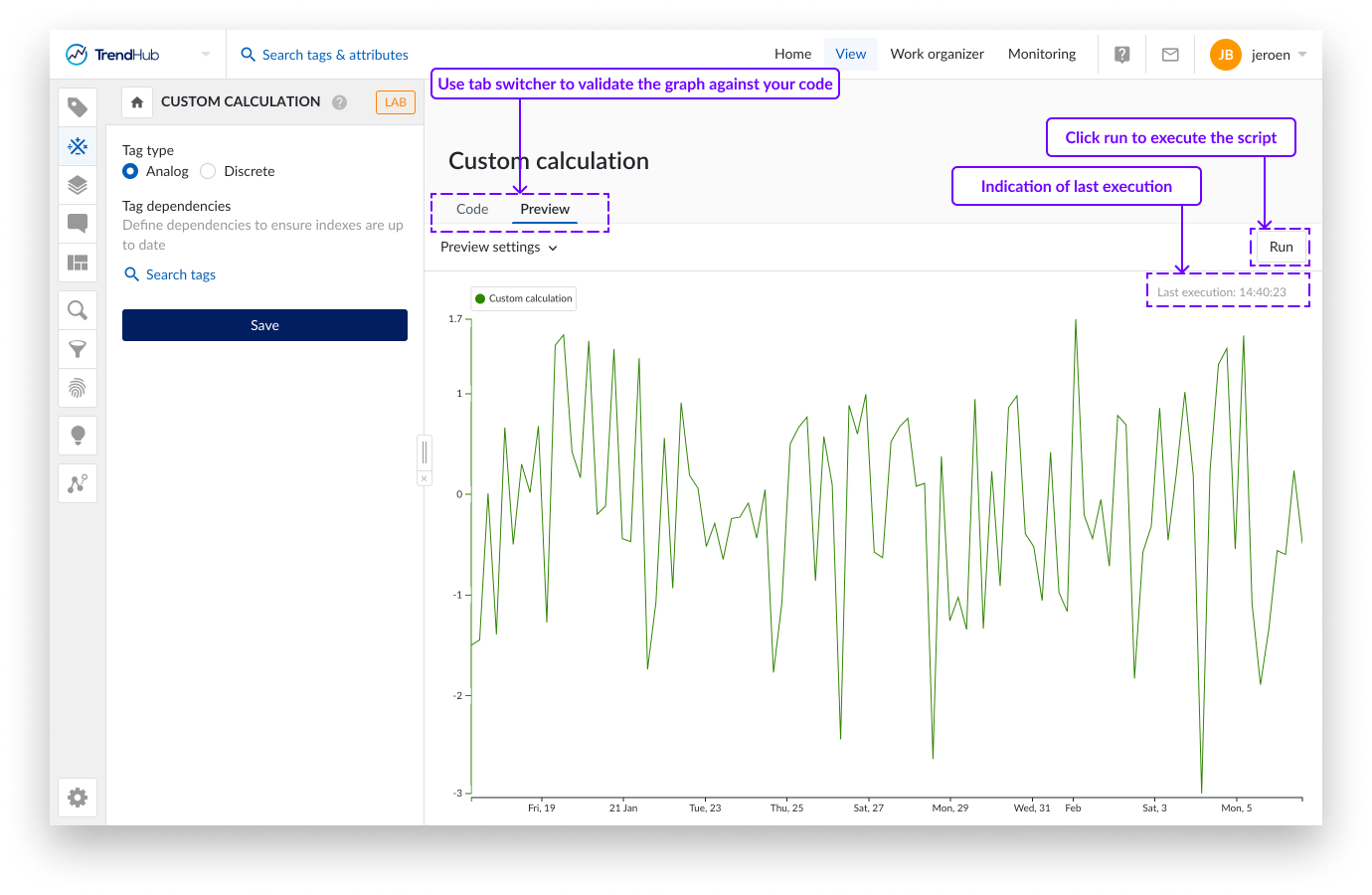
Par défaut, les paramètres de prévisualisation couvrent les 8 dernières heures. Les dates de début et de fin peuvent être modifiées pour tester une période d'intérêt personnalisée. La durée totale du mode de prévisualisation est toutefois limitée à 1 mois.
Des instructions d'impression peuvent être ajoutées au script pour faciliter le développement. Ces instructions d'impression, ainsi que les erreurs, seront affichées sous le graphique si elles sont applicables. Si aucune erreur n'est présente et qu'aucune instruction d'impression n'est utilisée, ces zones de texte seront omises.
Avis
Les paramètres de prévisualisation et l'indication de la dernière exécution sont fournis dans votre fuseau horaire local. Ces heures sont converties en UTC, qui seront utilisées dans le script et affichées dans les instructions d'impression.
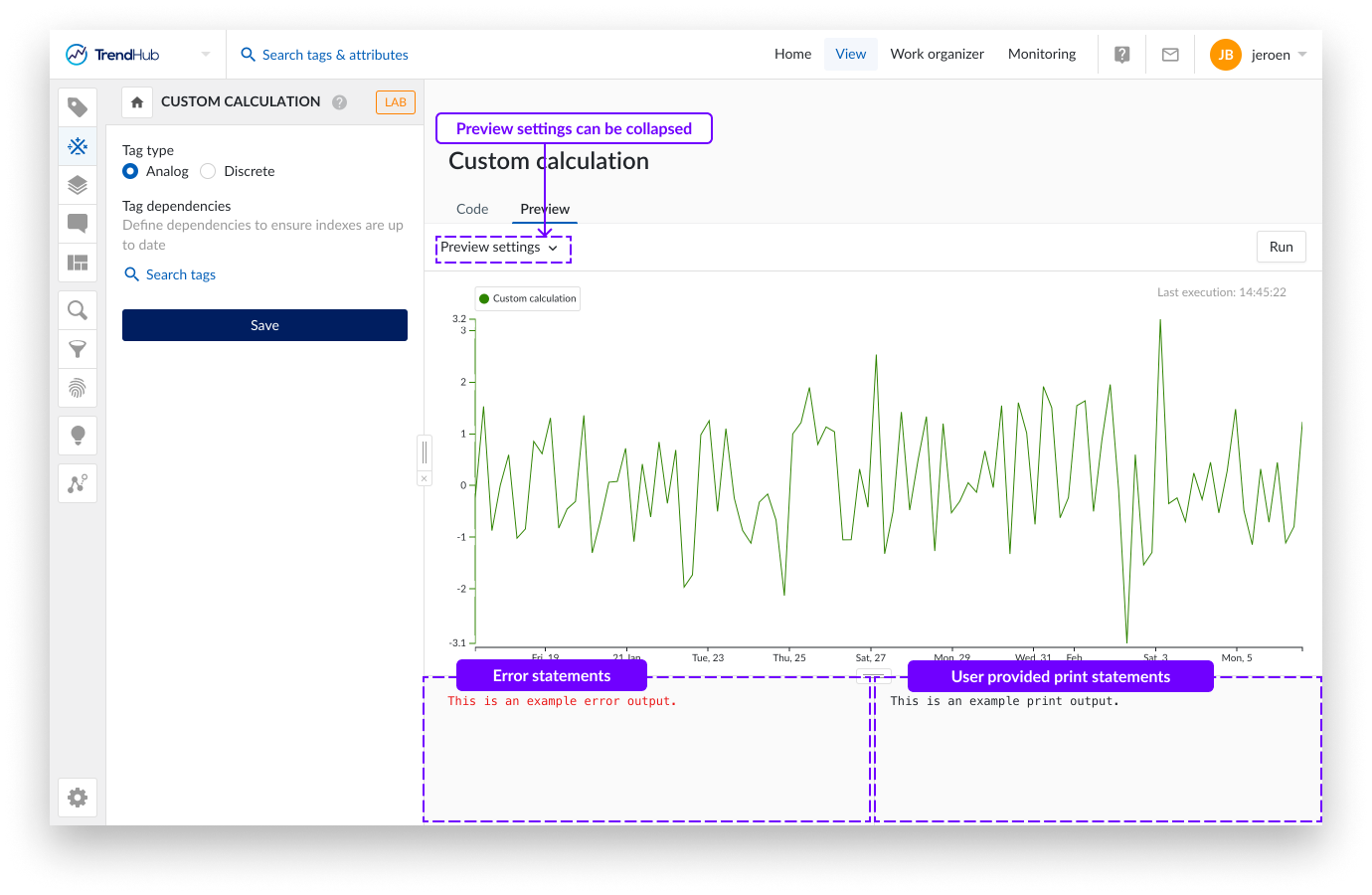
Configuration du Tag
Bien que le comportement principal du calcul personnalisé soit influencé par le script lui-même, deux configurations doivent être spécifiées dans le menu de gauche.
Type de Tag
Le type de tag détermine la manière dont les données fournies du tag seront interpolées. Les données seront interpolées linéairement (tag analogique) ou par échelons (tag discret). La possibilité d'enregistrer le tag en tant que chaîne ou tag digital n'est pas prise en charge actuellement.
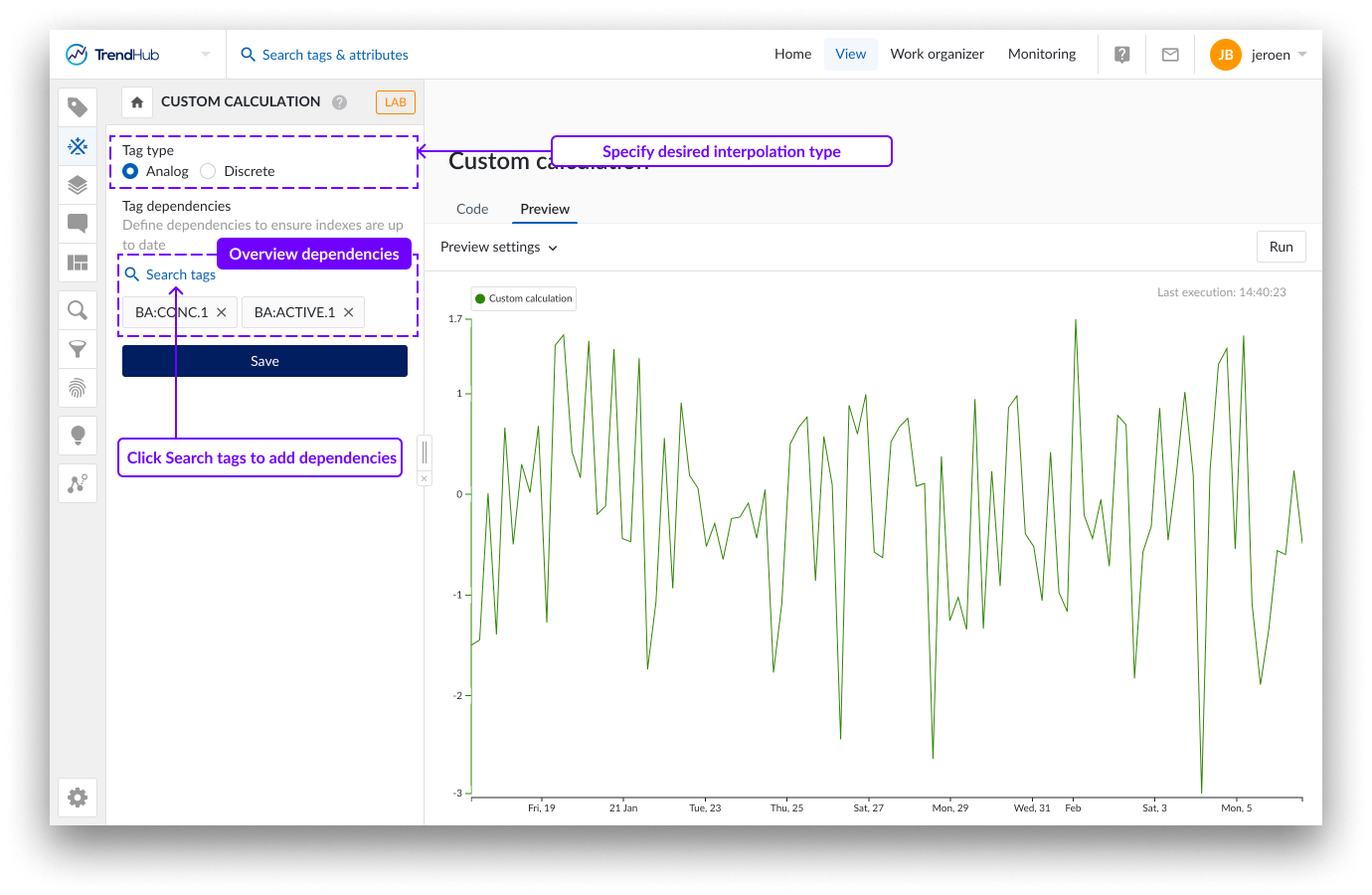
Dépendances des Tag
Dans la section dépendances des tags, vous devez sélectionner tous les tags auxquels votre script accède. Ceci est différent par rapport à tous les autres types de créateur de tags, où les dépendances sur les variables mappées sont automatiquement détectées dans le cadre du flux de création d'un tag. Avec les calculs personnalisés, TrendMiner ne peut pas déduire quels tags sont utilisées. Cette information est cruciale dans le cas où un calcul personnalisé est utilisé dans un Monitoring. Dans ce cas, TrendMiner doit s'assurer que l'index du calcul personnalisé ainsi que toutes les dépendances sont à jour. Le nombre maximum de dépendances pour un calcul personnalisé est fixé à 50.
Avertissement
Si les dépendances des tags ne sont pas fournies, les résultats du Monitoring seront retardés, voire ne seront pas déclenchés si les index des tags utilisées n'existent pas.
Exigences
Le script Python doit respecter un certain nombre d'exigences pour que la prévisualisation (et l'indexation) d'un calcul personnalisé fonctionne correctement.
Script minimum viable
Lors de la création d'un nouveau calcul personnalisé, un script de remplacement sera fourni dans l'éditeur. Il s'agit d'un exemple factice, contenant tous les éléments nécessaires à la création et à l'enregistrement corrects d'un Tag de calculs personnalisés. N'hésitez pas à expérimenter avec ce script pour comprendre comment fonctionne la création de séries temporelles.
import numpy as np
import pandas as pd
import os
# Parameter configuration
output_file = os.environ["OUTPUT_FILE"] # Where to write output table
start = os.environ["START_TIMESTAMP"] # Start datetime of range to compute values in
end = os.environ["END_TIMESTAMP"] # End datetime of range to compute values in
# Code to compute table
num_points = 100
pd.DataFrame(
{
"ts": pd.date_range(start, end, num_points),
"value": np.random.randn(num_points)
}
).to_csv(output_file, index=False) Sur la base de cet exemple fictif, les éléments suivants sont obligatoires :
Accès au fichier de sortie.
Accès à l'heure de début de la période pour laquelle le calcul (dans la prévisualisation et lors de l'indexation) sera effectué.
Accès à l'heure de fin de la période pour laquelle le calcul (dans la prévisualisation et lors de l'indexation) sera effectué.
Stockage des données de séries temporelles dans le fichier de sortie, qui est stocké sous la forme d'un fichier CSV :
le fichier doit contenir 2 colonnes
horodatage
valeurs
Outre ces éléments, la sortie générée doit également répondre aux exigences suivantes. Si ce n'est pas le cas, la prévisualisation et l'indexation du Tag échoueront.
Les données de sortie doivent se situer dans les plages de temps spécifiées (heure de début et de fin).
Les points en double, c'est-à-dire le même horodatage, ne sont pas autorisés.
Un maximum de 6 points de données par intervalle d'index est autorisé.
Le script doit pouvoir être exécuté en 2 minutes pour une période d'un mois.
Chaque script dispose de 512MB de RAM disponible. Le script doit pouvoir se terminer dans cette limite.
Avis
Avant d'enregistrer le Tag, il est conseillé de tester la prévisualisation sur 1 mois de données, puisque l'indexation en arrière sera exécutée par mois. Cela permet de s'assurer que l'indexation fonctionnera correctement.
Des messages d'erreur clairs apparaissent lors de l'exécution du script si les conditions requises ne sont pas remplies.
Extension du script minimum viable
Pour réaliser votre cas d'utilisation, vous pouvez étendre le script minimum viable en fonction de vos besoins. Un ensemble de paquets Python est disponible par défaut. Il n'est pas possible d'installer des paquets supplémentaires.
Formules disponibles
numpy
pandas
polars
pyarrow
python-dateutil
pytz
requests
scipy
En outre, SDK TrendMiner est disponible, ce qui vous permet d'extraire facilement des données TrendMiner, comme les données d'index des balises.
Pour obtenir une vue d'ensemble actualisée des packages disponibles et de leur version, vous pouvez inclure l'extrait de code suivant dans votre script :
import importlib.metadata
installed_packages = importlib.metadata.distributions()
for package in installed_packages:
print(package.metadata["Name"], package.version)Avis
N'hésitez pas à contacter votre Customer Success Manager ou votre ingénieur Data Analytics TrendMiner pour vous aider à créer des calculs plus avancés, ou à vous référer au TrendMiner GitHub pour accéder à des exemples de codes pour divers cas d'utilisation.
Indexation des tags de calculs personnalisés
Afin de configurer correctement un script de calcul personnalisé, il est important de comprendre comment ces Tag seront indexés. Pour en savoir plus sur l'indexation elle-même, veuillez consulter cet article.
Dès que le Tag de calcul personnalisé est sauvegardé, il commence à être indexé. Dans un premier temps, le processus d'indexation effectuera un backfill historique (c'est-à-dire une indexation en arrière). Pour ce faire, le script est exécuté chaque mois. Les paramètres START_TIMESTAMP et END_TIMESTAMP de votre script correspondront toujours au début et à la fin d'un mois au cours de ce processus. Les tags indexés seront automatiquement mis à jour (c'est-à-dire l'indexation en avant). Par défaut, une vérification des nouvelles données est effectuée toutes les heures. Si votre Tag est utilisé dans un Monitoring, cette vérification sera effectuée toutes les 2 minutes. Dans ce cas, START_TIMESTAMP et END_TIMESTAMP correspondent respectivement à l'horodatage du dernier point d'index enregistré et à l'instant présent. Bien que TrendMiner recherche de nouvelles données toutes les heures (ou 2 minutes), la période réelle d'exécution des scripts peut être plus longue, en fonction de l'endroit où le dernier point de données a été stocké.
Mode de prévisualisation
Le mode de prévisualisation affiche tous les points de données tels qu'ils sont renvoyés par les scripts, en tenant compte des restrictions mentionnées ci-dessus. Toutefois, dès que plus de 10 000 points de données sont renvoyés, le nombre de points de données est réduit.
Graphique de focus
Avis
Le graphique en mode prévisualisation et le graphique focus basé sur le calcul personnalisé enregistré peuvent être légèrement différents lors de la visualisation d'un mois de données, étant donné qu'un algorithme d'échantillonnage différent est appliqué.
De même, pour les petites fenêtres, le graphique de focus sera rendu sur la base des données indexées stockées (maximum 6 points de données par intervalle d'index).
Avis
De même, pour les petites fenêtres, le graphique de focus sera rendu sur la base des données indexées stockées (maximum 6 points de données par intervalle d'index).
Les limitations générales mentionnées dans le document de présentation du Créateur de tags sont applicables aux calculs personnalisés. Les limitations spécifiques aux calculs personnalisés sont les suivantes :
Le nombre de calculs personnalisés enregistrés est limité à 120 par instance de TrendMiner.
Pendant l'indexation, tous les scripts sont exécutés dans l'ordre. Si plusieurs tags de calcul personnalisés sont utilisés dans un moniteur et que les scripts ont un long temps d'exécution, il faut s'attendre à un délai supplémentaire dans les résultats du monitoring.