Tag Builder: Benutzerdefinierte Berechnungen
Anmerkung
Diese Funktion ist ab TrendMiner Version 2024.R1.1 verfügbar und erfordert eine Expertenlizenz.
Die Option für benutzerdefinierte Berechnungen im Tag builder ermöglicht es Ihnen, neue TrendMiner-Tags auf der Grundlage eines selbst entwickelten Python-Skripts zu erstellen. Damit können Sie über die Standard-Tag-Manipulationsmöglichkeiten von TrendMiner hinausgehen und zusätzliche Anwendungsfälle erschließen. Einmal erstellt, können diese Tags wie jedes andere Tag in TrendMiner angezeigt und analysiert werden. Die benutzerdefinierten Berechnungen finden Sie im Menü des Tag builders. Die Funktion für benutzerdefinierte Berechnungen ist als LAB-Funktion gekennzeichnet, was bedeutet, dass sich die Funktion noch in der aktiven Entwicklung befindet und sich in neueren Versionen ändern kann.
Hinweis
Diese Funktion ist nur verfügbar, wenn Sie Zugriffsrechte für die Verwaltung der benutzerdefinierten Berechnungen haben.
Dieser erste Teil des Artikels beschreibt den Ablauf der Einrichtung eines Tags für benutzerdefinierte Berechnungen und die Anforderungen an die bereitgestellten Skripts. Der Artikel beschreibt auch, welche Daten für die Darstellung der Daten verwendet werden und welche Einschränkungen für benutzerdefinierte Berechnungen gelten.
Der allgemeine Arbeitsablauf von Tag Builder-Tags gilt für benutzerdefinierte Berechnungen. Einen Überblick über diese Arbeitsabläufe finden Sie hier. Die Konfigurationsfelder von Tags für benutzerdefinierte Berechnungen sind anders aufgebaut, um einfache Iterationszyklen während der Entwicklung des Skripts zu ermöglichen. Dies wird durch die Bereitstellung eines speziellen Code-Editors und eines Vorschaumodus erreicht.
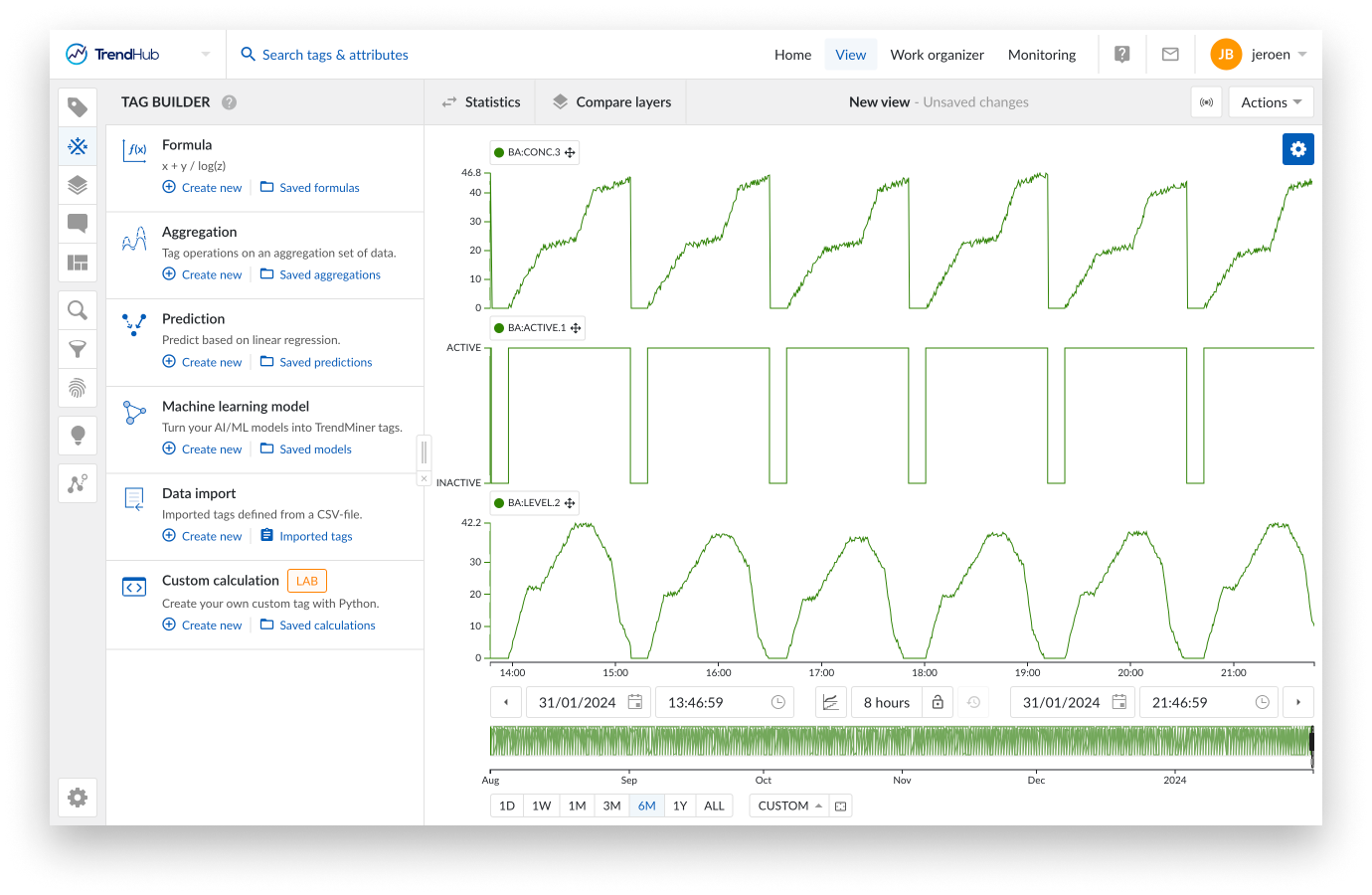
Bedienfeld für die Skriptentwicklung
Wenn Sie das Menü für benutzerdefinierte Berechnungen aufrufen, wird das Fokusdiagramm vollständig durch das Skriptentwicklungsfenster ersetzt, das aus 2 Registerkarten besteht:
Code
Vorschau
Ihr benutzerdefiniertes Python-Skript kann im Editor auf der Registerkarte Code kopiert oder von Grund auf neu erstellt werden. Die Syntaxhervorhebung in Python ist standardmäßig aktiviert, um die Lesbarkeit zu erhöhen. Im nächsten Abschnitt erfahren Sie, wie ein Skript aufgebaut sein sollte, um einen brauchbaren TrendMiner-Tag zu erzeugen. Mit der Schaltfläche Ausführen auf der rechten Seite können Sie das aktuelle Skript ausführen und öffnen automatisch die Registerkarte Vorschau. Obwohl jedes Skript ohne grafische Ausgabe ausgeführt werden kann, besteht das Hauptziel dieser Funktion darin, einen neuen Tag zu erstellen, und daher sollten die Zeitstempel und Werte angegeben werden. Wenn Sie diese angeben, wird auf der Registerkarte Vorschau ein Diagramm des skriptgesteuerten Verhaltens des Tags auf der Grundlage der in den Vorschaueinstellungen angegebenen Start- und Endzeit angezeigt.
Sie können zwischen dem Code und der Registerkarte Vorschau wechseln. Das Skript wird nur ausgeführt, wenn Sie auf Ausführen klicken. Auf der Registerkarte Vorschau wird ein Zeitstempel angezeigt, der angibt, wann das Skript zuletzt ausgeführt wurde.
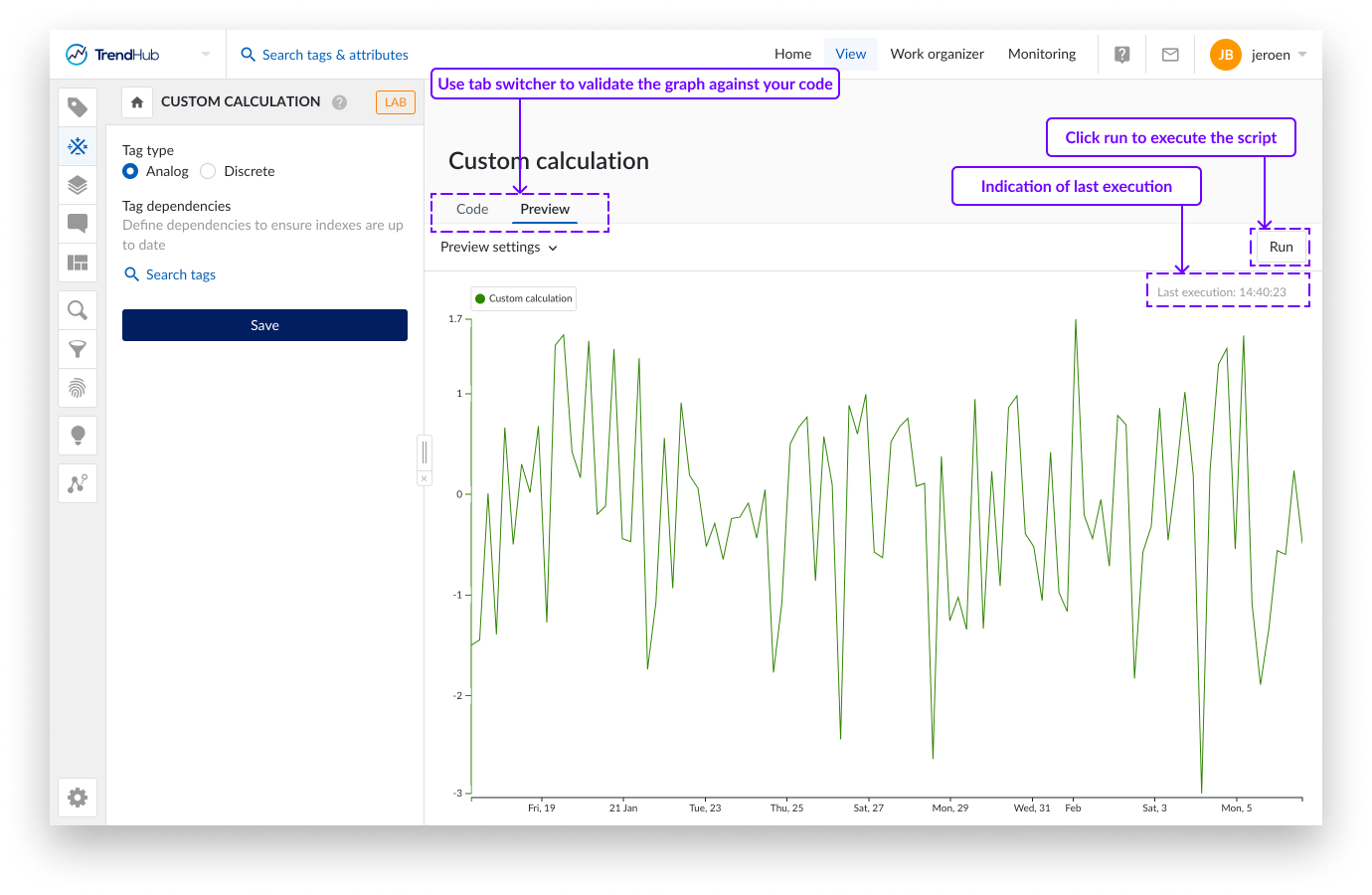
Die Standardeinstellungen für die Vorschau umfassen die letzten 8 Stunden. Die Start- und Enddaten können geändert werden, um einen benutzerdefinierten Zeitraum von Interesse zu testen. Die Gesamtzeitspanne des Vorschaumodus ist jedoch auf 1 Monat begrenzt.
Um die Entwicklung zu erleichtern, können Sie dem Skript Druckanweisungen hinzufügen. Diese Druckanweisungen sowie Fehler werden unterhalb des Diagramms angezeigt, wenn sie zutreffend sind. Liegen keine Fehler vor und werden keine Druckanweisungen verwendet, werden diese Textfelder nicht angezeigt.
Hinweis
Die Vorschaueinstellungen und die Anzeige der letzten Ausführung werden in Ihrer lokalen Zeitzone angegeben. Diese Zeiten werden in UTC konvertiert, was im Skript verwendet und in den Druckanweisungen angezeigt wird.
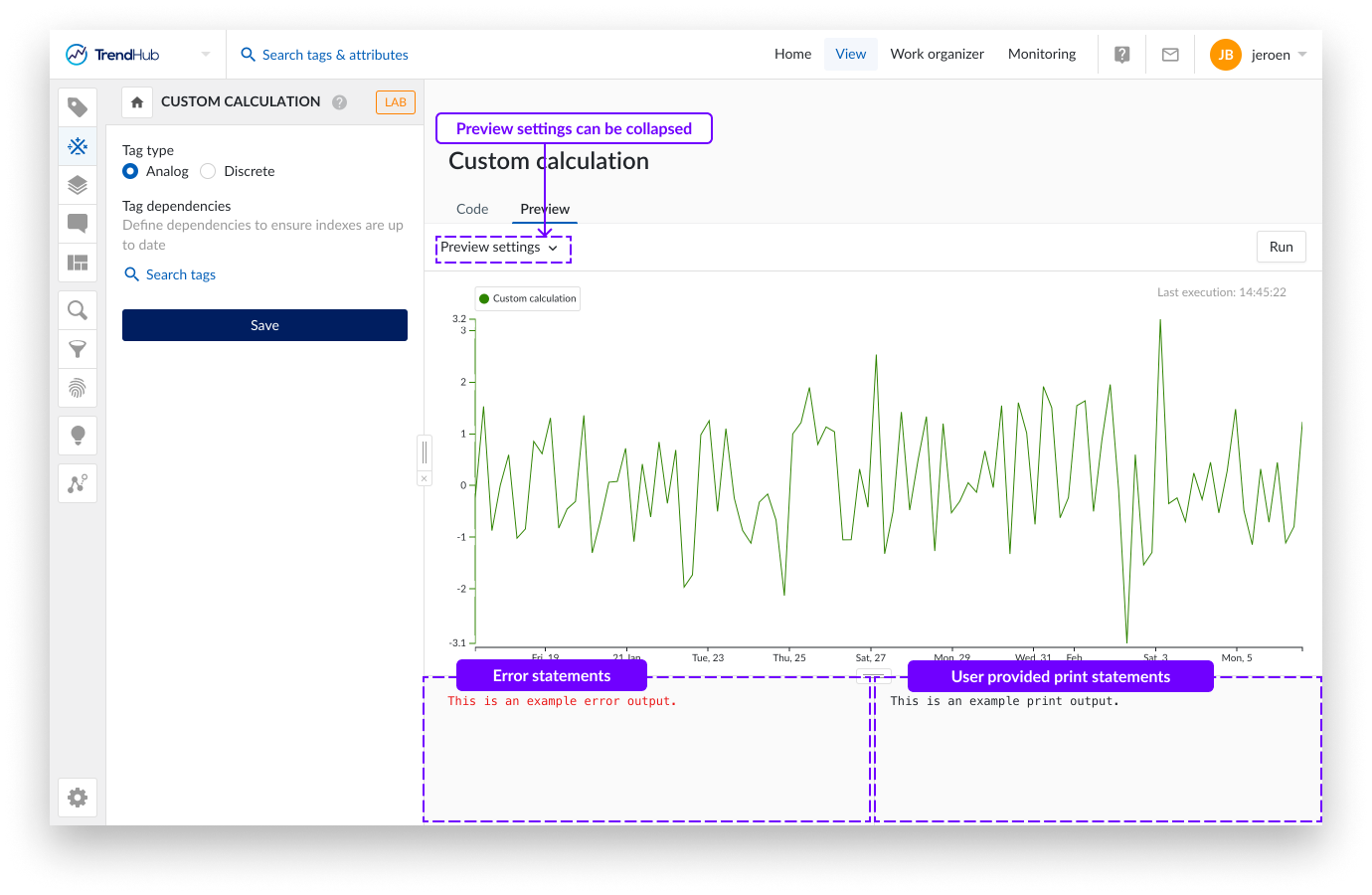
Tag-Konfiguration
Obwohl das Hauptverhalten der benutzerdefinierten Berechnung durch das Skript selbst beeinflusst wird, gibt es 2 Konfigurationen, die im linken Menü angegeben werden müssen.
Tag-Typ
Der Tag-Typ bestimmt, wie die Daten des Tags interpoliert werden. Die Daten werden linear (analoger Tag) oder schrittweise (diskreter Tag) interpoliert. Die Möglichkeit, den Tag als String oder digitalen Tag zu speichern, wird derzeit nicht unterstützt.
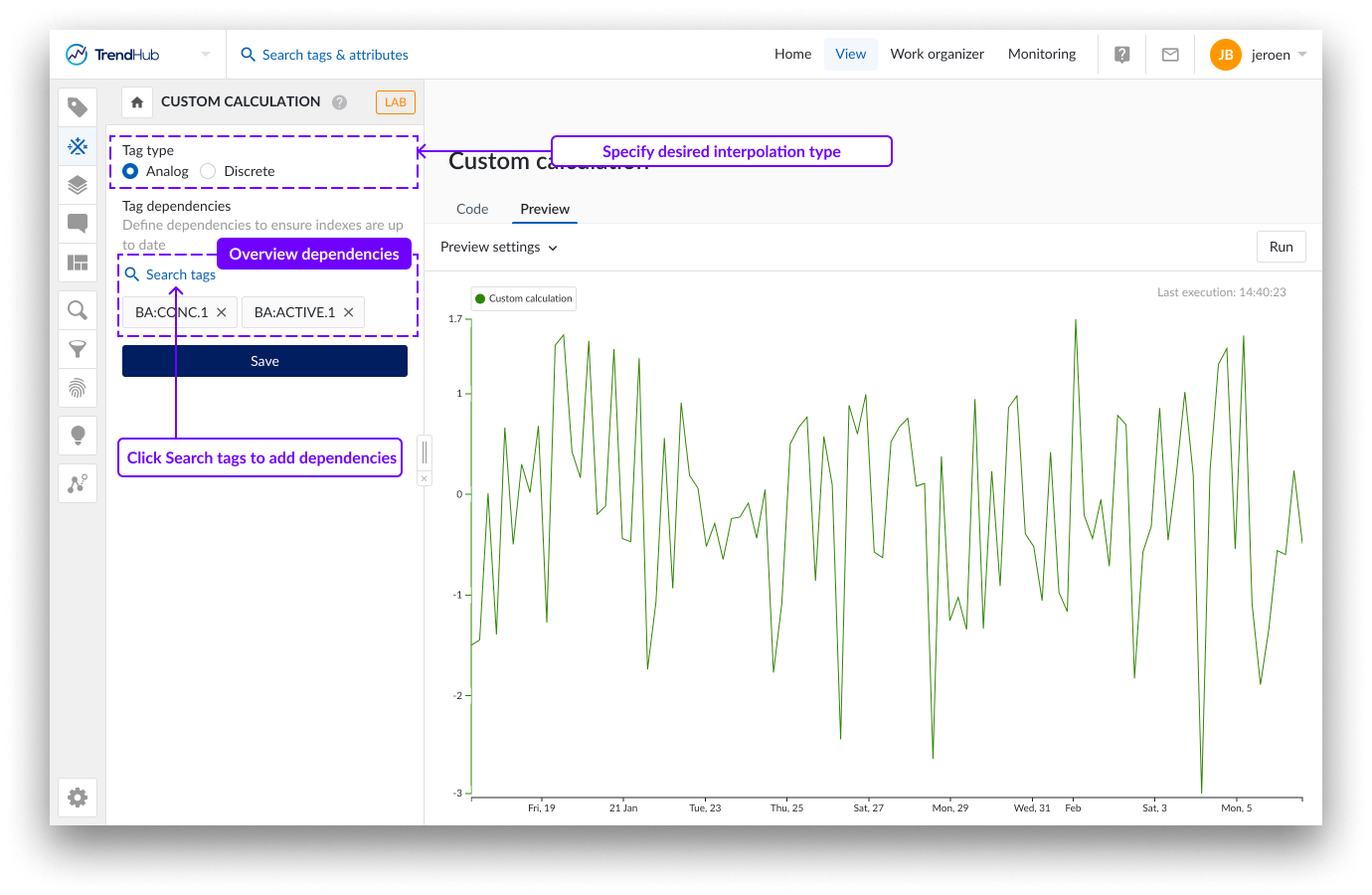
Tag-Abhängigkeiten
Im Bereich Tag-Abhängigkeiten sollten Sie alle Tags auswählen, auf die in Ihrem Skript zugegriffen wird. Dies ist ein Unterschied zu allen anderen Tag Builder-Typen, bei denen die Abhängigkeiten von zugeordneten Variablen automatisch als Teil des Erstellungsprozesses eines Tags erkannt werden. Bei benutzerdefinierten Berechnungen kann TrendMiner nicht ableiten, welche Tags verwendet werden. Diese Information ist wichtig, wenn eine benutzerdefinierte Berechnung in einem Monitor verwendet wird. In diesem Fall muss TrendMiner sicherstellen, dass der Index der benutzerdefinierten Berechnung sowie alle Abhängigkeiten auf dem neuesten Stand sind. Die maximale Anzahl von Abhängigkeiten für benutzerdefinierte Berechnungen ist auf 50 festgelegt.
Warnung
Wenn keine Tag-Abhängigkeiten angegeben werden, werden die Monitor-Ergebnisse verzögert oder möglicherweise nicht ausgelöst, wenn die Indizes der verwendeten Tags nicht existieren.
Anforderungen
Das Python-Skript muss einige Anforderungen erfüllen, damit die Vorschau (und die Indexierung) einer benutzerdefinierten Berechnung korrekt funktioniert.
Mindestanforderungen an das Skript
Wenn Sie eine neue benutzerdefinierte Berechnung erstellen, wird im Editor ein Platzhalter-Skript bereitgestellt. Dabei handelt es sich um ein Dummy-Beispiel, das alle notwendigen Elemente enthält, um einen Tag für benutzerdefinierte Berechnungen korrekt zu erstellen und zu speichern. Sie können gerne mit diesem Skript experimentieren, um zu verstehen, wie die Erstellung von Zeitreihen funktioniert.
import numpy as np
import pandas as pd
import os
# Parameter configuration
output_file = os.environ["OUTPUT_FILE"] # Where to write output table
start = os.environ["START_TIMESTAMP"] # Start datetime of range to compute values in
end = os.environ["END_TIMESTAMP"] # End datetime of range to compute values in
# Code to compute table
num_points = 100
pd.DataFrame(
{
"ts": pd.date_range(start, end, num_points),
"value": np.random.randn(num_points)
}
).to_csv(output_file, index=False) Ausgehend von diesem Dummy-Beispiel sind die folgenden Elemente obligatorisch:
Zugriff auf die Ausgabedatei.
Zugriff auf die Startzeit des Zeitraums, für den die Berechnung (sowohl in der Vorschau als auch bei der Indizierung) durchgeführt wird.
Zugriff auf die Endzeit des Zeitraums, für den die Berechnung (sowohl in der Vorschau als auch bei der Indizierung) durchgeführt wird.
Speichern von Zeitreihendaten in der Ausgabedatei, die als CSV-Datei gespeichert wird:
die Datei sollte 2 Spalten enthalten
Zeitstempel
Werte
Neben diesen Elementen muss die generierte Ausgabe auch die folgenden Anforderungen erfüllen. Wenn dies nicht der Fall ist, schlägt sowohl die Vorschau als auch die Indexierung des Tags fehl.
Die Ausgabedaten müssen innerhalb der angegebenen Zeitspannen liegen (angegebene Start- und Endzeit) .
Doppelte Punkte, d.h. mit demselben Zeitstempel, sind nicht erlaubt.
Es sind maximal 6 Datenpunkte pro Indexintervall erlaubt.
Das Skript sollte innerhalb von 2 Minuten für einen Zeitraum von 1 Monat abgeschlossen werden können.
Jedes Skript hat 512 MB RAM zur Verfügung. Das Skript sollte innerhalb dieses Rahmens fertiggestellt werden können.
Hinweis
Bevor Sie den Tag speichern, sollten Sie die Vorschau mit den Daten eines Monats testen, da die rückwärts gerichtete Indizierung pro Monat durchgeführt wird. So haben Sie die Gewissheit, dass die Indizierung korrekt funktioniert.
Bei der Ausführung des Skripts erscheinen eindeutige Fehlermeldungen, wenn die Anforderungen nicht erfüllt sind.
Erweiterung der Mindestanforderungen an das Skript
Um Ihren Anwendungsfall fertigzustellen, können Sie die Mindestanforderungen an das Skript nach Ihren Bedürfnissen erweitern. Eine Reihe von Python-Paketen ist standardmäßig verfügbar. Zusätzliche Pakete können nicht installiert werden.
Verfügbare Pakete
numpy
pandas
polars
pyarrow
python-dateutil
pytz
requests
scipy
Zusätzlich, TrendMiner SDK ist verfügbar, wodurch Sie TrendMiner-Daten, wie etwa Indexdaten von Tags, problemlos einbinden können.
Um einen aktuellen Überblick über die verfügbaren Pakete und ihre Version zu erhalten, können Sie den folgenden Codeausschnitt in Ihr Skript einfügen:
import importlib.metadata
installed_packages = importlib.metadata.distributions()
for package in installed_packages:
print(package.metadata["Name"], package.version)Hinweis
Wenden Sie sich gerne an Ihren TrendMiner Customer Success Manager oder Data Analytics Engineer, um Hilfe bei der Erstellung komplexerer Berechnungen zu erhalten, oder lesen Sie die TrendMiner GitHub um auf Beispielcodes für verschiedene Anwendungsfälle zuzugreifen.
Indizierung von Tags für benutzerdefinierte Berechnungen
Um ein benutzerdefiniertes Berechnungsskript korrekt einzurichten, ist es wichtig zu verstehen, wie diese Tags indiziert werden. Wenn Sie mehr über die Indizierung selbst erfahren möchten, lesen Sie bitte diesen Artikel.
Sobald der benutzerdefinierte Berechnungs-Tag gespeichert ist, beginnt die Indizierung des Tags. Zunächst wird bei der Indizierung ein historischer Backfill (d.h. eine Rückwärtsindizierung) durchgeführt. Dies geschieht, indem das Skript jeden Monat ausgeführt wird. Die Parameter START_TIMESTAMP und END_TIMESTAMP in Ihrem Skript sind während dieses Prozesses immer die Start- und Endzeit eines Monats. Indizierte Tags werden automatisch auf dem neuesten Stand gehalten (d.h. Vorwärtsindizierung). Standardmäßig wird jede Stunde geprüft, ob neue Daten vorhanden sind. Falls Ihr Tag in einem Monitor verwendet wird, geschieht dies alle 2 Minuten. START_TIMESTAMP und END_TIMESTAMP sind in diesem Fall der Zeitstempel des letzten gespeicherten Indexpunkts bzw. des aktuellen Zeitpunkts. Obwohl TrendMiner jede Stunde (oder 2 Minuten) nach neuen Daten sucht, kann der tatsächliche Zeitraum, in dem die Skripte ausgeführt werden, länger sein, je nachdem, wo der letzte Datenpunkt gespeichert wurde.
Vorschau-Modus
Im Vorschaumodus werden alle Datenpunkte angezeigt, die von den Skripten zurückgegeben werden, wobei die oben genannten Einschränkungen berücksichtigt werden. Sobald jedoch mehr als 10.000 Datenpunkte zurückgegeben werden, wird die Anzahl der Datenpunkte heruntergerechnet.
Fokusdiagramm
Hinweis
Die Darstellung im Vorschaumodus und das Fokusdiagramm, das auf der gespeicherten benutzerdefinierten Berechnung basiert, können bei der Visualisierung von 1 Monat Daten leicht unterschiedlich aussehen, da ein anderer Sampling-Algorithmus angewendet wird.
Auch bei kleinen Fenstern wird das Fokusdiagramm auf der Grundlage der gespeicherten indizierten Daten (maximal 6 Datenpunkte pro Indexintervall) wiedergegeben.
Hinweis
Auch bei kleinen Fenstern wird das Fokusdiagramm auf der Grundlage der gespeicherten indizierten Daten (maximal 6 Datenpunkte pro Indexintervall) wiedergegeben.
Für benutzerdefinierte Berechnungen gelten die allgemeinen Einschränkungen, die im Übersichtsdokument des Tag Builders aufgeführt sind. Zu den spezifischen Einschränkungen für benutzerdefinierte Berechnungen gehören:
Die Anzahl der gespeicherten benutzerdefinierten Berechnungen ist auf 120 pro TrendMiner-Instanz begrenzt.
Während der Indizierung werden alle Skripts nacheinander ausgeführt. Wenn mehrere benutzerdefinierte Berechnungs-Tags in einem Monitor verwendet werden und die Skripts eine lange Ausführungszeit haben, ist eine zusätzliche Verzögerung bei den Monitoring-Ergebnissen zu erwarten.